انجمن را در گوگل محبوب کنيد :
|
|||||||


| تبليغات سايت | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  |
|
|
LinkBack | ابزارهاي تاپيک | نحوه نمايش |




 ۰۶-۱۴-۱۳۸۹, ۱۱:۰۲ قبل از ظهر
۰۶-۱۴-۱۳۸۹, ۱۱:۰۲ قبل از ظهر
|
#3 (لینک دائم) |
|
Administrator
 
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:

 |
يک راه موثر جهت تنظيمات اوليه در شبکه عصبی SOM
مقدمه: مدل کوهنن يک مدل بدون ناظر است و در SOM از اين مدل استفاده مي شود. در اين مدل تعدادي سلول عصبي که معمولادر يک توپولوژي مسطح کنار يکديگر چيده مي شوند، با رفتار متقابل روي يکديگر وظيفه شبکه خودسازمانده را ايفا مي کنند. اين وظيفه تخمين يک تابع توزيع است. يکي از اهداف اصلي SOM اين است که الگوها را از يک فضاي n بعدي (n>2 ) به يک فضاي يک يا دو بعدي تصوير کند . همانطور که مي دانيم تنظيمات اوليه به شدت روي نگاشت نهايي تاثير مي گذارد . به اين منظور از الگوريتم زير استفاده مي کنيم . گام اول : مقدار دهي اوليه نرونهاي واقع در چهارگوشه شبکه SOM در ابتدا يک جفت الگوي ورودي را که از بين ديگر الگوها بزرگتر است را پيدا مي کنيم .وزن نرونهاي واقع در گوشه پايين سمت چپ و گوشه بالا سمت راست را متناسب با اين زوج الگوي ورودي قرار مي دهيم . از بين ديگر الگوهاي ورودي ، الگويي را که از اين دو الگوي ورودي دورتر است را انتخاب مي کنيم و آن را در گوشه بالا سمت چپ قرار مي دهيم و الگوي ورودي را که از اين سه تا دورتر است را در گوشه پايين سمت راست قرار مي دهيم . گام دوم : مقدار دهي اوليه نرونهاي واقع در چهار لبه شبکه با استفاده از معادلات زير وزن نرونهاي واقع در چهارلبه بدست مي آيد:  گام سوم : مقدار دهي بقيه نرونها بقيه نرونها را از بالا به پايين و از چپ به راست مطابق الگوريتم زير مقدار دهي مي کنيم :  |

|

|
|
۰۶-۱۴-۱۳۸۹, ۱۱:۰۶ قبل از ظهر
|
#4 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
مقدمه
درشبکه ی خودسازمان ده، از روش یادگیری رقابتی برای آموزش استفاده می شود و مبتنی بر مشخصه های خاصی از مغز انسان توسعه یافته است. سلولها در مغز انسان در نواحی مختلف طوری سازمان دهی شده اند که در نواحی حسی مختلف، با نقشه های محاسباتی مرتب و معنی دار ارائه می شوند. برای نمونه، ورودیهای حسی لامسه –شنوائی و ... با یک ترتیب هندسی معنی دار به نواحی مختلف مرتبط هستند. در یک شبکه ی خود سازمان ده که با SOM(Self Organization Map) یا برخی مواقع به صورت SOFM(Self Organization Feature Map) نشان داده می شود، واحد های پردازش گر در گره های یک شبکه ی یک بعدی، دو بعدی یا بیشتر قرار داده می شوند. واحد ها در یک فرآیند یادگیری رقابتی نسبت به الگوهای ورودی منظم می شوند. محل واحدهای تنظیم شده در شبکه به گونه ای نظم می یابد که برای ویژگیهای ورودی، یک دستگاه مختصات معنی دار روی شبکه ایجاد شود. لذا یک نقشه ی خود سازمان ده، یک نقشه ی توپوگرافیک از الگوهای ورودی را تشکیل می دهد که در آن، محل قرار گرفتن واحدها، متناظر ویژگیهای ذاتی الگوهای ورودی است. یادگیری رقابتی که در این قیبل شبکه ها بکار گرفته می شود بدین صورت است که در هر قدم یادگیری، واحدها برای فعال شدن با یکدیگر به رقابت می پردازند، در پایان یک مرحله رقابت تنها یک واحد برنده می شود، که وزنهای آن نسبت به وزنهای سایر واحدها به شکل متفاوتی تغییر داده می شود. این نوع از یادگیری را یادگیری بی نظارت (Unsupervised) می نامند. شبکه های خودسازمان ده به لحاظ ساختاری به چند دسته تقسیم می شوند که در ادامه با هر یک از آنها به صورت مختصری آشنا می شویم. 1) شبکه های خودسازمانده دارای وزن ثابت: در این دسته از شبکه ها وزن اتصالات بر اساس اهداف مورد نظر در طراحی شبکه در حین طراحی مشخص می شود و مقدار آنها تغییر نمی یابد، یا به عبارت دیگر نیاز به مرحله ی آموزش ندارند در ادامه جهت آشنایی بیشتر با این گونه از شبکه ها با چند نمونه ی عملی آنها آشنا می شویم. 1-1) شبکه ی ماکس نت(MaxNet) مقدمه شبکه فوق در سال 1987 توسط لیپ من (Lippman) معرفی گردید. هدف استفاده از آن تعیین بزرگترین ورودی به شبکه است یعنی در این شبکه پس از طی چند مرحله از طریق خروجی ها می توان ورودی بزرگتر را تشخیص داد، از این شبکه به عنوان زیر شبکه نیز می توان در ترکیب با شبکه های دیگر استفاده نمود(در ادامه نمونه ای از این ترکیب ارائه می شود).  مدل ساختاری شبکه ی MaxNet ساختارشبکه در این شبکه، n واحد ورودی دارای اتصالات کامل و متقارن با وزن های ثابت هستند. تابع فعالیت آنها به صورت ذیل می باشد:  الگوریتم کار شبکه 0- مقادیر اولیه را مشخص می کنیم، مقداری برای e در فاصله ی  اختیار می کنیم، مقادیر اولیه ی فعالیتها(yها) را برابر ورودی ها قرار می دهیم، وزن ها را به فرم ذیل تعیین می کنیم: اختیار می کنیم، مقادیر اولیه ی فعالیتها(yها) را برابر ورودی ها قرار می دهیم، وزن ها را به فرم ذیل تعیین می کنیم: 1- تا زمانیکه شرط خاتمه ارضاء نشده است قدمهای 2 الی 4 را تکرار می کنیم 2- بهنگام سازی مقادیر فعالیت , j=1,...,m  3- مقادیر فعالیت ذخیره شود: yjold=yjnew , j=1,...,m 4- اگر بیش از یک واحد مقدار فعالیت غیر صفر دارد الگوریتم ادامه می یابد، در غیر این صورت الگوریتم خاتمه می یابد. 1-2) شبکه ی کلاه مکزیکی(Mexican Hat Network) مقدمه این شبکه در سال 1989 توسط کوهونن ارائه شد. هدف از بکار بردن این شبکه، افزایش تمایز بین ورودی ها می باشد، در این شبکه هر واحد با وزن های مثبت به همسایه های همکار و با وزن های منفی به همسایه های رقیب واقع در لایه خود وصل می شود.  ساختار شبکه در شبکه ی فوق هر نورون i با R1 نورون دیگر که در هر دو طرف نورون i به صورت متقارن قرار دارند تشکیل همسایگی همکار می دهد و با R2-R1 نورون متقارن در دو طرف خود همسایگی رقیب تشکیل می دهد. R1 را همسایگی همکار و R2 را کل همسایگی متصل می نامند. برای نمونه در شکل فوق یک شبکه ی کلاه مکزیکی با R1=1 و R2=2 نشان داده شده است. تخصیص وزن ها نیز بدین گونه است که در همسایگی همکار وزن ها مقادیر مثبت دارند ولی در همسایگی رقیب وزن ها مقادیر منفی دارا می باشند، در ضمن وزن های متقارن متصل به هر واحد i با هم مساوی هستند به عبارت دیگر وزن اتصال واحد i+1 و i-1 به واحد i با هم برابر هستند. در ذیل به جزئیات تخصیص وزن ها و توابع فعالیت اشاره می شود. وزن اتصالات وارد به واحد i که به فرم wi+k,i می باشد بدین گونه است که: الف) برای واحدهای همکار |k|≤R1 ، وزن های مثبت ب) برای واحدهای رقیب R1≤|k|≤R2 ،وزن های منفی تابع فعالیت هر واحد در زمان t به فرم ذیل است:  الگوریتم کار شبکه 0- تعیین مقادیر اولیه ی پارامتر های R1، R2 ، tmax و  yold=0 , 1- سیگنال خارجی را اعمال و مقادیر yold را ذخیره می کنیم y=x , yiold=xi ,i=1,...,n 2- تا زمانیکه t<tmax قدم های 3 الی 7 را تکرار می کنیم 3- محاسبه ی خروجی های خطی واحدها:  4- تابع فعالیت زیر را اعمال می کنیم: yi=f(Ii) 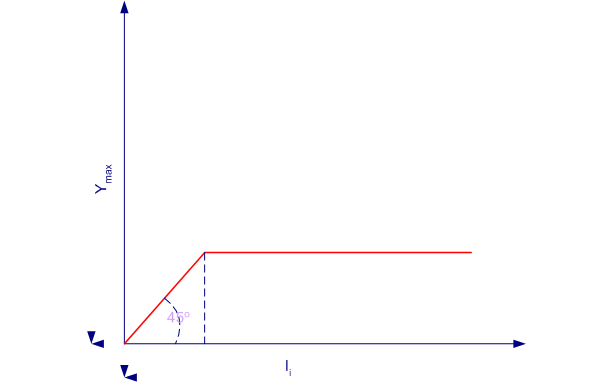 yi=min(ymax,max(0,Ii)) 5- خروجی ها را در yold ذخیره می کنیم: yiold=yi ,i=1,...,n 6- افزایش شمارنده t=t+1 7- آزمایش شرط خاتمه: اگر t<tmax ادامه دهیم در غیر این صورت الگوریتم خاتمه می یابد. 1-3) شبکه ی همینگ (Hamming Network) مقدمه قبل از شروع بحث راجع به شبکه ی همینگ باید با برخی اصطلاحات آشنا شویم. اولین تعریف مربوط به فاصله ی همینگ می شود. فاصله ی همینگ بین دو بردار X و Sj برابر تعداد مولفه های دو بردار است که با هم متفاوت هستند، که با dj نمایش داده می شود. تعریف بعدی مربوط به مفهوم میزان تشابه دو بردار است. میزان تشابه دو بردار عبارتست از تعداد مولفه های برابر دو بردارکه آن را با aj نمایش می دهند. پس با توجه به تعاریف ارائه شده داریم: aj=n-dj اکنون اگر فرض کنیم که دو بردار دو قطبی باشند(فقط حاوی مقادیر 1 و 1- ) آنگاه می توان روابط زیر را ارائه نمود: Sj.X=aj-dj=aj+aj-n=2aj-n , aj=0.5*Sj.X+0.5*n=0.5*Ssijxi+0.5*n  مدل ساختاری یک واحد از شبکه ی همینگ بعد از ارائه ی توضیحات اولیه اکنون به بحث پیرامون هدف ارائه ی این شبکه می پردازیم. در شبکه ی همینگ تعدادی از نورون ها شبیه شکل فوق، تعدادی بردار نمونه را ارائه می دهند و شبکه میزان شباهت X ورودی به هر یک را بدست می دهد. بزرگترین خروجی شبیه ترین بردار نمونه به X را مشخص می کند. این بزرگترین خروجی را می توان با استفاده از یک لایه شبکه ی MaxNet مشخص کرد. ساختار شبکه همانگونه که در بخش بالا اشاره شد این شبکه از دو بخش تشکیل یافته است، بخش اول که هر واحد آن معرف یک بردار می باشد که قصد مقایسه ی ورودی با آن را داریم و وزن اتصالات آن نیز بر اساس تعاریف از قبل مشخص و تنظیم می شود، بخش دوم شبکه یک لایه ی شبکه ماکس نت است که جهت تعیین بزرگترین خروجی از بخش اول استفاده می شود و بدین طریق کار تشخیص شبیه ترین بردار به بردار ورودی انجام می گیرد. شکل ذیل ساختار این شبکه را نمایش می دهد. 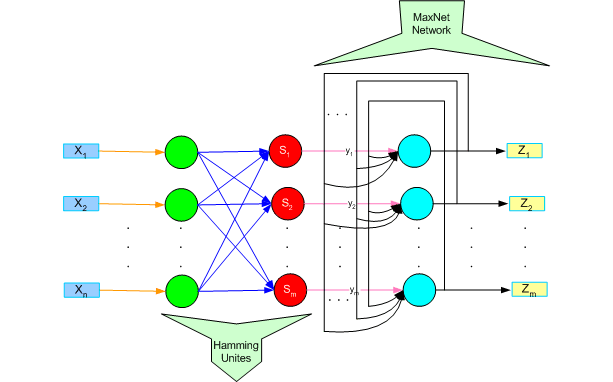 مدل ساختاری شبکه همینگ الگوریتم کار شبکه فرض اولیه ذیل را در نظر می گیریم : n : تعداد عناصر بردار ورودی m : تعداد بردارهای نمونه Sj ، j=1,...,m : بردار های نمونه 0- تعیین وزن های شبکه بر اساس رابطه ی ذیل wi,j=0.5sij ,i=1,...,n j=1,...,m 1- برای هر بردار X قدم های 2 الی 4 را انجام می دهیم. 2- محاسبه خروجی خطی واحدها: ,j=1,...,m  3- تعیین مقادیر اولیه شبکه ماکس نت yj(0)=yi j=1,...,m 4- الگوریتم ماکس نت انجام می شود
__________________
 ويرايش شده توسط Astaraki; ۰۶-۱۴-۱۳۸۹ در ساعت ۱۱:۳۵ قبل از ظهر |
|
|
|
|
۰۶-۱۴-۱۳۸۹, ۱۱:۳۶ قبل از ظهر
|
#5 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
2)شبکه ی (لایه ی) کوهونن
مقدمه ریشه ی قانون یادگیری کوهونن به سالهای 1962 و قبل از آن و به مباحث خوشه بندی بی نظارت بر می گردد. در دهه ی 70 کریستف واندرمالزبرگ قانونی معرفی نمود مبتنی بر این ایده که مجموع وزن های مربوط به ورودی ها در واحدهای مختلف که از یک خروجی آمده اند بایستی ثابت باشند. مبنای این ایده محدود بودن ماده شیمیایی موجود در خروجی مورد بحث و تقسیم شدن آن بین ورودی های مختلف متصل به این خروجی بود. در سال 1976 استفن گراسبرگ ایده مالزبرگ را رد کرد و قانونی که در این بخش مطرح می شود را ارائه نمود. اما در اواخر دهه ی 70 کوهونن به این نتیجه ی مهم رسید که هدف این قانون یادگیری بایستی ساختن یک مجموعه بردار wi که ارائه های هم احتمال یک تابع چگالی احتمال ثابت r را تشکیل می دهند، باشند. یعنی بردارهای wi بایستی طوری خودرا تغییر دهند که برای هر بردار ورودی X با تابع چگالی احتمال r داشته باشیم:  ,X به wi نزدیکترین است به ازاء i=1,2,...,m این ایده برای توابع چگالی احتمال یکنواخت به طور مطلوب کار می کرد، در سال 1987 دوین دسینو تغییری در قانون کوهونن ایجاد نمود که مشکل مزبور را حل کرد اما هنوز به واسطه ی نقش مهم کوهونن در این زمینه، قانون را قانون کوهونن می گویند.  مدل ساختاری شبکه ی کوهونن یک بعدی  مدل ساختاری شبکه ی کوهونن دو بعدی ساختار شبکه یک لایه کوهونن آرایه ای از نورون ها است به صورت یک بعدی، دو بعدی یا بیشتر است که نمونه ای از آن را در شکل فوق مشاهده می نمائید. در فاز یادگیری هر یک از واحدها فاصله ی بردار ورودی X تا وزن های خود را به صورت زیر محاسبه می کنند. Ii=D(X,wi) که D تابع سنجش فاصله است و می توان هر یک از توابع مرسوم برای سنجش فاصله را استفاده نمود، مثلا فاصله ی کمان کروی D(u,v)=1-cosq ، زاویه ی بین u و v q= یا فاصله ی اقلیدسی D(u,v)=|u-v| را می توان استفاده نمود. واحدها با این محاسبه می خواهند بدانند نزدیکترین بردار وزن به x را دارند یا نه که این همان بخش رقابتی در اینگونه از شبکه ها می باشد. واحد دارای نزدیکترین وزن به بردار ورودی، برنده این مرحله از رقابت خواهد بود که برای آن Zi مربوطه برابر 1 قرار داده می شود و سایر Zi ها برابر صفر خواهند بود. آنگاه قانون کوهونن که به صورت ذیل است برای به روز رسانی وزن ها استفاده می شود: winew=wiold+a(X-wiold)zi ,0<a≤1 قانون فوق معادل قانون زیر است:  مشکلات و راه حلها یکی از مشکلات عمده در این نوع از شبکه ها آموزش آنها می باشد، در ادامه توضیحاتی در این رابطه ارائه می گردد. در اوایل فاز یادگیری a را بزرگ اختیار می کنیم(مثلا 0.8)، با پیشرفت یادگیر a کاهش داده می شود تا نهایتا در پایان یادگیری ممکن است به 0.1 یا کمتر از آن رسیده باشد با اعمال بردارهای ورودی مختلف X ها در فاز آموزش بردارهای وزن ها به سمت آنها جذب می شوند و در جاهایی که X های بیشتری قرار گیرند wi های بیشتری متمرکز می شوند و در جاهایی که X های زیادی قرار نمی گیرند wi های زیادی نیز تمرکز نمی یابند به این ترتیب لایه، وزنهای خود را با تابع چگالی احتمال ورودیها تطبیق می دهند. همانگونه که قبلا اشاره شد می خواهیم بردارهای wi خود را طوری تنظیم کنند که برای هر یک ورودی X با تابع چگالی احتمال r احتمال اینکه X به wi نزدیک باشد، برابر 1/m گردد. اما با قانون کوهونن p(wi) تنها در حالت خاصی برابر 1/m می شود مانند حالتی که r در یک و تنها یک ناحیه متصل دارای هندسه ی ساده ثابت یا تقریبا ثابت باشد. پس اگر p(wi)¹1/m شرط برقرار باشد، آنگاه ممکن است با مشکل گیر افتادن بردارهای وزن در نواحی ایزوله و عدم امکان حرکت آنها به نواحی مطلوب مواجه شویم. همچنین ممکن است یک بردار وزن خاص در یک ناحیه همیشه به همه ی X های ورودی در آن ناحیه نزدیکتر باشد و لذا همیشه آن بردار برنده شود و در این حالت وزنهای همه ی واحدها اصلاح نخواهند شد. واحدی که وزن های آن اصلا اصلاح نشود در این شبکه یک واحد مرده نامیده می شود. البته چندین راه برای حل مشکل پیشنهاد شده است که در ادامه با برخی از آنها آشنا می شویم. 1) روش رشد دادن شعاعی (Redial Sproting) β<<1 , Xi-->βXi , wiold=0 یعنی Xi ها را نیز به نزدیکی مبدا می بریم، β تدریجا بزرگ می شود تا اینکه سرانجام به یک می رسد و مشکل حل می شود اما یادگیری بسیار کند پیش می رود. 2) افزایش نویز در این روش به Xi ها نویز دارای توزیع ثابت با دامنه قوی اضافه می شود، به طوری که در ابتدا نویز بر Xi ها غالب باشد با گذشت زمان نویز تضعیف می شود و یادگیری انجام می شود. مشکل این روش نیز سرعت بسیار پایین آن می باشد. 3) استفاده از همسایگی برنده در این روش بجای اصلاح وزنهای واحد برنده به تنهایی، وزنهای واحدهای همسایه واحد برنده را نیز اصلاح می کنیم. در ابتدا آموزش همسایگی را بسیار بزرگ در نظر می گیرند به طوری که تقریبا همه واحدها در آن جای گیرند. اما با پیشرفت یادگیری شعاع همسایگی را تدریجا کوچک می کنیم تا در پایان آموزش به نواحی محلی مجزا که نماینده کلاسهای مختلف ورودی هستند برسیم. 4) روش دسینو در ادامه روشی که توسط دسینو برای حل مشکل آموزش شبکه مطرح شده است اشاره می شود. یک مکانیزم وجدان در شبکه در نظر می گیریم در این حال سابقه برنده شدن واحدها نگهداشته می شود و اگر واحدی بیش از 1/m دفعه برنده شود برای مدتی از رقابت خارج می شود. این روش در اکثر اوقات بسیار خوب عمل می کند، پیاده سازی آن می تواند به صورت زیر انجام پذیرد. پس از پایان رقابت و تعیین zi ها نسبت زمانی که واحد i برنده می شود به صورت زیر محاسبه می شود. finew=fiold+β(zi-fiold) همچنین یک بایاس از رابطه زیر حساب می شود: bi=g(1/m-finew) حال می گوئیم وزنهای واحدی اصلاح می شود که دارای کوچکترین فاصله: D'=D(wi,X)-bi باشد. اگر واحد i خیلی برنده شود : bi<0 می شود و D'>D می شود اگر واحد i خیلی کم برنده شود : bi>0 می شود و D'<D می شود اجراء کار تعیین واحد برنده به چند صورت امکان پذیر است: 1- هر واحد از سایر واحدها Ii های مربوط به آنها را دریافت کند و تصمیم بگیرد که خود برنده است یا نه 2- بین واحدها اتصالات جانبی بازدارنده تشکیل شود به طوری که تنها واحد برنده فعال بماند 3- یک واحد برنامه ریزی، همه ی Ii ها را دریافت کند و واحد برنده را اعلام نماید 4- واحد برنامه ریزی یک مقدار آستانه ای به همه واحدها ارسال کند اولین واحدی که داری فاصله Ii کمتر از T باشد برنده حساب می شود مقدار T ابتدا صفر انتخاب می شود و سپس افزایش می یابد. الگوریتم کار شبکه 0- مقادیر اولیه wi0 اختیار می شوند، پارامترهای همسایگی واحد برنده تعیین شود، نرخ یادگیری تعیین شود. 1- تا زمانیکه شرط خاتمه غلط است قدمهای 2 الی 8 تکرار شود. 2- برای هر بردار ورودی X قدمهای 3 الی 5 اجرا شود. 3- برای هر j فاصله D محاسبه شود  4- اندیس J را که برای آن D(J) مینیمم است، تعیین می کنیم. 5- برای کلیه واحدهای j در همسایگی J و برای کلیه iها: wijnew=(1-a)wijold+axi 6- نرخ یادگیری a را به هنگام در می آوریم. 7- شعاع همسایگی را در زمانهای مشخص کاهش می دهیم. 8- شرط خاتمه را آزمایش می کنیم. چند نکته 1) نرخ یادگیری a می تواند به صورت خطی در طی آموزش کاهش یابد. 2) برای همگرا شدن الگوریتم ممکن است لازم شود که مجموعه ی آموزشی ما به دفعات متعدد به شبکه اعمال شود. شیوه های انتخاب همسایگی همسایگی پیرامون نورون برنده را چگونه تعریف کنیم که از نظر بیولوژیکی نیز موجه باشد؟ در علم اعصاب مشخص شده است، که یک واحد فعال بر روی واحدهای همسایگی نزدیک بیشتر از همسایه های دور اثر می گذارد لذا بایستی همسایگی حول نورون i یک همسایگی متقارن و کاهش یابنده هموار بافاصله از i باشد. برای مثال تابع و di,j= فاصله نورون j از نورون i dj,i=|j-i| , dj,i2=||rj-ri||2   که در آن ri و rj برای نشان دادن نورون های i و j در فضای خروجی هستند، و رابطه فوق میزان شرکت همسایه ها در یادگیری را نشان می دهد. از طرف دیگر اندازه ی همسایگی باید با زمان کاهش یابد لذا معمولا s را به صورت زیر در نظر می گیرند:  , n=0,1,... که درآن s0 و t ثابت هستند.  شعاع همسایگی بزرگ در آغاز یادگیری  کاهش شعاع همسایگی با گذر زمان برای تطبیقی کردن نرخ یادگیری نیز از رابطه ی ذیل استفاده می شود: نرخ یادیگری با زمان باید کاهش یابد.  و n=0,1,... و n=0,1,... که h0 و t2 دو ثابت هستند در نهایت قانون تغییر وزن ها به صورت ذیل تبدیل می شود: كد:
wj(n+1)=wj(n)+h(n)hj,i(X)(n)(X-wj(n)) I- در شبکه ی فوق یادگیری در دو مرحله انجام می گیرد که به قرار ذیل هستند: 1) فاز خودسازمان دهی(مرتب شدن-Ordering ) با تغییرات اساسی لازم وزنها در این فاز مرتب می شوند، این کار شاید هزار دور تکرار الگوریتم را طلب بکند(مثلا با 1000 دور تکرار الگوریتم) مسئله ی دیگر در این فاز انتخاب پارامترهای مورد نیاز برای یادگیری است. h می تواند با 0.1 شروع شود و به 0.01 برسد، h0=0.1 ,t2=1000 اندازه همسایگی ابتدا به گونه ای انتخاب می شود که تقریبا همه واحدها در همسایگی باشند سپس تدریجا کوچک می شود تا در پایان فاز مرتب شدن به واحد برنده یا واحد برنده و چند همسایه اش برسد. s0=شعاع نقشه ,  2) فاز همگرائی (Tuning) این فاز برای تنظیم دقیق نقشه است، تکرار الگوریتم در این فاز عموما حدود 500 برابر تعداد واحدهای نقشه است. در این فاز h(n) برای تمام فاز کوچک و ثابت مثلا 0.01 در نظر نظر گرفته می شود. همسایگی در این فاز در ابتدا شامل واحد برنده و چند همسایه آن می شود که سپس به تدریج به خود واحد برنده می رسد. II- نگاشت حاصل از شبکه SOM به این ترتیب است : F:X-->A که در آن F نگاشت ویژگی غیر خطی است و X فضای پیوسته ورودی یا داده ها است و همچنین A فضای گسسته خروجی است. نگاشت ویژگی F که با مجموعه ی {wi} در فضای A ارائه می شود تقریب خوبی از فضای ورودی X است. III- نقشه ی محاسبه شده با SOM از نظر توپولوژیکی مرتب شده است، یعنی مکان یک نورون در نقشه متناظر یک قلمرو ویژگی مشخص الگوهای ورودی است. نقشه ی ویژگی معمولا در فضای ورودی x نشان داده می شود. هر وزن با یک دایره کوچک نشان داده می شود و این دوایر برای نورون های مجاور با خط به یکدیگر وصل می شوند. IV- اگر توپولوژی یک بعدی باشد و ورودی دو بعدی شبکه با پیچ و خم سعی می کند آن را بپوشاند. V- این نوع از شبکه ها بسیار پر کاربرد هستند.
__________________
ويرايش شده توسط Astaraki; ۰۶-۱۴-۱۳۸۹ در ساعت ۱۱:۴۳ قبل از ظهر |
|
|
|
|
۰۶-۱۴-۱۳۸۹, ۱۱:۴۸ قبل از ظهر
|
#6 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
برخی انواع تغییر یافته ی SOM
بعد از آشنا شدن با مبانی این شبکه و برخی از انواع آن در ادامه لیستی از شبکه ی حاصل شده از تغییرات در نوع اولیه ی SOM که به ضرورتهای کاری مختلف انجام گرفته اند، ارائه می گردد. 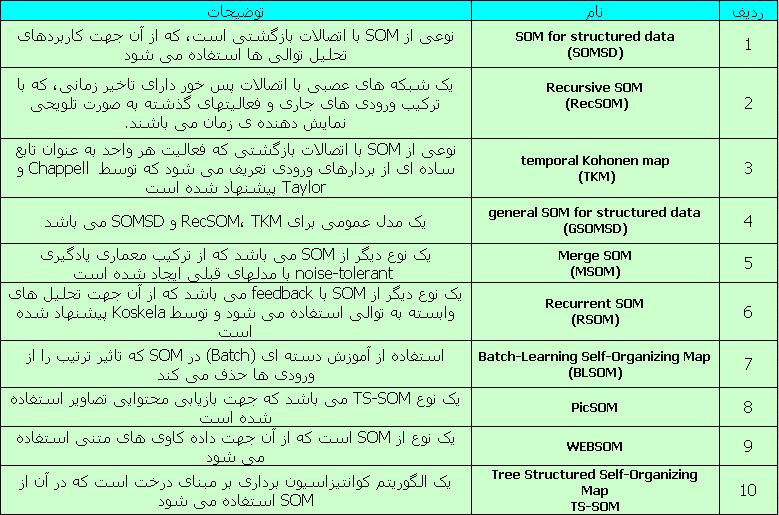 |
|
|
|
|
۰۶-۱۴-۱۳۸۹, ۱۱:۵۲ قبل از ظهر
|
#7 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
برخی کاربردهای شبکه های SOM
در این بخش به برخی از موارد استفاده شبکه های SOM می پردازیم. البته، کاربردهای آن بسیار زیاد می باشد ولی در اینجا به برخی از آنها پرداخته می شود، که در مورد هر کدام نیز مرجع مورد استفاده نیز جهت مطالعه ی بیشتر معرفی گردیده است. الف- استفاده از شبکه ی SOM در سنجش از راه دور(Remote Sensing) در مواردی که به جهت زیاد بودن دقت سنسورهای تصویر گیری با داده های با ابعاد زیاد مواجه می شویم بکار می رود، که این کاربرد در بخش Extensions and Modi_cations of the Kohonen-SOM and Applications in Remote Sensing Image Analysis از کتاب SOM نوشته ی Thomas Villmann به صورت مفصل به همراه اصلاحات انجام گرفته در ساختار اولیه ی SOM ارائه شده است. ب- تشخیص نفوذ غیر مجاز، با استفاده از شبکه ی SOM که در مقاله ی Multiple Self-Organizing Maps for Intrusion Detection نوشته ی Brandon Craig Rhodes, James A. Mahaffey, James D. Cannady ارائه شده است. ج- مدلسازی شبکه های غشائی بزرگ با استفاده از SOM رشد کننده که در مقاله ی Modeling large cortical networks with growing self-organizing maps نوشته ی James A. Bednar, Amol Kelkar, and Risto Miikkulainen به آن پرداخته شده است د- استفاده از شبکه ی SOM برای حل مسئله ی معروف فروشنده ی دوره گرد که در مقاله ی An new self-organizing maps strategy for solving the traveling salesman problem نوشته ی Yanping Bai a,*, Wendong Zhang a, Zhen Jin که در Chaos, Solitons and Fractals 28 (2006) 1082–1089 به چاپ رسیده است، به آن اشاره شده است. و- تخمین چگالی احتمال با استفاده از شبکه های SOMN که در مقاله ی Self-Organizing Mixture Networks for Probability Density Estimation نوشته ی Hujun Yin and Nigel M. Allinson که در IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 12, NO. 2, MARCH 2001 به چاپ رسیده است، به آن پرداخته می شود. ن- داده کاوی (Data mining) در توالی ها با استفاده از RecSOM که در مقاله ی Data Mining on Sequences with recursive Self-Organizing Maps نوشته ی Sebastian Blohm به آن اشاره شده است. ه- استفاده از SOM برای تکثیر داده های ادغامی به صورت غیر خطی که در مقاله ی Self-organizing map learning nonlinearly embedded manifolds نوشته ی Timo Simila که در Information Visualization (2005) 4, 22–31 به چاپ رسیده است، مورد بحث قرار گرفته است. ی- استفاده از Recurrent SOM برای تخمین سری های زمانی که در مقاله ی Recurrent SOM with Local Linear Models in Time Series Prediction نوشته Timo Koskela, Markus Varsta, Jukka Heikkonen به آن اشاره شده است. . . . و کاربردهای بسیار دیگروجود دارند که با این شبکه و انواع اصلاح شده ی آن انجام می گیرد. لیستی از مقالات ارائه شده در زمینه ی SOM جمع آوری شده است که می توانید از طریق لینک Reference آن را Download کنید. |
|
|
|
|
۰۶-۱۴-۱۳۸۹, ۱۱:۵۵ قبل از ظهر
|
#8 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
نحوه ی پیاده سازی این نوع از شبکه در مجموعه ی Matlab
 نرم افزار مطلب، یکی از نرم افزارهای قوی و جامع در ارتباط روشهای یادگیری، از جمله شبکه های عصبی می باشد که برای بسیاری از کابردها می توان از آن استفاده نمود. در این بخش قصد داریم توضیحات مختصری در ارتباط با نحوه ی پیاده سازی شبکه های SOM در این نرم افزار ارائه نمائیم. ساختار لایه ی رقابتی که در نرم افزار مطلب از آن استفاده می شود به فرم ذیل می باشد:  برا این کار از دستور newc استفاده می شود. كد:
net = newc(PR,S,KLR,CLR) كد:
p = [.1 .8 .1 .9; .2 .9 .1 .8] p = 0.1000 0.8000 0.1000 0.9000 0.2000 0.9000 0.1000 0.8000 net = newc([0 1; 0 1],2); كد:
wts = net.IW{1,1}
wts =
0.5000 0.5000
0.5000 0.5000
كد:
biases =
5.4366
5.4366
 برای تعیین مقادیر Bias نیز از قانون یادگیری learncon استفاده می شود که استفاده از این قانون به نوعی پیاده سازی الگوریتم وجدان پیشنهادی دسینو می باشد که برای پرهیز از ایجاد نورون های مرده استفاده می شود. بعد از آشنایی با توابع مورد استفاده جهت آموزش شبکه در ادامه با نحوه ی آموزش شبکه آشنا می شویم. برای آموزش شبکه ایجاد شده از دستور كد:
net2=train(net1,p) در پایان بعد از آموزش نیز جهت آزمایش شبکه نیز می توان از دستور كد:
a=sim(net,p) علاوه بر دستور newc که در بالا مختصری مورد بررسی قرار گرفتن دستور دیگری نیز وجود دارد که شبکه ی SOM دیگری را با قابلیهای بیشتر ایجاد می کند که در ادامه به بررسی آن می پردازیم. این شبکه جدید دارای ساختار ذیل می باشد:  كد:
net = newsom(PR,[D1,D2,...],TFCN,DFCN,OLR,OSTEPS,TLR,TND) برای شبکه عصبی ایجاد شده می توان از انواع مختلفی توپولوژی استفاده نمود، توپولوژیهای قابل تعریف عبارتند از: 1) Gridtop که به فرم ذیل است.  2) Hextop که به فرم ذیل است.  3) Randtop که به فرم ذیل است.  همچنین چهار نوع تابع فاصله ی مختلف وجود دارد که می تواند مورد استفاده قرار گیرند. اولین آنها تابع dist است که همان فاصله ی اقلیدسی می باشد، دومی تابع linkdist می باشد که عبارتست از تعداد اتصالات یا مراحلی که باید در توپولوژی طی شود تا از یک نورون به نورون دیگر برسیم که قصد تعیین فاصله ی بین آن دو را داریم، سومی تابع boxdist است که شکل ذیل نحوه ی محاسبه ی آن را در توپولوژی grid نشان می دهد، چهارمین و آخرین آنها mandist می باشد که همان فاصله manhattan را محاسبه می نماید.  سایر پارامترهای ارسالی در آموزش شبکه موثر می باشند که در ادامه به توضیح مختصری از آنها می پردازیم. همانگونه که در بخش توضیحات شبکه ی SOM ارائه شد، این شبکه به پیشنهاد آقای کوهونن در دو مرحله آموزش داده می شود، در مرحله ی اول فاز Ordering است که در آن سعی می شود با قدم های بزرگ یک ترتیب کلی در وزن همه ی نورون ها ایجاد شود از این رو پارامترهای OLR که نرخ یادیگری این فاز است معمولا مقدار بزرگی است (0.9) و در مرحله ی بعد که مرحله ی همگرایی است، TLR مقدار کوچکتری را دارا می باشد (0.02) تا با تغییرات کوچک در وزن ها به نوعی تنظیم نهایی و دقیق تری در وزن ها ایجاد می شود. برای آموزش این شبکه نیز از دستور train استفاده می شود.
__________________
ويرايش شده توسط Astaraki; ۰۶-۱۴-۱۳۸۹ در ساعت ۱۱:۵۸ قبل از ظهر |
|
|
|
|
۰۶-۱۴-۱۳۸۹, ۱۲:۵۸ بعد از ظهر
|
#9 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
چند مثال پیاده سازی از این نوع شبکه
در این بخش چند نمونه از پیاده سازی های انجام گرفته برای این شبکه با نرم افزاهای مختلف ارائه می شود، در ابتدا پیاده سازیی جامع در نرم افزار مطلب ارائه می گردد. در ذیل واسط گرافیکی طراحی شده ارائه شده است.     پیاده سازی دیگری که از این شبکه ها انجام گرفته است با استفاده از زبان و امکانات برنامه نویسی جاوا بوده، که مجموعه ی آن از طریق سایت SourceForge.net: Download and Develop Open Source Software for Free قابل download می باشد. این پیاده سازی تحت نام javasom انجام گرفته است.
__________________
ويرايش شده توسط Astaraki; ۰۶-۱۴-۱۳۸۹ در ساعت ۰۱:۱۲ بعد از ظهر |
|
|
|
| از Astaraki تشكر كرده اند: |
|
۰۶-۱۴-۱۳۸۹, ۰۱:۳۱ بعد از ظهر
|
#10 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
لینک های مربوط
كد:
|
|
|
|
|
| كاربران در حال ديدن تاپيک: 1 (0 عضو و 1 مهمان) | |
 Linear Mode
Linear Mode

|
|

زمان محلي شما با تنظيم GMT +3.5 هم اکنون ۰۶:۵۵ قبل از ظهر ميباشد.





