انجمن را در گوگل محبوب کنيد :
|
|||||||


| تبليغات سايت | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  |
|
|
LinkBack | ابزارهاي تاپيک | نحوه نمايش |
 ۰۹-۱۸-۱۳۸۸, ۰۷:۴۱ بعد از ظهر
۰۹-۱۸-۱۳۸۸, ۰۷:۴۱ بعد از ظهر
|
#1 (لینک دائم) |
|
Administrator
 
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:

 |
مفاهیم اولیه کلاسترینگ يا دسته بندي(Clustering)
کلاسترينگ به معناي کلاس بندي بدون نظارت است که کلاسها از قبل تعيين شده نيستند و يا به عبارت ديگر برچسب کلاس الگوهاي آموزشي در دسترس نيست. بنابراين اکنون هدف اصلي ما سازماندهي الگوها به گروهاي sensible است. که به ما اجازه مي دهند که شباهت و تفاوت بين الگوها را کشف کنيم و نتايج مفيد را درباره آنها استنتاج نماييم. اين ايده در زمينه هاي مختلف ديده مي شود. مثال زير از زيست شناسي الهام گرفته شده است و صورت مسئله را براي ما واضح مي سازد. به حيوانات زير توجه کنيد: گوسفند،سگ و گربه (پستاندار)، گنجشک و بلبل (پرنده)، ماهي قرمز، شاه ماهي (ماهي)، افعي و مارمولک(خزنده) و غوک(دوزيست). به منظور مرتب کردن اين حيوانات در داخل کلاسترها نياز داريم که يک ملاک دسته بندي تعريف کنيم. اگر وجود شش ها را بررسي کنيم، ماهي قرمز و شاه ماهي در يک کلاستر و بقيه در يک کلاستر ديگر قرار مي گيرند(شکل(الف)). اگر ملاک دسته بندي را محيطي که حيوانات زندگي مي کنند قرار دهيم آنگاه گوسفند، سگ، گربه، گنجشک، بلبل،افعي و مارمولک (حيواناتي که بيرون آب زندگي مي کنند) کلاستر اول و ماهي قرمز و شاه ماهي (حيواناتي که در آب زندگي مي کنند) کلاستر دوم را تشکيل مي دهند و غوک که مي تواند هم در آب و هم در خشکي زندگي کند کلاستر سوم را تشکيل مي دهد (شکل (ب)). اگر وجود ستون فقرات را ملاک دسته بندي باشد تمام حيوانات در يک دسته قرار مي گيرند. ما مي توانيم از ملاک دسته بندي مرکب استفاده کنيم. براي مثال اگر ملاک دسته بندي نحوه بدنيا آوردن فرزندان و وجود شش ها باشد ما سه نوع کلاستر داريم که در شکل (ج) آورده شده است.  اين مثال نشان مي دهد که فرايند نسبت دادن اشيا به کلاسترها ممکن است به نتايج بسيار متفاوتي منجر شود. کلاسترينگ يکي از ابتدايي ترين فعاليت هاي ذهني است که براي کنترل کردن مقادير زياد اطلاعات دريافت شده هر روزي استفاده مي شود. پردازش هر بخش از اطلاعات به عنوان يک موجوديت تک امکان پذير نيست. بنابراين انسانها به دسته بندي موجوديت ها (حوادث، انسانها، اشيا و غيره ) در کلاسترها روي مي آورند. هر کلاستر توسط خصوصيات مشترک موجوديت هايي که درون آن قرار مي گيرند تعريف مي شود. کلاستر، يک مجموعه از داده هاست بطوريکه: · داده هاي موجود در يک کلاستر شبيه يکديگر هستند. · داده هاي موجود در کلاسترهاي مختلف به يکديگر شبيه نيستند. انواع کلاسترها کلاستر ها انواع مختلفي دارند که در به زير تعدادي از آنها اشاره شده است: - كلاسترهاي بخوبي جدا شده مجموعه نقاط داخل اين كلاستر نسبت به نقاط خارج آن به يكديگر بسيار شبيهند. - كلاسترهاي مبتني به مركز: مجموعه نقاط داخل اين كلاستر به مركز كلاستر نسبت به مراكز كلاسترهاي ديگر بسيار نزديكترند. - كلاسترهاي مبتني بر مجاورت و نزديكي: مجموعه نقاط داخل اين كلاستر به يك يا تعداد بيشتري از نقاط داخل كلاستر نسبت به نقاط خارج آن شبيهند. گامهاي اساسي در انجام کلاسترينگ: به منظور ايجاد کلاستر ها (انجام عمل کلاسترينگ) اعمال زير بايد انجام شوند: 1. انتخاب ويژگي: خصوصيات بايد به طور مناسبي انتخاب شوند تا اکثر اطلاعات را کدگذاري کنند. 2. مقياس نزديکي: معياري است که ميزان شباهت و يا عدم شباهت دو بردار خصوصيت را مشخص مي کند. تمام خصوصيات انتخاب شده بايد در محاسبه اين معيار شرکت کنند و هيچ خصوصيتي نبايد بر بقيه غلبه کند. به عنوان مثال فاصله اقليدسي يا فاصله منهتن. 3. ملاک دسته بندي: که در قسمتهاي بالا در مورد آن صحبت شده است. 4. الگوريتم کلاسترينگ: پس از اينکه ملاک دسته بندي و مقياس نزديکي انتخاب شدند در اين گام يک الگوريتم خاص جهت روشن کردن ساختار دسته بندي مجموعه داده انتخاب مي شود. 5. اعتبار نتايج: زمانيکه نتايج کلاسترينگ بدست آمد بايد صحت و درستي آنها بررسي شوند. اين کار معمولا بوسيله تست هاي مناسبي انجام مي شود. درمقاله بعدي از انواع الگوريتمهاي کلاسترينگ صحبت خواهيم کرد. |

|

|


| از Astaraki تشكر كرده اند: | andromeda (۰۹-۲۸-۱۳۸۸), atefeh.esmaili (۰۹-۲-۱۳۸۹), dr_bijan (۰۹-۲۵-۱۳۹۲), ITman2010 (۰۳-۱۹-۱۳۹۱), kapricorn (۰۵-۱۸-۱۳۸۹), mahdifarahani (۰۶-۶-۱۳۸۹), mer3deh_2000 (۰۷-۱۳-۱۳۹۲), sajjad0hp (۱۲-۴-۱۳۸۹), Sepidsal (۰۵-۲۲-۱۳۹۳), shahak (۱۲-۸-۱۳۸۸), siya_kh1983 (۰۲-۲۲-۱۳۸۹) |
| #ADS | |
|
نشان دهنده تبلیغات
تبليغگر
تاريخ عضويت: -
محل سكونت: -
سن: 2010
پست ها: -
|
|

|
|
۰۹-۱۸-۱۳۸۸, ۰۷:۵۲ بعد از ظهر
|
#2 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
الگوريتم هاي کلاسترينگ (1)
در اين قسمت انواع الگوريتم هاي کلاسترينگ را بررسي مي کنيم. الگوريتم هاي کلاسترينگ را مي توان به دسته هاي اصلي زير تقسيم بندي کرد: • الگوريتم هاي کلاسترينگ ترتيبي • الگوريتم هاي کلاسترينگ سلسله مراتبي • الگوريتم هاي کلا سترينگ مبتني بر بهينه سازي تابع هزينه الگوريتم هاي کلاسترينگ ترتيبي اين الگوريتم ها در ابتدا يک کلاستر تک توليد مي کنند و روش هاي سريع و واضحي مي باشند. در اکثر آنها بردارهاي خصوصيات به تعداد دفعات کمي و يا تنها يک بار به الگوريتم داده مي شوند. در اينجا بطور خلاصه الگوريتم ترتيبي پايه را توضيح مي دهيم. در اين نمونه تمام بردارها يک بار به الگوريتم ارائه مي شوند. تعداد دسته ها در اين مورد از قبل مشخص نيستند. در واقع کلاسترهاي جديد در حين اجراي برنامه ايجاد مي شوند. اگر به معناي فاصله (عدم شباهت) بين بردار خصوصيت و کلاستر باشد، هر بردار بسته به فاصله از کلاستر، به کلاسترهاي موجود و يا به کلاستر جديد نسبت داده مي شود. در زير الگوريتم کلاسترينگ ترتيبي پايه آورده شده است. 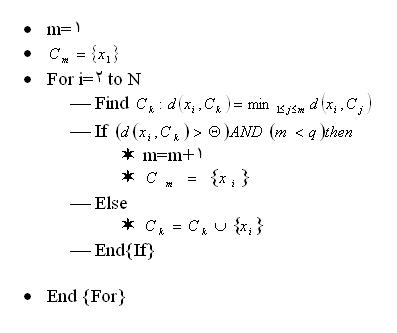 در الگوريتم هاي کلاسترينگ ترتيبي نتيجه نهايي به ترتيبي که بردارها به الگوريتم ارائه مي شوند بستگي دارد. |
|
|
|
| از Astaraki تشكر كرده اند: | atefeh.esmaili (۰۹-۲-۱۳۸۹), dr_bijan (۰۹-۲۵-۱۳۹۲), kapricorn (۰۵-۱۸-۱۳۸۹), shahak (۱۲-۸-۱۳۸۸), siya_kh1983 (۰۲-۲۲-۱۳۸۹) |
|
۰۹-۱۸-۱۳۸۸, ۰۷:۵۶ بعد از ظهر
|
#3 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
کلاسترينگ سلسله مراتبي (Hierarchical Clustering)
با در دست داشتن N نمونه داده براي کلاستر شدن و يک ماتريس فاصله يا شباهت به ابعاد N*N ، پروسه اصلي کلاستريگ سلسله مراتبي به صورت زير ميباشد : 1. با تخصيص هر نمونه به يک کلاستر شروع کنيد . يعني اگر N نمونه داشته باشيم ، N کلاستر داريم که هر يک داراي يک نمونه مي باشند . فاصله بين کلاستر ها همان فاصله بين کلاستر هاي آنهاست . 2. دو کلاستري را که نزديک تر هستند پيدا کنيد و آنها را ادغام کنيد . حالا يک کلاستر کمتر داريم . 3. فاصله کلاستر جديد را با هر يک از کلاسترهاي قديمي محاسبه کنيد . 4. مراحل 2 و3 را آنقدر تکرار کنيد که همه نمونه ها در يک کلاستر به اندازه N قرار بگيرند مرحله 3 مي تواند به روش هاي مختلفي انجام گيرد که کلاستريگ single-linkage ، complete-linkage و Average-linkage را مشخص مي کند . در کلاستريگ single-linkage (که روش connectedness يا minimum هم ناميده مي شود( ، فاصله يک کلاستر از کلاستر ديگر را کوتاهترين فاصله هر عضو از کلاستر اول تا هر عضو از کلاستر دوم در نظر مي گيرند . اگر داده ها شامل شباهت باشند ، شباهت يک کلاستر تا کلاستر ديگر را برابر بيشترين شباهت هر عضو از کلاستر اول تا هر عضو از کلاستر دوم در نظر مي گيرند . در کلاستريگ complete-linkage (که روش diameter يا maximum هم ناميده مي شود(، فاصله يک کلاستر از کلاستر ديگر را بزرگترين فاصله هر عضو از کلاستر اول تا هر عضو از کلاستر دوم در نظر مي گيرند . در کلاستريگ average-linkage ، فاصله يک کلاستر از کلاستر ديگر را ميانگين فاصله هر عضو از کلاستر اول تا هر عضو از کلاستر دوم در نظر مي گيرند . کلاستريگ سلسله مراتبي ، agglomerative يا متراکم شونده نيز ناميده مي شود ، زيرا کلاستر ها را به تدريج ادغام مي کند .کلاسترينگ تقسيم کننده يا divisive هم وجود دارد که به صورت عکس عمل مي کند ، به اين صورت که ابتدا همه اشياء را در يک کلاستر قرار مي دهد و به تدريج آن را به قطعه هاي کوچکتر تقسيم مي کند. البته اين نوع کلاستريگ به ندرت مورد استفاده قرار مي گيرد . شکل زير نحوه عملکرد اين دو الگوريتم را نشان مي دهد. الگوريم کلاسترينگ single-linkage : اين الگوريم agglomerative است و زمانيکه کلاستر ها براي تشکيل کلاستر هاي جديد ، ادغام مي شوند ، سطرها و ستون هاي مربوط به آنها را در ماتريس مجاورت پاک مي کند . ماتريس مجاورت به ابعاد N*N ، D = [d(i,j)] را در نظر بگيريد . به کلاستر ها اعداد 0 و 1 و ... و n-1 ، تخصطص داده مي شود و L(k) ، سطح k امين کلاسترينگ است . کلاستري با شماره m به صورت (m) نمايش داده مي شود و مجاورت بين کلاسترهاي (r) و (s) به صورت d[(r) , (s)] نمايش داده مي شود . الگوريتم شامل مراحل زير است : 1. با کلاسترينگ با سطح L(0)=0 و m=0 شروع کنيد . 2. بي شباهت ترين جفت از کلاستر ها را پيدا کنيد . ((r),(s)) : D[(r),(s)] = min d[(i),(j)] مينيمم بين همه جفت کلاسترها در نظر گرفته مي شود . 3.m=m+1 قرار دهيد . کلاستر هاي (r) و (s) را ادغام کنيد تا تا کلاستريگ بعدي را تشکيل دهد . سطح کلاستريگ را به اين صورت تنظيم کنيد : L(m) = d[(r),(s)] 4. ماتريس مجاورت (D) را update کنيد . به اين ترتيب که سطرها و ستون هاي مربوط به کلاسترهاي(r) و (s) را حذف کنيد و يک سطر و ستون جديد براي کلاستري که تازه تشکيل شده ايجاد کنيد . مجاورت بين کلاستر جديد (r,s) و کلاستر هاي قديمي k به اين ترتيب محاسبه مي شود: d [(k), (r,s)] = min d[(k),(r)], d[(k),(s)] 5. اگر تمام اشياء در يک کلاستر قرار گرفتند متوقف مي شويم ، در غير اين صورت به مرحله 2 باز مي گرديم . يک مثال : به عنوان مثال يک کلاسترينگ از فواصل بين يک سري از شهر هاي ايتاليايي که بر حسب کيلومتر بيان شده اند را بررسي مي کنيم . روش استفاده شده ، single-linkage مي باشد . ماتريس فاصله که ورودي مي باشد به صورت زير است : (براي همه کلاستر ها L=0 مي باشد .)   نزديکترين شهرها MI و TO هستند ، که به فاصله 138 کيلومتر مي باشند . آنها در يک کلاستر به نام MI/TO ادغام مي شوند . سطح کلاستر جديد L(MI/TO) = 138 و m=1 مي باشد . مي توانيم فاصله اين شيء ترکيبي را از همه اشياء ديگر محاسبه کنيم . در کلاسترينگ single-linkage ، قانون اين است که فاصله شيء ترکيبي تا ساير اشياء ، برابر کوتاهترين فاصله از هر عضو از کلاستر تا شيء خارجي مي باشد . بنابراين فاصله MI/TO تا RM ، 564 انتخاب مي شود که فاصله از MI تا RM مي باشد.بعد از ادغام MI و TO ، خواهيم داشت :   min d(i,j) = d(NA,RM) = 219 => NA وRM در کلاستر جديدي به نام NA/RM ادغام مي شوند . L(NA/RM) = 219 m = 2   min d(i,j) = d(BA,NA/RM) = 255 => BA و NA/RM در کلاستر جديدي به نام BA/ NA/RM ادغام مي شوند . L(BA/NA/RM) = 255 m = 3   min d(i,j) = d(BA/NA/RM,FI) = 268 => BA/NA/RM و FI در کلاستر جديدي به نام BA/FI/NA/RM ادغام مي شوند . L(BA/FI/NA/RM) = 268 m = 4   نهايتاً دو کلاستر باقيمانده را در سطح 295 ادغام مي کنيم . پروسه انجام شده به صورت خلاصه در ساختار سلسله مراتبي درخت زير نمايش داده شده است  مشکلات : نقاط ضعف اصلي روش هاي کلاسترينگ agglomerative عبارتند از : ? پيچيدگي زماني ، حداقل ( O(n است که n ، تعداد کل اشياء مي باشد . ? مراحلي که قبلاً انجام شده ، قابل بازگشت نيستند و نمي توان تأثير قدم هاي قبلي را undo کرد |
|
|
|
|
۰۹-۱۹-۱۳۸۸, ۱۲:۱۵ قبل از ظهر
|
#4 (لینک دائم) |
|
Administrator

تاريخ عضويت: آذر ۱۳۸۸
محل سكونت: تهران
پست ها: 309
تشكرها: 120
1,750 تشكر در 263 پست
My Mood:
|
با تشکر فراوان از شما دقیقا همان چیزی بود که لازم داشتم
ولی به نطرم بهتر بود خوشه بندی را در زیر شاخه مطالب Machine learning یا Data mining قرار می دادید. |
|
|
|

| از mardin200 تشكر كرده است: | shmail (۰۹-۱۹-۱۳۸۸) |
|
۰۹-۱۹-۱۳۸۸, ۱۰:۲۰ بعد از ظهر
|
#5 (لینک دائم) | |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
نقل قول:
 به همين دليل اينجا قرار گرفته(چون تنها به يک بخش تعلق نداره) به همين دليل اينجا قرار گرفته(چون تنها به يک بخش تعلق نداره)
|
|
|
|
|

| از Astaraki تشكر كرده است: | minooo (۰۸-۱۴-۱۳۸۹) |
|
۰۹-۲۰-۱۳۸۸, ۰۸:۴۸ بعد از ظهر
|
#6 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
مقدمه
ما در جها نی پر از داده زند گی می کنیم. هر روزه انسانها با حجم وسیعی از اطلاعات روبه رو هستند که باید آنها را ذخیره ساز ی یا نمایش دهند. یکی از روشها ی حیاتی کنترل و مد یریت این داده ها، کلاس بند ی یا گروه بند ی داده های با خواص مشابه، درون مجموعه ای از دسته ها یا خوشه ها می باشد. امروزه، خوشه بندی نقش حیاتی در روشهای بازیابی اطلاعات برای سازمان بندی مجموعه های بزرگ مستندات متنی مانند وب، درون تعداد كمی خوشه معنادار دارد. معمولا در خوشه بندی مستندات متنی، با ابعاد بسیار بالای فضای داده مواجه هستیم كه انجام خوشه بندی به این شكل، مشكل به نظر می رسد. اساسا، سیستمهای خوشه بندی همراه با نظارت یا بدون نظارت هستند.. برخلاف کلاس بندی در خوشه بندی ، گروه ها از قبل مشخص نمی باشند و همچنین معلوم نیست که بر حسب کدام خصوصیات گروه بندی صورت می گیرد. درنتیجه پس از انجام خوشه بندی باید یک فرد خبره خوشه های ایجاد شده را تفسیر کند و در بعضی مواقع لازم است که پس از بررسی خوشه ها بعضی از پارامترهایی که در خوشه بندی در نظر گرفته شده اند ولی بی ربط بوده یا اهمیت چندانی ندارند حذف شده و جریان خوشه بندی از اول صورت گیرد. هدف نهایی خوشه بندی این است که داده های موجود را به چند گروه تقسیم کنند و در این تقسیم بندی داده های گروه های مختلف باید حداکثر تفاوت ممکن را به هم داشته باشند و داده های موجود در یک گروه باید بسیار به هم شبیه باشند . البته کیفیت نتایج خوشه بندی: به روش اندارگیری شباهت و توانایی و قدرت الگوریتم در کشف الگوهای مخفی میان داده ها بستگی دارد . خوشه بندی در زمینه های بسیاری کاربرد دارد از جمله: 1) در زمینه مهندسی ( یادگیری ماشین، هوش مصنوعی، تشخیص الگو، مهندسی مکانیک و الکترونیک ) 2) علوم کامپیوتر ( کاوش وب، تحلیل پایگاه داده فضایی، جمع آوری مستندات متنی، تقسیم بندی تصویر ) 3) علوم پزشکی ( ژنتیک، زیست شناسی ، میکروب شناسی ، فسیل شناسی ، روان شناسی ، بالین ، آسیب شناسی ) 4) علوم زمین شناسی ( جغرافیا، زمین شناسی، نقشه برداری از زمین ) 5) علوم اجتماعی ( جامعه شناسی، روان شناسی، تاریخ، آموزش وپرورش) 6) اقتصاد (بازاریابی، تجارت ) خوشه بندی ممکن است با نامهای دیگری از قبیل علم رده بندی عددی، یادگیری بدون معلم (یا یادگیری بدون نظارت)، تحلیل گونه شناسی و افرازبندی بکار برده شود. 2) رویه خوشه بندی معمولا خوشه بندی الگوها شامل مراحل زیر می باشد : ۱) نمایش الگو (می تواند شامل استخراج و یا انتخاب معیار و مشخصه نیز باشد) ۲) تعریفی از اندازگیری نزدیکی (شباهت) الگوها برای دامنه داده ها ۳) خوشه بندی یا گروه بندی ۴) انتزاع داده (در صورت نیاز) ۵) ارزیابی یا اعتبارسنجی خروجی (در صورت نیاز) شکل ۱ ترتیب معمول سه گام اول را نشان می دهد، که شامل مسیر بازخورد از خروجی فرایند گروه بند ی به مراحل قبل می شود. نمایش الگو شامل تعیین تعداد کلاس ها و تعداد الگوهای موجود برای الگوریتم خوشه بندی موجود می باشد. بعضی از این اطلاعات ممکن است توسط شخص خبره کنترل نشوند. 1. انتخاب مشخصه ها،فر ایند تعیین موثرترین زیرمجموعه از مشخصه ها ی اصلی، بر ای استفاده در خوشه بندی می باشد . 2. استخراج مشخصه، از یک یا چند تبد یل از مشخصه ها ی ورودی استفاده می کند تا مشخصه ها ی برجسته و جدید دیگری تو لید نما ید. هر کدام از این تکنیکها (یا هر دو آنها ) می تواند بر ای بدست آوردن یک مجموعه مناسب، در خوشه بندی استفاده شوند. نزدیکی (شباهت) الگو، معمولا بوسیله تعریف تابع فاصله بر روی هر زوج از الگوها اندازه گیری می شود . معیارهای مختلفی برای اندازگیری فاصله بین الگوها استفاده می شود که معروفترین آن فاصله اقلیدسی می باشد. خروجی خوشه بندی می تواند گروه های سخت و یا فازی (که هر الگو می تواند درجه عضو یت متفاو تی به هر گروه داشته باشد ) باشد . وجود مسیر بازخورد این نکته را بیان می نماید که تحلیل خوشه ها یک فرایند یکباره نیست و در بسیاری از موارد نیاز به تکرار و چرخش بین مراحل محسوس است. انتزاع داده فر ایند استخراج یک (نما یش ساده و فشر ده از) مجموعه داده می باشد . در خوشه بند ی محتوا، یک انتزاع داده توصیف خلاصه ای از هر کلاستر می باشد مثل مرکز ثقل خوشه. 3) معیارهای تست خروجی الگوریتم حال مسئله این است که چگونه، خروجی الگوریتم خوشه بندی را ارز یابی کنیم؟ یک خوشه بند ی خوب با ید چه مشخصه ها یی داشته باشد؟ چون با یک مجموعه داده یا الگوی داده شده، هر الگور یتم خوشه بندی می تواند تقسیم بندی متفاوتی را تولید نماید، بدون اینکه مهم باشد که ساختاری وجود دارد یا خیر. بنابر این استاندارد و معیار ارز یابی الگوریتم، اهمیت دارد. در کل سه دسته معیار تست وجود دارد : 1) شاخص ها ی خار جی 2)شاخص ها ی داخلی 3)شاخص ها ی نسبی این دسته بند ی سه نوع ساختار اصلی از الگوریتمهای خوشه بندی را بوجود می آورد : 1)خوشه بندی افرازی 2) خوشه بندی سلسله مراتبی 3)خوشه بندی های خاص تست برای حالتی که هیچ ساختار خوشه بندی در میان داده ها وجود نداشته باشد هم در نظر گرفته می شود، اگر چه این حالت بندرت اتفاق می افتد . 1) شاخص ها ی خار جی: شاخص ها ی خار جی بر پایه ساختارهای از قبل مشخص شده می باشند، که اطلاعات پیشین از داده ها را منعکس می کنند . این شاخص ها به عنوان استاندارد تایید اعتبار جوابها ی خوشه بند ی استفاده می شوند . 2) شاخص ها ی داخلی: تست داخلی به اطلاعات خار جی (دانش پیشین) وابستگی ندارند . آنها مستقیما ساختار خوشه بندی را از روی داده ها ی اصلی آزما یش می کنند . 3) شاخص ها ی نسبی : معیارهای نسبی برروی مقایسه بین تفاوتها ی ساختارهای خوشه بند ی تاکید می کنند، بطوری که مرجعی بر ای تصمیم گیری اینکه، کدام مشخصه از ا شیا می تواند شایستگی خوشه ها را بهتر از همه آشکار نماید. 4) چالشهای الگوریتمهای خوشه بندی به طور کلی الگوریتم های خوشه بندی داده ها با چالشهای زیر روبرو هستند : 1) مقیاس پذیری : چگونه می توان الگوریتمهای خوشه بندی را تنظیم نمود تا برای پایگاه داده های با حجم بالا کارایی مناسب داشته باشند. 2) توانایی مواجهه با انواع مختلف صفات و داده ها : الگوریتمهای خوشه بندی باید برای داده های گسسته(عددی) و هم برای داده های نوعی (اسمی ) قابل اجرا باشند. 3) حداقل نیازمندی به دانش دامنه که با پارامترهای ورودی مشخص می شود : بسیاری از انواع الگوریتمهای خوشه بندی نیاز دارند تا کاربر پارامترهای ورودی خاصی را به عنوان ورودی تحلیل خوشه ها مشخص کند. (مثل تعداد خوشه های مورد نظر ) مشخص نمودن بسیاری از این پارامترها مسئله دشواری خواهد بود. 4) کشف خوشه ها با اشکال مختلف : اغلب الگوریتم های خوشه بند ی بر پایه فاصله اقلیدسی یا مانهاتان کار می کنند . پس خوشه های کروی شکل با اندازه یا چگالی مشابه را پیدا می کنند . پس مهم است که الگوریتم خوشه بندی بتواند خوشه هایی متناسب با توزیع داده ها بیابد. 5) توانایی مقابله با داده های نویزدار : بیشتر پایگاه های داده شامل داده های پرت ، جاافتاده و نادرست می باشند . چنانچه الگوریتم به این نوع داده ها حساس باشد ، خوشه های با کیفیت پایین تولید خواهندنمود. 6) عدم حساسیت به ترتیب داده های ورودی : نباید الگوریتم خوشه بند ی با ترتیب متفاوت ورود داده ها، خروجی های مختلفی ایجاد نماید. 7) ابعاد بالای داده ورودی : یک پایگاه داده یا انبار داده ممکن است شامل صدها صفت یا بعد باشد . برای مطلوب است که الگوریتم مستقل از تعداد ابعاد، کارایی مناسبی داشته باشد. 8) خوشه بندی همراه با اعمال محدودیتهای کاربر : گاهی نیاز داریم تا برخی از محدودیتها مثل تعداد خوشه ها، را برای الگوریتم تعریف نماییم. 9) قابلیت تفسیر و استفاده : نتایج خوشه بندی باید برای کاربر قابل تفسیر، جامع و مفید باشد. 5) خوشه بندی متن امروزه حجم زیادی از دانش بشر در غالب متن های الکترونیکی وجود دارد. پس یافتن اطلاعات مورد نظر از میان این کوه اطلاعات بسیار مشکل است. برای پاسخ گویی به این چالش روشهای دسته بندی و خوشه بندی متون پیشنهاد شده اند. هدف آنها سازمان بندی مجموعه بزرگ مستندات متنی مانند وب، درون تعداد دسته ها یا خوشه های معنی دار نسبتا کمی می باشد. از جمله کاربرد این روشها در بازیابی اطلاعات از پایگاههای داده، پروسه راه حلهای هوشمند تجارت و مدیریت سیستم های اطلاعاتی یا پورتال سازمانی می باشد. با رشد سریع علم و افزوده شدن صفحات وب و پیدایش ویکی ها و وبلاگها، ساخت یک مجموعه جامع، برای دسته بندی صفحات وب، بسیار مشكل است. پس استفاده از روشهای خوشه بندی داده، می تواند رویکرد مناسبی باشد که به صورت بدون نظارت و بدون نیاز به مجموعه آموزشی اولیه، خوشه بندی را انجام می دهد. تفاوت اصلی خوشه بندی مستندات متنی با دیگر داده ها، ابعاد بالای داده ها می باشد. برای انجام خوشه بندی لازم است تا مستندات متنی در قالب بردار نگهداری شوند، تا بتوان به راحتی با استفاده از معیاری مانند فاصله کسیسنوسی، بردارهای مشابه و نتیجتًا مستندات مشابه را پیدا نمود. برای نمایش برداری این نوع داده ها از مدل فضای برداری استفاده می شود. در این مدل سعی می شود تا یک مجموعه لغت مرجع از لغات نگهداری شود. سپس برای هر متن، برداری با تعداد مولفه به اندازه تعداد کلمات این مجموعه در نظر می گیریم. هر مولفه می تواند تعداد تکرار کلمه متناظر با کلمه درون مجموعه لغت را در متن را نشان دهد یا اینکه هر مولفه به شکل دودویی وجود یا عدم وجود کلمه متناظر در مجموعه لغت درون متن موجود را مشخص نماید. پس به دلیل تعداد ابعاد بالای داده های ورودی شکل استاندارد الگوریتم های خوشه بندی تقسیمی یا جمعی ممکن است کارایی مناسبی نداشته باشد. 6) الگوریتم خوشه بندی Bi-Section-K Means الگوریتم خوشه بندی Bi-Section-K Means بر اساس الگوریتم K Means است و به صورت تجمعی و با سرعت بالا اجرا می شود. این الگوریتم می تواند برای حجم بالای داده های ورودی که ابعاد زیادی دارند به سرعت اجرا گردد. پس الگوریتم Bi-Section-K Means برای خوشه بندی مستندات متنی بسیار مناسب است. این الگوریتم K بار (به اندازه تعداد خوشه ها) تکرار می شود و در هر بار تکرار یک خوشه بدست می آید. در ابتدا تمام مستندات متنی در یک خوشه که بیشترین تعداد متن را دارد انتخاب می شود. سپس دو نقطه تصادفی در آن خوشه در نظر گرفته می شود و مشابه الگوریتم K Means عملیات خوشه بندی انجام می شود. به این ترتیب خوشه انتخاب شده به دو خوشه شکسته می شود. این عملیات با K-1 بار تکرار درون حلقه، K خوشه بدست می آورد. شبه کد الگوریتم Bi-Section-K Means به صورت زیر می باشد: Input: The Number Of K Desired Clusters. Output: A partitioning of the set D of documents. (1)Let P :={ D}. (2)For I :=1 to K-1 do Select p ∈ P with maximal cardinality. Choose randomly two data points in p as starting centroids tp1 and tp2. Assign each point of p to the closest centroid , splitting thus p in two clusters p1 and p2. (Re-)Calculate the cluster centroids tp1 and tp2 of p1 and p2. Repeat the last two steps until the centroids do not change anymore. Let P:=(P\{p}U{p1,p2}. بعد انجام خوشه بندی باید رویه و معیاری برای ارزیابی كیفیت خوشه های بدست آمده، تعریف گردد. روشهای متفاوتی در این زمینه وجود دارد . بیشتر معیارهای موجود براساس دقت و یادآوری هستند. دقت مشخص میكند كه چه میزان از مستندات بدست آمده، درست انتخاب شده و مناسب هستند. یادآوری مشخص می نماید كه چه میزانی از مستندات مناسب انتخاب شده اند. مشكلی كه در این زمینه وجود دارد نسبت عكس مقادیر دقت و یادآوری است. یادآوری، تابعی غیرنزولی از تعداد متن هایی است كه انتخاب می شود. و بر عكس دقت، با افزایش تعداد مستندات انتخاب شده در خوشه پایین می آید. هدف رسیدن به رابطه ای است كه بتواند تعادل مناسبی میان این دو متغیر برقرار سازد. 7) خوشه بندی مستندات متنی با کمک از آنتولوژی الگوریتم های خوشه بندی موجود ارتباط مستندات متنی را تنها از طریق مشابهت مجموعه اصطلاحات آنها با یکدیگر تشخیص می دهند. پس این روش ها کاری به شباهت مفهومی عبارات آنها یا ارتباط معنایی بین عباراتی که از لحاظ لغوی با هم تفاوت می کنند، ندارند. ایده اصلی، ایجاد یک تکنیک جدید خوشه بندی جامع می باشد به طوری که از توصیفات مناسب موجود در دانش پس زمینه استفاده نماید. تعریف هسته آنتولوژی : یک هسته آنتولوژی یک سیستم نشان گذاری است که با نماد O := (L,F,C,H,ROOT) مشخص می شود و شامل بخش های زیر است: 1) یک لغت نامه، L که شامل مجموعه لغات است. 2) یک مجموعه از مفاهیم ، C 3) یک تابع ارجاع ( RefC(t) ) تابع ارجاع یک یا چند کلمه از لغت نامه ({Li L}) را به چند مفهوم معادل کلمات ورودی، نگاشت می دهد .(F: 2L → 2C) در حالت کلی یک کلمه به چندین مفهوم ارجاع می شود و به طور مشابه یک مفهوم هم می تواند به چندین کلمه ارجاع داشته باشد. تابع معکوس F به صورت F- 1 تعریف می شود. 4) سلسله مراتب H ، مفاهیم در آنتولوژی با یک رابطه جهتدار، بدون سیکل، تعدی و انعکاسی طبقه بندی می شوند. H(HOTEL, ACCOMODATION) یعنی مفهوم HOTEL زیرمفهومی از ACCOMODATION است. 5) یک مفهوم سطح بالا به نام ریشه (Root L ) بطوری که برای هر مفهوم (C L )داشته باشیم: H(C,ROOT). 8) کامپایل کردن دانش پس زمینه درون متن دانش پس زمینه را می توان از طریق یک آنتولوژی مرجع مثل WordNet استخراج نمود. دو مشکل اساسی برای مجتمع سازی دانش و کامپایل دانش پس زمینه درون پروسه خوشه بندی متن وجود دارد : ۱- نیاز به پیش پردازش مستندات متنی، برای غنی کردن آنها بوسیله دانش پس زمینه درون هسته آنتولوژی نیاز تحمل سربار پیش پردازش مستندات، داریم. برخی از عملیات متداول پیش پردازش در بخش قبل توضیح داده شد. ۲- می خواهیم تعداد زیادی از مستندات را درون تعداد نسبتا کمی خوشه معنادار تقسیم بندی نماییم، که احتمالا نیاز به تحلیل خوشه بندی مفهومی دارد. خوشه بندی های مفهومی شناخته شده برای اینکه مستقیمًا (بدون واسطه) بخواهند صدها متن را خوشه بندی نمایند، بسیار کند هستند. این روشها اجازه می دهند تا توصیفات مشخصه های مشترک متن ها را خلاصه سازی نماییم و خوشه های مختلف را از هم جدا کنیم. با استفاده از دانش پس زمینه حتی می توان انتزاع ها را نیز پیدا نمود مثلا corn یا beef به جای food . غنی کردن بردارهای کلمه با مفاهیمی که از هسته آنتولوژی استخراج می شود، دو فایده اساسی دارد. اول اینکه مشکل کلمات مترادف حل می شود و دوم اینکه معرفی و استفاده نمودن از مفاهیم کلی و سطح بالاتر می تواند کلمات بردار را به موضوع اصلی متن نزدیک تر نماید. برای مثال الگوریتم های خوشه بندی نمی توانند رابطه ای بین دو کلمه beef و pork در بردار کلمه دو متن پیدا نمایند. حال اگر از مفهوم سطح بالای meat به جای pork در بردار کلمه دو متن استفاده می کردیم، رابطه معنایی دو متن به راحتی قابل تشخیص بود. 9) استراتژی های استفاده از کلمه در مقابل مفهوم استراتژی های متفاوتی از قبیل استراتژی افزودن ، استراتژی جایگزین نمودن و استراتژی محض برای افزودن و یا جایگزینی مفاهیم به جای کلمات وجود دارد. در استراتژی افزودن تمام مفاهیم معادل هر کلمه در آنتولوژی به را نیز بردار کلمات آن متن افزوده می شود. (مثلا همراه با کلمه beef مفهوم meat در بردار کلمات تکرار می نماید.) در استراتژی جایگزین نمودن عبارتهایی که مفهوم مرتبط با آنها وجود دارد را با مفاهیم معادلشان جایگزین می نماید. (مثلا به جای beef مفهوم Meat را می آورد.) در استراتژی محض مشابه استراتژی جایگزین عمل می کنیم با این تفاوت که کلماتی که مفهوم معادل آنها در آنتولوژی( مثل WordNet)وجود ندارد را از متن حذف می نماییم. پس برای چنین کلماتی مولفه ای در بردار کلمات در نظر گرفته نمی شود. 10) نتیجه گیری استفاده از آنتولوژی ها برای جای دادن و افزودن مفاهیم سطح بالاتر و نزدیک تر به موضوع اصلی متن، باعث غنی تر شدن مستندات متنی می شوند. همچنین این عملیات بسیاری از ابهام ها مانند جایگزین کردن مفهوم اصلی کلماتی که معانی مختلفی دارند یا ادغام کلمات مترادف و دیگر ابهام های احتمالی را رفع می نماید. پس استفاده ازآنتولوژی ها در عملیات پیش پردازش مستندات متنی و کامپایل نمودن دانش پس زمینه درون مستندات متنی می توانند تا حد بسزایی به کیفیت خوشه بندی مستندات متنی کمک نمایند. |
|
|
|
| از Astaraki تشكر كرده اند: | andromeda (۰۹-۲۸-۱۳۸۸), dr_bijan (۰۹-۲۵-۱۳۹۲), farshad1362 (۰۹-۱۰-۱۳۹۰), hamedmehdihamed (۱۲-۲۶-۱۳۹۰), kapricorn (۰۵-۱۸-۱۳۸۹), mardin200 (۰۹-۲۰-۱۳۸۸), neda2 (۱۱-۵-۱۳۸۸), shahak (۱۲-۸-۱۳۸۸) |
|
۰۴-۱۰-۱۳۹۳, ۰۵:۲۷ قبل از ظهر
|
#8 (لینک دائم) |
|
عضو جدید
 
تاريخ عضويت: تير ۱۳۹۳
پست ها: 3
تشكرها: 0
0 تشكر در 0 پست
|
باسلام و تشکر از محتویات جالب سایتتون
من اطلاعاتی از ساعات مختلف حضور ساکن در یک اتاق( به صورت بازه زمانی مثل 8:30 -11:00 , 12:00- 3:20 و... برای هر روز) در طول یک ماه را دارم. حال می خواهم الگوی حضور ساکن را استخراج کنم تا بتوانم از آن برای پیش بینی ساعات حضور ساکن استفاده کنم. آیا از روش کلاسترینگ فازی می توانم این کار را انجام دهم؟ لطفا راهنماییم کنید. با تشکر |
|
|
|
|
۰۴-۱۸-۱۳۹۳, ۰۱:۴۱ بعد از ظهر
|
#9 (لینک دائم) | |
|
عضو فعال
تاريخ عضويت: تير ۱۳۹۳
پست ها: 15
تشكرها: 0
5 تشكر در 5 پست
|
نقل قول:
در این صورت ساده ترین راه پیدا کردن هیستوگرام ساعات حضوره. ساعت ها رو گسسته کن و تعداد حضور در هر بازه رو بشمار. بعدش پیک های هیستوگرام رو پیدا کن میتونی کلاسترینگ استفاده کنی. ولی اگه داده ها الگوی مشخص نداشته باشند جواب نامربوط میگیری. برای کلاسترینگ باید معیار فاصله بین دو بازه زمانی تعریف کنی. معیاری که اشتراک زیاد رو ترجیح بده |
|
|
|
|
|
| كاربران در حال ديدن تاپيک: 1 (0 عضو و 1 مهمان) | |
 Linear Mode
Linear Mode

|
|

زمان محلي شما با تنظيم GMT +3.5 هم اکنون ۰۶:۱۴ قبل از ظهر ميباشد.





