Ш§ЩҶШ¬Щ…ЩҶ ШұШ§ ШҜШұ ЪҜЩҲЪҜЩ„ Щ…ШӯШЁЩҲШЁ Ъ©ЩҶЩҠШҜ :
|
|||||||


| Ш«ШЁШӘ ЩҶШ§Щ… | Ш§ШұШіШ§Щ„ ШҜШ№ЩҲШӘЩҶШ§Щ…ЩҮ ШЁЩҮ ШҜЩҲШіШӘШ§ЩҶ ! | ШұШ§ЩҮЩҶЩ…Ш§ЩҠ ШіШ§ЩҠШӘ | Community | ШӘЩӮЩҲЩҠЩ… | Ш§ШұШіШ§Щ„ЩҮШ§ЩҠ Ш§Щ…ШұЩҲШІ | Ш¬ШіШӘШ¬ЩҲ |
| ШӘШЁЩ„ЩҠШәШ§ШӘ ШіШ§ЩҠШӘ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  |
|
|
LinkBack | Ш§ШЁШІШ§ШұЩҮШ§ЩҠ ШӘШ§ЩҫЩҠЪ© | ЩҶШӯЩҲЩҮ ЩҶЩ…Ш§ЩҠШҙ |
 Ы°Ыё-ЫұЫІ-ЫұЫіЫёЫё, ЫұЫұ:Ы°Ы° ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
Ы°Ыё-ЫұЫІ-ЫұЫіЫёЫё, ЫұЫұ:Ы°Ы° ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#1 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Administrator
 
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш®ШұШҜШ§ШҜ ЫұЫіЫёЫ·
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ-Ъ©ШұШ¬!
ЩҫШіШӘ ЩҮШ§: 3,465
ШӘШҙЩғШұЩҮШ§: 754
16,339 ШӘШҙЩғШұ ШҜШұ 3,127 ЩҫШіШӘ
My Mood:

 |
ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ЩҠ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲЩҠ
Ш·ЩҠ ШіШ§Щ„вҖҢЩҮШ§ЩҠ ЪҜШ°ШҙШӘЩҮ Ш¬ШұЩҠШ§ЩҶ ШіШұЩҠШ№ЩҠ Ш§ШІ ШӘЩ…Ш§ЩҠЩ„ ШЁЩҮ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲЩҠ ШҜШұ ШЁШ§ШІШ§ШұЩҮШ§ЩҠ ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҠ ШЁЩҮ ЩҲШ¬ЩҲШҜ ШўЩ…ШҜЩҮ Ш§ШіШӘ. ШЁЩҠШҙШӘШұ ЩғШ§ШұШЁШұШ§ЩҶ ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ЩҠ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲ ШЁШ§ ШӘЩҒЩғШұ Ш§ШіШӘЩҒШ§ШҜЩҮ ШӘШ¬Ш§ШұЩҠ Ш§ШІ Ш§ЩҠЩҶ ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ШҢ Ш®ЩҲШ§ЩҮШ§ЩҶ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШўЩҶ ШҙШҜЩҮвҖҢШ§ЩҶШҜ. ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ЩҠ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲЩҠ Щ…Ш№Щ…ЩҲЩ„Ш§ЩӢ ШіЩҮ ШұЩҲШҙ Щ…Ш®ШӘЩ„ЩҒ ШұШ§ ШЁШұШ§ЩҠ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲЩҠ ШЁЩҮ ЩғШ§Шұ Щ…ЩҠвҖҢШЁШұЩҶШҜ. 1) Ш§ЩғШӘШҙШ§ЩҒ 2) Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Щ…ШҜЩ„вҖҢЩҮШ§ЩҠ ЩҫЩҠШҙЪҜЩҲЩҠЩҠ 3) Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШўЩҶШ§Щ„ЩҠШІ ШЁШӯШ« ЩҲ Ш¬ШҜЩ„. Ш§ЩғШӘШҙШ§ЩҒШҢ ЩҒШұШўЩҠЩҶШҜ Ш¬ШіШӘШ¬ЩҲ ШҜШұ ШҜШ§ШҜЩҮвҖҢЩҮШ§ШіШӘ ШӘШ§ Ш§Щ„ЪҜЩҲЩҮШ§ЩҠ Щ…Ш®ЩҒЩҠ Щ…ЩҲШ¬ЩҲШҜ ШҜШұ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ШұШ§ ШЁШҜЩҲЩҶ ЩҮЩҠЪҶ Ш§ЩҠШҜШ© Ш§ШІ ЩҫЩҠШҙ ШӘШ№ЩҠЩҠЩҶ ШҙШҜЩҮвҖҢШ§ЩҠ Щ…ШҙШ®Шө ЩҶЩ…Ш§ЩҠШҜ. ШҜШұ ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ЩҠ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲЩҠ Щ…ШЁШӘЩҶЩҠ ШЁШұ Щ…ШҜЩ„вҖҢЩҮШ§ЩҠ ЩҫЩҠШҙЪҜЩҲЩҠЩҠШҢ Ш§Щ„ЪҜЩҲЩҮШ§ЩҠЩҠ ЩғЩҮ Ш§ШІ ЩҠЩғ ШЁШ§ЩҶЩғ ШҜШ§ШҜЩҮ ЩғШҙЩҒ Щ…ЩҠвҖҢШҙЩҲЩҶШҜШҢ ШЁШұШ§ЩҠ ЩҫЩҠШҙвҖҢШЁЩҠЩҶЩҠ ШўЩҠЩҶШҜЩҮ ШЁЩҮ ЩғШ§Шұ Щ…ЩҠвҖҢШұЩҲЩҶШҜ. Щ…ШҜЩ„вҖҢЩҮШ§ЩҠ ЩҫЩҠШҙвҖҢШЁЩҠЩҶЩҠ ШЁЩҮ ЩғШ§ШұШЁШұ Ш§Ш¬Ш§ШІЩҮ Щ…ЩҠвҖҢШҜЩҮЩҶШҜ ШӘШ§ ШҜШ§ШҜЩҮвҖҢЩҮШ§ЩҠ ЩҶШ§Щ…ШҙШ®Шө ШұШ§ ШЁЩҮ ЩғШ§Шұ ШЁШЁШұШҜ ЩҲ Ш§ЩҠЩҶ Щ…ЩӮШ§ШҜЩҠШұ ЩҶШ§Щ…ШҙШ®Шө ШӘЩҲШіШ· ЩҶШұЩ…вҖҢШ§ЩҒШІШ§Шұ ЩғШҙЩҒ ШҙЩҲШҜ. ШҜШұ Щ…ШҜЩ„вҖҢЩҮШ§ЩҠ Ш¬ШҜЩ„ЩҠ ЩҶЩҠШІ Ш§Щ„ЪҜЩҲЩҮШ§ЩҠ ЩҠШ§ЩҒШӘ ШҙШҜЩҮ Ш§ШІ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ШЁШұШ§ЩҠ ШӘШ№ЩҠЩҠЩҶ Щ…ЩӮШ§ШҜЩҠШұ ШәЩҠШұШ№Ш§ШҜЩҠ ШЁЩҮ ЩғШ§Шұ Щ…ЩҠвҖҢШұЩҲШҜ. ШЁШұШ§ЩҠ ШӘШ№ЩҠЩҠЩҶ Щ…ЩӮШ§ШҜЩҠШұ ШәЩҠШұ Ш№Ш§ШҜЩҠШҢ Ш§ШЁШӘШҜШ§ Щ…ЩҠвҖҢШЁШ§ЩҠШіШӘ Щ…ЩӮШ§ШҜЩҠШұ Ш№Ш§ШҜЩҠ ШҙЩҶШ§Ш®ШӘЩҮ ШҙЩҲШҜ ШӘШ§ ШЁШұ Ш§ЩҠЩҶ Ш§ШіШ§Ші Щ…ЩӮШ§ШҜЩҠШұ ШәЩҠШұШ№Ш§ШҜЩҠ ЩҲ Щ…ЩҶШӯШұЩҒ ШҙЩҶШ§Ш®ШӘЩҮ ШҙЩҲЩҶШҜ. ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ЩҠ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲ ШҜШұ ШӯШ§Щ„ ШӯШ§Ш¶Шұ Ш§ШІ ЩҒШ№Ш§Щ„ЩҠШӘвҖҢ ЩғЩ…ШӘШұЩҠ ЩҶШіШЁШӘ ШЁЩҮ ШіШ§ЩҠШұ ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ЩҠ ЩҮЩҲШҙЩ…ЩҶШҜ ШЁШұШ®ЩҲШұШҜШ§Шұ ЩҮШіШӘЩҶШҜ. ШЁШ§ Ш§ЩҠЩҶ ЩҲШ¬ЩҲШҜ ЩҒШ№Ш§Щ„ЩҠШӘ ШӘШ¬Ш§ШұЩҠ Ш§ЩҠЩҶ ЩҶШұЩ…вҖҢШ§ЩҒШІШ§Шұ ШұШ§ Щ…ЩҠвҖҢШӘЩҲШ§ЩҶ ШҜШұ ШҙШҙ ШЁШ®Шҙ ЩғЩ„ЩҠШҢ ШҜШіШӘЩҮвҖҢШЁЩҶШҜЩҠ ШҜШ§ШҜЩҮвҖҢЩҮШ§ШҢ ШЁШұШўЩҲШұШҜ Щ…ЩӮШ§ШҜЩҠШұ ЩҶШ§Щ…ШҙШ®ШөШҢ ЩҫЩҠШҙвҖҢШЁЩҠЩҶЩҠ Щ…ЩӮШ§ШҜЩҠШұ ЩҶШ§Щ…ШҙШ®Шө, ЪҜШұЩҲЩҮвҖҢШЁЩҶШҜЩҠ ШӘЩӮШұЩҠШЁЩҠ ШҜШ§ШҜвҖҢЩҮвҖҢЩҮШ§ШҢ Ш®ЩҲШҙЩҮвҖҢШЁЩҶШҜЩҠ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ЩҲ ШӘШҙШұЩҠШӯ ШұЩҲШ§ШЁШ· ШЁЩҠЩҶ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ШӘЩӮШіЩҠЩ… ЩғШұШҜ |

|

|


| #ADS | |
|
ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ ШӘШЁЩ„ЫҢШәШ§ШӘ
ШӘШЁЩ„ЩҠШәЪҜШұ
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: -
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: -
ШіЩҶ: 2010
ЩҫШіШӘ ЩҮШ§: -
|
|

|
|
Ы°Ыё-ЫұЫІ-ЫұЫіЫёЫё, ЫұЫұ:Ы°ЫІ ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#2 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Administrator
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш®ШұШҜШ§ШҜ ЫұЫіЫёЫ·
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ-Ъ©ШұШ¬!
ЩҫШіШӘ ЩҮШ§: 3,465
ШӘШҙЩғШұЩҮШ§: 754
16,339 ШӘШҙЩғШұ ШҜШұ 3,127 ЩҫШіШӘ
My Mood:
|
Щ…Ш№ШұЩҒЫҢ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ШҜШ§ШҜЩҮ Ъ©Ш§ЩҲЫҢ SPSS Clementime
 ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ШҜШ§ШҜЩҮ Ъ©Ш§ЩҲЫҢ SPSS Clementine ЫҢЪ©ЫҢ Ш§ШІ Щ…Ш·ШұШӯ ШӘШұЫҢЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§ШұЩҮШ§ ШҜШұ ШІЩ…ЫҢЩҶЩҮ ШҜШ§ШҜЩҮ Ъ©Ш§ЩҲЫҢ Ш§ШіШӘ. Ш§ЫҢЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ Ш§ШІ ШіШұЫҢ ЩҶШұЩ… Ш§ЩҒШІШ§ШұЩҮШ§ЫҢ Щ…Ш№ШұЩҲЩҒ SPSS ШЁЩҲШҜЩҮ ЩҲ Щ…Ш§ЩҶЩҶШҜ ЩҶШұЩ… Ш§ЩҒШІШ§ШұЩҮШ§ЫҢ ШўЩ…Ш§ШұЫҢ ЩӮШЁЩ„ЫҢ Ш§ШІ Ш§Щ…Ъ©Ш§ЩҶШ§ШӘ ШЁШіЫҢШ§Шұ ШІЫҢШ§ШҜЫҢ ШҜШұ ШІЩ…ЫҢЩҶЩҮ ШӘШӯЩ„ЫҢЩ„ ШҜШ§ШҜЩҮ ЩҮШ§ ШЁШұШ®ЩҲШұШҜШ§Шұ Ш§ШіШӘ. ШўШ®ШұЫҢЩҶ ЩҶШіШ®ЩҮ Ш§ЫҢЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ 12 Ш§ШіШӘ Ъ©ЩҮ ЩҫШі Ш§ШІ Ш§ЩҶШӘШҙШ§Шұ Ш§ЫҢЩҶ ЩҶШіШ®ЩҮШҢЩҶШіШ®ЩҮ ШЁШ№ШҜЫҢ ШЁШ§ ЩҶШ§Щ… PASW Modeler Щ…ЩҶШӘШҙШұ ШҙШҜ. Ш§ШІ Щ…ШІШ§ЫҢШ§ЫҢ Ш§ЫҢЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ Щ…ЫҢ ШӘЩҲШ§ЩҶ ШЁЩҮ Щ…ЩҲШ§ШұШҜ ШІЫҢШұ Ш§ШҙШ§ШұЩҮ ЩҶЩ…ЩҲШҜ: - ШҜШ§ШҙШӘЩҶ ШұЩҲШҙ ЩҮШ§ЫҢ ШЁШіЫҢШ§Шұ Щ…ШӘЩҶЩҲШ№ ШЁШұШ§ЫҢ ШӘШӯЩ„ЫҢЩ„ ШҜШ§ШҜЩҮ ЩҮШ§ - ШіШұШ№ШӘ ШЁШіЫҢШ§Шұ ШЁШ§Щ„Ш§ ШҜШұ Ш§ЩҶШ¬Ш§Щ… Щ…ШӯШ§ШіШЁШ§ШӘ ЩҲ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ЩҫШ§ЫҢЪҜШ§ЩҮ ШҜШ§ШҜЩҮ ЩҮШ§ - ШҜШ§ШҙШӘЩҶ Щ…ШӯЫҢШ· ЪҜШұШ§ЩҒЫҢЪ©ЫҢ ШЁЩҮ Щ…ЩҶШёЩҲШұ ШұШ§ШӯШӘЫҢ ШЁЫҢШҙШӘШұ Ъ©Ш§ШұШЁШұ ШЁШұШ§ЫҢ Ш§ЩҶШ¬Ш§Щ… Ъ©Ш§ШұЩҮШ§ЫҢ ШӘШӯЩ„ЫҢЩ„ЫҢ ШҜШұ ЩҶШіШ®ЩҮ Ш¬ШҜЫҢШҜ Ш§Щ…Ъ©Ш§ЩҶ ЩҫШ§Ъ© ШіШ§ШІЫҢ ЩҲ ШўЩ…Ш§ШҜЩҮ ШіШ§ШІЫҢ ШҜШ§ШҜЩҮ ЩҮШ§ ШЁЩҮ ШөЩҲШұШӘ Ъ©Ш§Щ…Щ„Ш§ЩӢ Ш§ШӘЩҲЩ…Ш§ШӘЫҢЪ© Ш§ЩҶШ¬Ш§Щ… Щ…ЫҢ ШҙЩҲШҜ. Ш§ЫҢЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ШӘЩ…Ш§Щ…ЫҢ ЩҶШұЩ… Ш§ЩҒШІШ§ШұЩҮШ§ЫҢ ЩҫШ§ЫҢЪҜШ§ЩҮ ШҜШ§ШҜЩҮ Щ…Ш№ШұЩҲЩҒ Щ…Ш§ЩҶЩҶШҜ Microsoft Office ЩҲ SQL ЩҲ вҖҰ ШұШ§ ЩҫШҙШӘЫҢШЁШ§ЩҶЫҢ Щ…ЫҢ Ъ©ЩҶШҜ. Щ…Ш§ЪҳЩҲЩ„ ЩҮШ§ЫҢ Щ…ЩҲШ¬ЩҲШҜ ШҜШұ Ш§ЫҢЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ Ш№ШЁШ§ШұШӘЩҶШҜ Ш§ШІ: - PASW Association - PASW Classification - PASW Segmentation - PASW Modeler Solution Publisher Ш§ЫҢЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ЩҮЩ… ШЁШұ ШұЩҲЫҢ Ъ©Ш§Щ…ЩҫЫҢЩҲШӘШұ ШҙШ®ШөЫҢ ЩҲ ЩҮЩ… ШЁШұ ШұЩҲЫҢ ШіШұЩҲШұ ЩӮШ§ШЁЩ„ ЩҶШөШЁ Ш§ШіШӘ ЩҲ Ш§ШІ Windows ЩҮШ§ЫҢ 32 ЩҲ 64 ШЁЫҢШӘЫҢ ЩҶЫҢШІ ЩҫШҙШӘЫҢШЁШ§ЩҶЫҢ Щ…ЫҢ Ъ©ЩҶШҜ |
|
|
|
|
Ы°Ыё-ЫұЫІ-ЫұЫіЫёЫё, ЫұЫұ:Ы°Ы¶ ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#3 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Administrator
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш®ШұШҜШ§ШҜ ЫұЫіЫёЫ·
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ-Ъ©ШұШ¬!
ЩҫШіШӘ ЩҮШ§: 3,465
ШӘШҙЩғШұЩҮШ§: 754
16,339 ШӘШҙЩғШұ ШҜШұ 3,127 ЩҫШіШӘ
My Mood:
|
ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ШҜШ§ШҜЩҮ ЩғШ§ЩҲЩҠ Weka
1-Щ…ЩӮШҜЩ…ЩҮ ШӘШ§ ШЁЩҮ Ш§Щ…ШұЩҲШІ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ЩҮШ§ЩҠ ШӘШ¬Ш§ШұЩҠ ЩҲ ШўЩ…ЩҲШІШҙЩҠ ЩҒШұШ§ЩҲШ§ЩҶЩҠ ШЁШұШ§ЩҠ ШҜШ§ШҜЩҮ ЩғШ§ЩҲЩҠ ШҜШұ ШӯЩҲШІЩҮ ЩҮШ§ЩҠ Щ…Ш®ШӘЩ„ЩҒ ШҜШ§ШҜЩҮ ЩҮШ§ ШЁЩҮ ШҜЩҶЩҠШ§ЩҠ Ш№Щ„Щ… ЩҲ ЩҒЩҶШ§ЩҲШұЩҠ Ш№ШұШ¶ЩҮ ШҙШҜЩҮ Ш§ЩҶШҜ. ЩҮШұЩҠЩғ Ш§ШІ ШўЩҶЩҮШ§ ШЁШ§ ШӘЩҲШ¬ЩҮ ШЁЩҮ ЩҶЩҲШ№ Ш§ШөЩ„ЩҠ ШҜШ§ШҜЩҮ ЩҮШ§ЩҠЩҠ ЩғЩҮ Щ…ЩҲШұШҜ ЩғШ§ЩҲШҙ ЩӮШұШ§Шұ Щ…ЩҠ ШҜЩҮЩҶШҜШҢ ШұЩҲЩҠ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ЩҮШ§ЩҠ Ш®Ш§ШөЩҠ Щ…ШӘЩ…ШұЩғШІ ШҙШҜЩҮ Ш§ЩҶШҜ. Щ…ЩӮШ§ЩҠШіЩҮ ШҜЩӮЩҠЩӮ ЩҲ Ш№Щ„Щ…ЩҠ Ш§ЩҠЩҶ Ш§ШЁШІШ§ШұЩҮШ§ ШЁШ§ЩҠШҜ Ш§ШІ Ш¬ЩҶШЁЩҮ ЩҮШ§ЩҠ Щ…ШӘЩҒШ§ЩҲШӘ ЩҲ Щ…ШӘШ№ШҜШҜЩҠ Щ…Ш§ЩҶЩҶШҜ ШӘЩҶЩҲШ№ Ш§ЩҶЩҲШ§Ш№ ЩҲ ЩҒШұЩ…ШӘ ШҜШ§ШҜЩҮ ЩҮШ§ЩҠ ЩҲШұЩҲШҜЩҠШҢ ШӯШ¬Щ… Щ…Щ…ЩғЩҶ ШЁШұШ§ЩҠ ЩҫШұШҜШ§ШІШҙ ШҜШ§ШҜЩҮ ЩҮШ§ШҢ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ЩҮШ§ ЩҫЩҠШ§ШҜЩҮ ШіШ§ШІЩҠ ШҙШҜЩҮШҢ ШұЩҲШҙЩҮШ§ЩҠ Ш§ШұШІЩҠШ§ШЁЩҠ ЩҶШӘШ§ЩҠШ¬ШҢ ШұЩҲШҙЩҮШ§ЩҠ Щ…ШөЩҲШұ ШіШ§ШІЩҠ [1] ШҢ ШұЩҲШҙЩҮШ§ЩҠ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙ [2] ШҜШ§ШҜЩҮ ЩҮШ§ШҢ ЩҲШ§ШіШ·ЩҮШ§ЩҠ ЩғШ§ШұШЁШұ ЩҫШіЩҶШҜ [3] ШҢ ЩҫЩ„ШӘ ЩҒШұЩ… [4] ЩҮШ§ЩҠ ШіШ§ШІЪҜШ§Шұ ШЁШұШ§ЩҠ Ш§Ш¬ШұШ§ШҢвҖҢ ЩӮЩҠЩ…ШӘ ЩҲ ШҜШұ ШҜШіШӘШұШі ШЁЩҲШҜЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ШөЩҲШұШӘ ЪҜЩҠШұШҜ. Ш§ШІ ШўЩҶ Щ…ЩҠШ§ЩҶШҢ вҖҢЩҶШұЩ… Ш§ЩҒШІШ§Шұ Weka ШЁШ§ ШҜШ§ШҙШӘЩҶ Ш§Щ…ЩғШ§ЩҶШ§ШӘ ШЁШіЩҠШ§Шұ ЪҜШіШӘШұШҜЩҮШҢвҖҢ Ш§Щ…ЩғШ§ЩҶ Щ…ЩӮШ§ЩҠШіЩҮ Ш®ШұЩҲШ¬ЩҠ ШұЩҲШҙЩҮШ§ЩҠ Щ…Ш®ШӘЩ„ЩҒ ШЁШ§ ЩҮЩ…ШҢ ШұШ§ЩҮЩҶЩ…Ш§ЩҠ Ш®ЩҲШЁШҢ ЩҲШ§ШіШ· ЪҜШұШ§ЩҒЩҠЪҜЩҠ ЩғШ§ШұШўШҢ ШіШ§ШІЪҜШ§ШұЩҠ ШЁШ§ ШіШ§ЩҠШұ ШЁШұЩҶШ§Щ…ЩҮ ЩҮШ§ЩҠ ЩҲЩҠЩҶШҜЩҲШІЩҠШҢ ЩҲ Ш§ШІ ЩҮЩ…ЩҮ Щ…ЩҮЩ…ШӘШұ ЩҲШ¬ЩҲШҜ ЩғШӘШ§ШЁЩҠ ШЁШіЩҠШ§Шұ Ш¬Ш§Щ…Ш№ ЩҲ Щ…ШұШӘШЁШ· ШЁШ§ ШўЩҶ [ Data Mining, witten et Al. 2005 ] ШҢ Щ…Ш№ШұЩҒЩҠ Щ…ЩҠ ШҙЩҲШҜ. Щ…ЩҠШІЩғШ§Шұ [5] Weka ШҢ Щ…Ш¬Щ…ЩҲШ№ЩҮ Ш§ЩҠ Ш§ШІ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ШұЩҲШІ ЩҠШ§ШҜЪҜЩҠШұЩҠ Щ…Ш§ШҙЩҠЩҶЩҠ ЩҲ Ш§ШЁШІШ§ШұЩҮШ§ЩҠ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. Ш§ЩҠЩҶ ЩҶШұЩ…ВӯШ§ЩҒШІШ§Шұ ШЁЩҮ ЪҜЩҲЩҶЩҮ Ш§ЩҠ Ш·ШұШ§ШӯЩҠ ШҙШҜЩҮ Ш§ШіШӘ ЩғЩҮ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШЁЩҮ ШіШұШ№ШӘШҢ ШұЩҲШҙ вҖҸЩҮШ§ЩҠ Щ…ЩҲШ¬ЩҲШҜ ШұШ§ ШЁЩҮ ШөЩҲШұШӘ Ш§ЩҶШ№Ш·Ш§ЩҒ ЩҫШ°ЩҠШұЩҠ ШұЩҲЩҠ Щ…Ш¬Щ…ЩҲШ№ЩҮ вҖҸЩҮШ§ЩҠ Ш¬ШҜЩҠШҜ ШҜШ§ШҜЩҮШҢ ШўШІЩ…Ш§ЩҠШҙ ЩҶЩ…ЩҲШҜ. Ш§ЩҠЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§ШұШҢ ЩҫШҙШӘЩҠШЁШ§ЩҶЩҠвҖҸвҖҸЩҮШ§ЩҠ Ш§ШұШІШҙЩ…ЩҶШҜЩҠ ШұШ§ ШЁШұШ§ЩҠ ЩғЩ„ ЩҒШұШўЩҠЩҶШҜ ШҜШ§ШҜЩҮ ЩғШ§ЩҲЩҠ вҖҸЩҮШ§ЩҠ ШӘШ¬ШұШЁЩҠ ЩҒШұШ§ЩҮЩ… Щ…ЩҠвҖҸ ЩғЩҶШҜ. Ш§ЩҠЩҶ ЩҫШҙШӘЩҠШЁШ§ЩҶЩҠвҖҸЩҮШ§ШҢ ШўЩ…Ш§ШҜЩҮ ШіШ§ШІЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ЩҠ ЩҲШұЩҲШҜЩҠШҢ Ш§ШұШІЩҠШ§ШЁЩҠ ШўЩ…Ш§ШұЩҠ ЪҶШ§ШұЪҶЩҲШЁ вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩҲ ЩҶЩ…Ш§ЩҠШҙ ЪҜШұШ§ЩҒЩҠЩғЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ЩҠ ЩҲШұЩҲШҜЩҠ ЩҲ ЩҶШӘШ§ЩҠШ¬ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШұШ§ ШҜШұ ШЁШұ Щ…ЩҠ ЪҜЩҠШұЩҶШҜ. ЩҮЩ…ЪҶЩҶЩҠЩҶШҢ ЩҮЩ…Ш§ЩҮЩҶЪҜ ШЁШ§ ШҜШ§Щ…ЩҶЩҮ ЩҲШіЩҠШ№ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠШҢ Ш§ЩҠЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ШҙШ§Щ…Щ„ Ш§ШЁШІШ§ШұЩҮШ§ЩҠ Щ…ШӘЩҶЩҲШ№ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙ ШҜШ§ШҜЩҮ ЩҮШ§ШіШӘ. Ш§ЩҠЩҶ Ш¬Ш№ШЁЩҮ Ш§ШЁШІШ§Шұ [6] Щ…ШӘЩҶЩҲШ№ ЩҲ Ш¬Ш§Щ…Ш№ШҢ Ш§ШІ Ш·ШұЩҠЩӮ ЩҠЩғ ЩҲШ§ШіШ· Щ…ШӘШҜШ§ЩҲЩ„ ШҜШұ ШҜШіШӘШұШі Ш§ШіШӘШҢ ШЁЩҮ ЩҶШӯЩҲЩҠ ЩғЩҮ ЩғШ§ШұШЁШұ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШұЩҲШҙ вҖҸЩҮШ§ЩҠ Щ…ШӘЩҒШ§ЩҲШӘ ШұШ§ ШҜШұ ШўЩҶ ШЁШ§ ЩҠЩғШҜЩҠЪҜШұ Щ…ЩӮШ§ЩҠШіЩҮ ЩғЩҶШҜ ЩҲ ШұЩҲШҙ вҖҸЩҮШ§ЩҠЩҠ ШұШ§ ЩғЩҮ ШЁШұШ§ЩҠ Щ…ШіШ§ЩҠЩ„ Щ…ШҜЩҶШёШұ Щ…ЩҶШ§ШіШЁ ШӘШұ ЩҮШіШӘЩҶШҜШҢ ШӘШҙШ®ЩҠШө ШҜЩҮШҜ. ЩҶШұЩ… Ш§ЩҒШІШ§Шұ Weka ШҜШұ ШҜШ§ЩҶШҙЪҜШ§ЩҮ Waikato ЩҲШ§ЩӮШ№ ШҜШұ ЩҶЩҠЩҲШІЩ„ЩҶШҜ ШӘЩҲШіШ№ЩҮ ЩҠШ§ЩҒШӘЩҮ Ш§ШіШӘ ЩҲ Ш§ШіЩ… ШўЩҶ Ш§ШІ Ш№ШЁШ§ШұШӘ "Waikato Environment for knowledge Analysis" Ш§ШіШӘШ®ШұШ§Ш¬ ЪҜШҙШӘЩҮ Ш§ШіШӘ. ЩҮЩ…ЪҶЩҶЩҠЩҶ Weka ШҢ ЩҶШ§Щ… ЩҫШұЩҶШҜЩҮ Ш§ЩҠ ШЁШ§ Ш·ШЁЩҠШ№ШӘ Ш¬ШіШӘШ¬ЩҲЪҜШұ Ш§ШіШӘ ЩғЩҮ ЩҫШұЩҲШ§ШІ ЩҶЩ…ЩҠвҖҸ ЩғЩҶШҜ ЩҲ ШҜШұ ЩҶЩҠЩҲШІЩ„ЩҶШҜШҢ ЩҠШ§ЩҒШӘ Щ…ЩҠвҖҸ ШҙЩҲШҜ. Ш§ЩҠЩҶ ШіЩҠШіШӘЩ… ШЁЩҮ ШІШЁШ§ЩҶ Ш¬Ш§ЩҲШ§ ЩҶЩҲШҙШӘЩҮ ШҙШҜЩҮ ЩҲ ШЁШұ Ш§ШіШ§Ші Щ„ЩҠШіШ§ЩҶШі Ш№Щ…ЩҲЩ…ЩҠ ЩҲ ЩҒШұШ§ЪҜЩҠШұ [7] GNU Ш§ЩҶШӘШҙШ§Шұ ЩҠШ§ЩҒШӘЩҮ Ш§ШіШӘ. Weka ШӘЩӮШұЩҠШЁШ§ЩӢ ШұЩҲЩҠ ЩҮШұ ЩҫЩ„ШӘ ЩҒШұЩ…ЩҠ Ш§Ш¬ШұШ§ Щ…ЩҠвҖҸ ШҙЩҲШҜ ЩҲ ЩҶЩҠШІ ШӘШӯШӘ ШіЩҠШіШӘЩ… Ш№Ш§Щ…Щ„ вҖҸЩҮШ§ЩҠ Щ„ЩҠЩҶЩҲЩғШіШҢ ЩҲЩҠЩҶШҜЩҲШІШҢ ЩҲ Щ…ЩғЩҠЩҶШӘШ§ШҙШҢ ЩҲ ШӯШӘЩҠ ШұЩҲЩҠ ЩҠЩғ Щ…ЩҶШҙЩҠ ШҜЩҠШ¬ЩҠШӘШ§Щ„ЩҠ ШҙШ®ШөЩҠ [8] ШҢ ШўШІЩ…Ш§ЩҠШҙ ШҙШҜЩҮ Ш§ШіШӘ. Ш§ЩҠЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§ШұШҢ ЩҠЩғ ЩҲШ§ШіШ· ЩҮЩ…ЪҜЩҲЩҶ ШЁШұШ§ЩҠ ШЁШіЩҠШ§ШұЩҠ Ш§ШІ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ Щ…ШӘЩҒШ§ЩҲШӘШҢ ЩҒШұШ§ЩҮЩ… ЩғШұШҜЩҮ Ш§ШіШӘ ЩғЩҮ Ш§ШІ Ш·ШұЩҠЩӮ ШўЩҶ ШұЩҲШҙ вҖҸЩҮШ§ЩҠ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙШҢ ЩҫШі Ш§ШІ ЩҫШұШҜШ§ШІШҙ [9] ЩҲ Ш§ШұШІЩҠШ§ШЁЩҠ ЩҶШӘШ§ЩҠШ¬ Ш·ШұШӯ ЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШұЩҲЩҠ ЩҮЩ…ЩҮ Щ…Ш¬Щ…ЩҲШ№ЩҮ ЩҮШ§ЩҠ ШҜШ§ШҜЩҮ вҖҸ Щ…ЩҲШ¬ЩҲШҜШҢ ЩӮШ§ШЁЩ„ Ш§Ш№Щ…Ш§Щ„ Ш§ШіШӘ. ЩҶШұЩ… Ш§ЩҒШІШ§Шұ Weka ШҢ ЩҫЩҠШ§ШҜЩҮ ШіШ§ШІЩҠ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ Щ…Ш®ШӘЩ„ЩҒ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШұШ§ ЩҒШұШ§ЩҮЩ… Щ…ЩҠвҖҸ ЩғЩҶШҜ ЩҲ ШЁЩҮ ШўШіШ§ЩҶЩҠ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШўЩҶЩҮШ§ ШұШ§ ШЁЩҮ Щ…Ш¬Щ…ЩҲШ№ЩҮ ЩҮШ§ЩҠ ШҜШ§ШҜЩҮ Ш®ЩҲШҜ Ш§Ш№Щ…Ш§Щ„ ЩғШұШҜ. ЩҮЩ…ЪҶЩҶЩҠЩҶШҢ Ш§ЩҠЩҶ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ ШҙШ§Щ…Щ„ Щ…Ш¬Щ…ЩҲШ№ЩҮ Щ…ШӘЩҶЩҲШ№ЩҠ Ш§ШІ Ш§ШЁШІШ§ШұЩҮШ§ЩҠ ШӘШЁШҜЩҠЩ„ Щ…Ш¬Щ…ЩҲШ№ЩҮ вҖҸЩҮШ§ЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ШҢ ЩҮЩ…Ш§ЩҶЩҶШҜ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ЪҜШіШіШӘЩҮ ШіШ§ШІЩҠ [10] Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. ШҜШұ Ш§ЩҠЩҶ Щ…ШӯЩҠШ· Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ШұШ§ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙ ЩғШұШҜШҢ ШўЩҶ ШұШ§ ШЁЩҮ ЩҠЩғ Ш·ШұШӯ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩҲШ§ШұШҜ ЩҶЩ…ЩҲШҜШҢ ЩҲ ШҜШіШӘЩҮ ШЁЩҶШҜЩҠ ШӯШ§ШөЩ„ЩҮ ЩҲ ЩғШ§ШұШўЩҠЩҠ Ш§Шҙ ШұШ§ Щ…ЩҲШұШҜ ШӘШӯЩ„ЩҠЩ„ ЩӮШұШ§Шұ ШҜШ§ШҜ. (ЩҮЩ…ЩҮ Ш§ЩҠЩҶ ЩғШ§ШұЩҮШ§ШҢ ШЁШҜЩҲЩҶ ЩҶЩҠШ§ШІ ШЁЩҮ ЩҶЩҲШҙШӘЩҶ ЩҮЩҠЪҶ ЩӮШ·Ш№ЩҮ ШЁШұЩҶШ§Щ…ЩҮ Ш§ЩҠ Щ…ЩҠШіШұ Ш§ШіШӘ.) Ш§ЩҠЩҶ Щ…ШӯЩҠШ·ШҢ ШҙШ§Щ…Щ„ ШұЩҲШҙ вҖҸЩҮШ§ЩҠЩҠ ШЁШұШ§ЩҠ ЩҮЩ…ЩҮ Щ…ШіШ§ЩҠЩ„ Ш§ШіШӘШ§ЩҶШҜШ§ШұШҜ ШҜШ§ШҜЩҮ ЩғШ§ЩҲЩҠ Щ…Ш§ЩҶЩҶШҜ ШұЪҜШұШіЩҠЩҲЩҶШҢ ШұШҜЩҮвҖҸШЁЩҶШҜЩҠШҢ Ш®ЩҲШҙЩҮ ШЁЩҶШҜЩҠШҢ ЩғШ§ЩҲШҙ ЩӮЩҲШ§Ш№ШҜ Ш§ЩҶШ¬Щ…ЩҶЩҠ ЩҲ Ш§ЩҶШӘШ®Ш§ШЁ ЩҲЩҠЪҳЪҜЩҠ Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. ШЁШ§ ШҜШұ ЩҶШёШұ ЪҜШұЩҒШӘЩҶ Ш§ЩҠЩҶЩғЩҮШҢ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШЁШ®Шҙ Щ…ЩғЩ…Щ„ ЩғШ§Шұ ЩҮШіШӘЩҶШҜШҢ ШЁШіЩҠШ§ШұЩҠ Ш§ШІ Ш§ШЁШІШ§ШұЩҮШ§ЩҠ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ЩҲ Щ…ШөЩҲШұШіШ§ШІЩҠ ШўЩҶЩҮШ§ ЩҒШұШ§ЩҮЩ… ЪҜШҙШӘЩҮ Ш§ШіШӘ. ЩҮЩ…ЩҮ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ШҢ ЩҲШұЩҲШҜЩҠ вҖҸЩҮШ§ЩҠ Ш®ЩҲШҜ ШұШ§ ШЁЩҮ ШөЩҲШұШӘ ЩҠЩғ Ш¬ШҜЩҲЩ„ ШұШ§ШЁШ·ЩҮВӯШ§ЩҠ [11] ШЁЩҮ ЩҒШұЩ…ШӘ ARFF ШҜШұЩҠШ§ЩҒШӘ Щ…ЩҠвҖҸ ЩғЩҶЩҶШҜ. Ш§ЩҠЩҶ ЩҒШұЩ…ШӘ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ Ш§ШІ ЩҠЩғ ЩҒШ§ЩҠЩ„ Ш®ЩҲШ§ЩҶШҜЩҮ ШҙШҜЩҮ ЩҠШ§ ШЁЩҮ ЩҲШіЩҠЩ„ЩҮ ЩҠЩғ ШҜШұШ®ЩҲШ§ШіШӘ Ш§ШІ ЩҫШ§ЩҠЪҜШ§ЩҮ ШҜШ§ШҜЩҮ Ш§ЩҠ ШӘЩҲЩ„ЩҠШҜ ЪҜШұШҜШҜ. ЩҠЩғЩҠ Ш§ШІ ШұШ§ЩҮ вҖҸЩҮШ§ЩҠ ШЁЩҮ ЩғШ§ШұЪҜЩҠШұЩҠ Weka ШҢ Ш§Ш№Щ…Ш§Щ„ ЩҠЩғ ШұЩҲШҙ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШЁЩҮ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ЩҲ ШӘШӯЩ„ЩҠЩ„ Ш®ШұЩҲШ¬ЩҠ ШўЩҶ ШЁШұШ§ЩҠ ШҙЩҶШ§Ш®ШӘ ЪҶЩҠШІЩҮШ§ЩҠ ШЁЩҠШҙШӘШұЩҠ ШұШ§Ш¬Ш№ ШЁЩҮ ШўЩҶ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. ШұШ§ЩҮ ШҜЩҠЪҜШұ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Щ…ШҜЩ„ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШҙШҜЩҮ ШЁШұШ§ЩҠ ШӘЩҲЩ„ЩҠШҜ ЩҫЩҠШҙвҖҸШЁЩҠЩҶЩҠ вҖҸЩҮШ§ЩҠЩҠ ШҜШұ Щ…ЩҲШұШҜ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ Ш¬ШҜЩҠШҜ Ш§ШіШӘ. ШіЩҲЩ…ЩҠЩҶ ШұШ§ЩҮШҢ Ш§Ш№Щ…Ш§Щ„ ЩҠШ§ШҜЪҜЩҠШұЩҶШҜЩҮ вҖҸЩҮШ§ЩҠ Щ…Ш®ШӘЩ„ЩҒ ЩҲ Щ…ЩӮШ§ЩҠШіЩҮ ЩғШ§ШұШўЩҠЩҠ ШўЩҶЩҮШ§ ШЁЩҮ Щ…ЩҶШёЩҲШұ Ш§ЩҶШӘШ®Ш§ШЁ ЩҠЩғЩҠ Ш§ШІ ШўЩҶЩҮШ§ ШЁШұШ§ЩҠ ШӘШ®Щ…ЩҠЩҶ Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. ШұЩҲШҙ вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ Classifier ЩҶШ§Щ…ЩҠШҜЩҮ Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜ ЩҲ ШҜШұ ЩҲШ§ШіШ· ШӘШ№Ш§Щ…Щ„ЩҠ [12] Weka ШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ЩҮШұ ЩҠЩғ Ш§ШІ ШўЩҶЩҮШ§ ШұШ§ Ш§ШІ Щ…ЩҶЩҲ [13] Ш§ЩҶШӘШ®Ш§ШЁ ЩҶЩ…ЩҲШҜ. ШЁШіЩҠШ§ШұЩҠ Ш§ШІ classifier вҖҸЩҮШ§ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЩҠ ЩӮШ§ШЁЩ„ ШӘЩҶШёЩҠЩ… ШҜШ§ШұЩҶШҜ ЩғЩҮ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ Ш§ШІ Ш·ШұЩҠЩӮ ШөЩҒШӯЩҮ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ ЩҠШ§ object editor ШЁЩҮ ШўЩҶЩҮШ§ ШҜШіШӘШұШіЩҠ ШҜШ§ШҙШӘ. ЩҠЩғ ЩҲШ§ШӯШҜ Ш§ШұШІЩҠШ§ШЁЩҠ Щ…ШҙШӘШұЩғШҢ ШЁШұШ§ЩҠ Ш§ЩҶШҜШ§ШІЩҮвҖҸЪҜЩҠШұЩҠ ЩғШ§ШұШўЩҠЩҠ ЩҮЩ…ЩҮ classifier ШЁЩҮ ЩғШ§Шұ Щ…ЩҠвҖҸВӯШұЩҲШҜ. ЩҫЩҠШ§ШҜЩҮ ШіШ§ШІЩҠ вҖҸЩҮШ§ЩҠ ЪҶШ§ШұЪҶЩҲШЁ вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩҲШ§ЩӮШ№ЩҠШҢ Щ…ЩҶШ§ШЁШ№ ШЁШіЩҠШ§Шұ Ш§ШұШІШҙЩ…ЩҶШҜЩҠ ЩҮШіШӘЩҶШҜ ЩғЩҮ Weka ЩҒШұШ§ЩҮЩ… Щ…ЩҠвҖҸ ЩғЩҶШҜ. Ш§ШЁШІШ§ШұЩҮШ§ЩҠЩҠ ЩғЩҮ ШЁШұШ§ЩҠ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜ. filter ЩҶШ§Щ…ЩҠШҜЩҮ Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜ. ЩҮЩ…Ш§ЩҶЩҶШҜ classifier вҖҸЩҮШ§ШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ filter вҖҸЩҮШ§ ШұШ§ Ш§ШІ Щ…ЩҶЩҲЩҠ Щ…ШұШЁЩҲШ·ЩҮ Ш§ЩҶШӘШ®Ш§ШЁ ЩғШұШҜЩҮ ЩҲ ШўЩҶЩҮШ§ ШұШ§ ШЁШ§ ЩҶЩҠШ§ШІЩ…ЩҶШҜЩҠ вҖҸЩҮШ§ЩҠ Ш®ЩҲШҜШҢ ШіШ§ШІЪҜШ§Шұ ЩҶЩ…ЩҲШҜ. ШҜШұ Ш§ШҜШ§Щ…ЩҮШҢ ШЁЩҮ ШұЩҲШҙ ШЁЩҮ ЩғШ§ШұЪҜЩҠШұЩҠ ЩҒЩҠЩ„ШӘШұЩҮШ§ Ш§ШҙШ§ШұЩҮ Щ…ЩҠвҖҸ ШҙЩҲШҜ. Ш№Щ„Ш§ЩҲЩҮ ШЁШұ Щ…ЩҲШ§ШұШҜ ЩҒЩҲЩӮШҢ Weka ШҙШ§Щ…Щ„ ЩҫЩҠШ§ШҜЩҮ ШіШ§ШІЩҠ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠЩҠ ШЁШұШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩӮЩҲШ§Ш№ШҜ Ш§ЩҶШ¬Щ…ЩҶЩҠШҢ Ш®ЩҲШҙЩҮ ШЁЩҶШҜЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШҜШұ Ш¬Ш§ЩҠЩҠ ЩғЩҮ ЩҮЩҠЪҶ ШҜШіШӘЩҮ Ш§ЩҠ ШӘШ№ШұЩҠЩҒ ЩҶШҙШҜЩҮ Ш§ШіШӘШҢ ЩҲ Ш§ЩҶШӘШ®Ш§ШЁ ЩҲЩҠЪҳЪҜЩҠвҖҸЩҮШ§ЩҠ Щ…ШұШӘШЁШ· [14] ШҜШұ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ Щ…ЩҠвҖҸ ШҙЩҲШҜ. 2- ШұЩҲШҙ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Weka ШҙЩғЩ„ 1ШҢвҖҢ ШұШ§ЩҮЩҮШ§ЩҠ Ш§ЩҶШӘШ®Ш§ШЁ ЩҲШ§ШіШ· ЩҮШ§ЩҠ Щ…Ш®ШӘЩ„ЩҒ Weka ШұШ§ ЩҶШҙШ§ЩҶ Щ…ЩҠ ШҜЩҮШҜ. ШўШіШ§ЩҶ ШӘШұЩҠЩҶ ШұШ§ЩҮ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Weka ШҢ Ш§ШІ Ш·ШұЩҠЩӮ ЩҲШ§ШіШ·ЩҠ ЪҜШұШ§ЩҒЩҠЩғЩҠ Ш§ШіШӘ ЩғЩҮ Explorer Ш®ЩҲШ§ЩҶШҜЩҮ Щ…ЩҠвҖҸШҙЩҲШҜ. Ш§ЩҠЩҶ ЩҲШ§ШіШ· ЪҜШұШ§ЩҒЩҠЩғЩҠШҢ ШЁЩҮ ЩҲШіЩҠЩ„ЩҮ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҶЩҲЩҮШ§ ЩҲ ЩҫШұ ЩғШұШҜЩҶ ЩҒШұЩ… вҖҸЩҮШ§ЩҠ Щ…ШұШЁЩҲШ·ЩҮШҢ ШҜШіШӘШұШіЩҠ ШЁЩҮ ЩҮЩ…ЩҮ Ш§Щ…ЩғШ§ЩҶШ§ШӘ ШұШ§ ЩҒШұШ§ЩҮЩ… ЩғШұШҜЩҮ Ш§ШіШӘ. ШЁШұШ§ЩҠ Щ…Ш«Ш§Щ„ШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШЁЩҮ ШіШұШ№ШӘ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ШұШ§ Ш§ШІ ЩҠЩғ ЩҒШ§ЩҠЩ„ ARFF Ш®ЩҲШ§ЩҶШҜ ЩҲ ШҜШұШ®ШӘ ШӘШөЩ…ЩҠЩ…вҖҸЪҜЩҠШұЩҠ ШўЩҶ ШұШ§ ШӘЩҲЩ„ЩҠШҜ ЩҶЩ…ЩҲШҜ. Ш§Щ…Ш§ШҜШұШ®ШӘ вҖҸЩҮШ§ЩҠ ШӘШөЩ…ЩҠЩ…вҖҸЪҜЩҠШұЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҶШҜЩҮ ШөШұЩҒШ§ЩӢ Ш§ШЁШӘШҜШ§ЩҠ ЩғШ§Шұ ЩҮШіШӘЩҶШҜ. Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ШЁШіЩҠШ§Шұ ШҜЩҠЪҜШұЩҠ ШЁШұШ§ЩҠ Ш¬ШіШӘШ¬ЩҲ ЩҲШ¬ЩҲШҜ ШҜШ§ШұЩҶШҜ. ЩҲШ§ШіШ· Explorer ЩғЩ…Щғ Щ…ЩҠвҖҸ ЩғЩҶШҜ ШӘШ§ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ШҜЩҠЪҜШұ ЩҶЩҠШІ ШўШІЩ…Ш§ЩҠШҙ ШҙЩҲЩҶШҜ.  ШҙЩғЩ„ 1. Weka ШҜШұ ЩҲШ¶Ш№ЩҠШӘ Ш§ЩҶШӘШ®Ш§ШЁ ЩҲШ§ШіШ· Ш§ЩҠЩҶ ЩҲШ§ШіШ· ШЁШ§ ШҜШұ Ш§Ш®ШӘЩҠШ§Шұ ЪҜШ°Ш§ШҙШӘЩҶ ЪҜШІЩҠЩҶЩҮ вҖҸЩҮШ§ ШЁЩҮ ШөЩҲШұШӘ Щ…ЩҶЩҲШҢ ШЁШ§ ЩҲШ§ШҜШ§Шұ ЩғШұШҜЩҶ ЩғШ§ШұШЁШұ ШЁЩҮ Ш§Ш¬ШұШ§ЩҠ ЩғШ§ШұЩҮШ§ ШЁШ§ ШӘШұШӘЩҠШЁ ШөШӯЩҠШӯШҢ ШЁЩҮ ЩҲШіЩҠЩ„ЩҮ Ш®Ш§ЩғШіШӘШұЩҠ ЩҶЩ…ЩҲШҜЩҶ ЪҜШІЩҠЩҶЩҮ вҖҸЩҮШ§ ШӘШ§ ШІЩ…Ш§ЩҶ ШөШӯЩҠШӯ ШЁЩҮ ЩғШ§ШұЪҜЩҠШұЩҠ ШўЩҶЩҮШ§ШҢ ЩҲ ШЁШ§ ШҜШұ Ш§Ш®ШӘЩҠШ§Шұ ЪҜШ°Ш§ШҙШӘЩҶ ЪҜШІЩҠЩҶЩҮ вҖҸЩҮШ§ЩҠЩҠ ШЁЩҮ ШөЩҲШұШӘ ЩҒШұЩ… вҖҸЩҮШ§ЩҠ ЩҫШұШҙШҜЩҶЩҠШҢ ЩғШ§ШұШЁШұ ШұШ§ ЩҮШҜШ§ЩҠШӘ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ШұШ§ЩҮЩҶЩ…Ш§ЩҠ Ш§ШЁШІШ§Шұ Щ…ЩҒЩҠШҜЩҠШҢ ШӯЩҠЩҶ Ш№ШЁЩҲШұ Щ…Ш§ЩҲШі Ш§ШІ ШұЩҲЩҠ ЪҜШІЩҠЩҶЩҮ вҖҸЩҮШ§ШҢ ШёШ§ЩҮШұ ШҙШҜЩҮ ЩҲ Ш§Ш№Щ…Ш§Щ„ Щ„Ш§ШІЩ… Щ…ШұШЁЩҲШ·ЩҮ ШұШ§ ШҙШұШӯ Щ…ЩҠвҖҸ ШҜЩҮШҜ. ЩҫЩҠШҙ ЩҒШұШ¶ вҖҸЩҮШ§ЩҠ Щ…Ш№ЩӮЩҲЩ„ ЩӮШұШ§Шұ ШҜШ§ШҜЩҮ ШҙШҜЩҮШҢ ЩғШ§ШұШЁШұ ШұШ§ ЩӮШ§ШҜШұ Щ…ЩҠвҖҸ ШіШ§ШІЩҶШҜ ШӘШ§ ШЁШ§ ЩғЩ…ШӘШұЩҠЩҶ ШӘЩ„Ш§ШҙЩҠШҢ ШЁЩҮ ЩҶШӘЩҠШ¬ЩҮ ШЁШұШіШҜ. Ш§Щ…Ш§ ЩғШ§ШұШЁШұ ШЁШ§ЩҠШҜ ШЁШұШ§ЩҠ ШҜШұЩғ Щ…Ш№ЩҶЩҠ ЩҶШӘШ§ЩҠШ¬ ШӯШ§ШөЩ„ЩҮШҢ ШұШ§Ш¬Ш№ ШЁЩҮ ЩғШ§ШұЩҮШ§ЩҠЩҠ ЩғЩҮ Ш§ЩҶШ¬Ш§Щ… Щ…ЩҠвҖҸ ШҜЩҮШҜШҢ ШЁЩҠЩҶШҜЩҠШҙШҜ. Weka ШҜЩҲ ЩҲШ§ШіШ· ЪҜШұШ§ЩҒЩҠЩғЩҠ ШҜЩҠЪҜШұ ЩҶЩҠШІ ШҜШ§ШұШҜ. ЩҲШ§ШіШ· knowledge flow ШЁЩҮ ЩғШ§ШұШЁШұ Ш§Щ…ЩғШ§ЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ШӘШ§ ЪҶЩҶЩҠШҙ вҖҸЩҮШ§ЩҠЩҠ ШЁШұШ§ЩҠ ЩҫШұШҜШ§ШІШҙ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ЩҠ ШҜШұ Ш¬ШұЩҠШ§ЩҶШҢ Ш·ШұШ§ШӯЩҠ ЩғЩҶШҜ. ЩҠЩғ Ш№ЩҠШЁ ЩҫШ§ЩҠЩҮ Ш§ЩҠ Explorer . ЩҶЪҜЩҮШҜШ§ШұЩҠ ЩҮШұ ЪҶЩҠШІЩҠ ШҜШұ ШӯШ§ЩҒШёЩҮ Ш§ШөЩ„ЩҠ ШўЩҶ Ш§ШіШӘ. (ШІЩ…Ш§ЩҶЩҠ ЩғЩҮ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ШұШ§ ШЁШ§ШІ Щ…ЩҠвҖҸ ЩғЩҶЩҠЩ…ШҢ Explorer ШҢ ЩғЩ„ ШўЩҶ ШұШ§ШҢ ШҜШұ ШӯШ§ЩҒШё ШЁШ§ШІ Щ…ЩҠвҖҸ ЩғЩҶШҜ) ЩҶШҙШ§ЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ЩғЩҮ Explorer ШҢ ШөШұЩҒШ§ЩӢ ШЁШұШ§ЩҠ Щ…ШіШ§ЩҠЩ„ ШЁШ§ Ш§ЩҶШҜШ§ШІЩҮ вҖҸЩҮШ§ЩҠ ЩғЩҲЪҶЩғ ШӘШ§ Щ…ШӘЩҲШіШ·ШҢ ЩӮШ§ШЁЩ„ Ш§Ш№Щ…Ш§Щ„ Ш§ШіШӘ. ШЁШ§ ЩҲШ¬ЩҲШҜ ШЁШұ Ш§ЩҠЩҶ Weka ШҙШ§Щ…Щ„ ШӘШ№ШҜШ§ШҜЩҠ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ Ш§ЩҒШІШ§ЩҠШҙЩҠ Ш§ШіШӘ ЩғЩҮ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШЁШұШ§ЩҠ ЩҫШұШҜШ§ШІШҙ Щ…Ш¬Щ…ЩҲШ№ЩҮ ЩҮШ§ЩҠ ШҜШ§ШҜЩҮ ШЁШіЩҠШ§Шұ ШЁШІШұЪҜ Щ…ЩҲШұШҜ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩӮШұШ§Шұ ЪҜЩҠШұШҜ. ЩҲШ§ШіШ· knowledge flow Ш§Щ…ЩғШ§ЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ШӘШ§ Ш¬Ш№ШЁЩҮ [15] вҖҸЩҮШ§ЩҠ ЩҶЩ…Ш§ЩҠШ§ЩҶЪҜШұ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩҲ Щ…ЩҶШ§ШЁШ№ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШұШ§ ШЁЩҮ ШҜШұЩҲЩҶ ШөЩҒШӯЩҮ ШЁЩғШҙЩҠЩ… ЩҲ ШЁШ§ Ш§ШӘШөШ§Щ„ ШўЩҶЩҮШ§ ШЁЩҮ ЩҠЩғШҜЩҠЪҜШұШҢ ШӘШұЩғЩҠШЁ ЩҲ ЪҶЩҠЩҶШҙ ШҜЩ„Ш®ЩҲШ§ЩҮ Ш®ЩҲШҜ ШұШ§ ШЁШіШ§ШІЩҠЩ…. Ш§ЩҠЩҶ ЩҲШ§ШіШ· Ш§Ш¬Ш§ШІЩҮ Щ…ЩҠвҖҸ ШҜЩҮШҜ ШӘШ§ Ш¬ШұЩҠШ§ЩҶ ШҜШ§ШҜЩҮ Ш§ЩҠ Ш§ШІ Щ…ШӨЩ„ЩҒЩҮ вҖҸЩҮШ§ЩҠ ШЁЩҮ ЩҮЩ… Щ…ШӘШөЩ„ ЩғЩҮ ШЁЩҠШ§ЩҶЪҜШұ Щ…ЩҶШ§ШЁШ№ ШҜШ§ШҜЩҮШҢ Ш§ШЁШІШ§ШұЩҮШ§ЩҠ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙШҢ ШұЩҲШҙ вҖҸЩҮШ§ЩҠ Ш§ШұШІЩҠШ§ШЁЩҠ ЩҲ ЩҲШ§ШӯШҜЩҮШ§ЩҠ Щ…ШөЩҲЩ‘Шұ ШіШ§ШІЩҠ ЩҮШіШӘЩҶШҜ ШӘШ№ШұЩҠЩҒ ШҙЩҲШҜ. Ш§ЪҜШұ ЩҒЩҠЩ„ШӘШұЩҮШ§ ЩҲ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… ЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠШҢ ЩӮШ§ШЁЩ„ЩҠШӘ ЩҠШ§ШҜЪҜЩҠШұЩҠ Ш§ЩҒШІШ§ЩҠШҙЩҠ ШұШ§ ШҜШ§ШҙШӘЩҮ ШЁШ§ШҙЩҶШҜШҢ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШЁЩҮ ШөЩҲШұШӘ Ш§ЩҒШІШ§ЩҠШҙЩҠ ШЁШ§Шұ ШҙШҜЩҮ ЩҲ ЩҫШұШҜШ§ШІШҙ Ш®ЩҲШ§ЩҮЩҶШҜ ШҙШҜ. ШіЩҲЩ…ЩҠЩҶ ЩҲШ§ШіШ· Weka ШҢ ЩғЩҮ Experimenter Ш®ЩҲШ§ЩҶШҜЩҮ Щ…ЩҠвҖҸ ШҙЩҲШҜШҢ ЩғЩ…Щғ Щ…ЩҠвҖҸ ЩғЩҶШҜ ШӘШ§ ШЁЩҮ Ш§ЩҠЩҶ ШіШӨШ§Щ„ Ш№Щ…Щ„ЩҠ ЩҲ ЩҫШ§ЩҠЩҮ Ш§ЩҠ ЩғШ§ШұШЁШұ ШӯЩҠЩҶ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШӘЩғЩҶЩҠЩғ вҖҸЩҮШ§ЩҠ ШұШҜЩҮвҖҸШЁЩҶШҜЩҠ ЩҲ ШұЪҜШұШіЩҠЩҲЩҶШҢ ЩҫШ§ШіШ® ШҜЩҮШҜ: "ЪҶЩҮ ШұЩҲШҙ вҖҸЩҮШ§ ЩҲ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЩҠЩҠ ШЁШұШ§ЩҠ Щ…ШіШЈЩ„ЩҮ ШҜШ§ШҜЩҮ ШҙШҜЩҮШҢ ШЁЩҮШӘШұ Ш№Щ…Щ„ Щ…ЩҠвҖҸ ЩғЩҶЩҶШҜШҹ" Ш№Щ…ЩҲЩ…Ш§ЩӢ ШұШ§ЩҮЩҠ ШЁШұШ§ЩҠ ЩҫШ§ШіШ®ЪҜЩҲЩҠЩҠ Щ…ЩӮШҜЩ…Ш§ШӘЩҠ ШЁЩҮ Ш§ЩҠЩҶ ШіШӨШ§Щ„ ЩҲШ¬ЩҲШҜ ЩҶШҜШ§ШұШҜ ЩҲ ЩҠЩғЩҠ Ш§ШІ ШҜЩ„Ш§ЩҠЩ„ ШӘЩҲШіШ№ЩҮ Weka ШҢ ЩҒШұШ§ЩҮЩ… ЩҶЩ…ЩҲШҜЩҶ Щ…ШӯЩҠШ·ЩҠ Ш§ШіШӘ ЩғЩҮ ЩғШ§ШұШЁШұШ§ЩҶ Weka ШұШ§ ЩӮШ§ШҜШұ ШЁЩҮ Щ…ЩӮШ§ЩҠШіЩҮ ШӘЩғЩҶЩҠЩғ вҖҸЩҮШ§ЩҠ ЪҜЩҲЩҶШ§ЪҜЩҲЩҶ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШЁЩҶЩ…Ш§ЩҠШҜ. Ш§ЩҠЩҶ ЩғШ§ШұШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШЁЩҮ ШөЩҲШұШӘ ШӘШ№Ш§Щ…Щ„ЩҠ ШҜШұ Explorer Ш§ЩҶШ¬Ш§Щ… ШҙЩҲШҜ. ШЁШ§ Ш§ЩҠЩҶ ЩҲШ¬ЩҲШҜШҢ Experimenter ШЁШ§ ШіШ§ШҜЩҮ ЩғШұШҜЩҶ Ш§Ш¬ШұШ§ЩҠ ШұШҜЩҮвҖҸШЁЩҶШҜЩҠ ЩғЩҶЩҶШҜЩҮ вҖҸЩҮШ§ ЩҲ ЩҒЩҠЩ„ШӘШұЩҮШ§ ШЁШ§ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЩҠ ЪҜЩҲЩҶШ§ЪҜЩҲЩҶ ШұЩҲЩҠ ШӘШ№ШҜШ§ШҜЩҠ Ш§ШІ Щ…Ш¬Щ…ЩҲШ№ЩҮ вҖҸЩҮШ§ЩҠ ШҜШ§ШҜЩҮШҢ Ш¬Щ…Ш№ ШўЩҲШұЩҠ ШўЩ…Ш§Шұ ЩғШ§ШұШўЩҠЩҠ ЩҲ Ш§ЩҶШ¬Ш§Щ… ШўШІЩ…Ш§ЩҠШҙ вҖҸЩҮШ§ЩҠ Щ…Ш№ЩҶШ§ШҢ ЩҫШұШҜШ§ШІШҙ ШұШ§ Ш®ЩҲШҜЩғШ§Шұ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ЩғШ§ШұШЁШұЩҮШ§ЩҠ ЩҫЩҠШҙШұЩҒШӘЩҮШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶЩҶШҜ Ш§ШІ Experimenter ШЁШұШ§ЩҠ ШӘЩҲШІЩҠШ№ ШЁШ§Шұ Щ…ШӯШ§ШіШЁШ§ШӘЩҠ ШЁЩҠЩҶ ЪҶЩҶШҜЩҠЩҶ Щ…Ш§ШҙЩҠЩҶШҢ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩғЩҶЩҶШҜ. ШҜШұ Ш§ЩҠЩҶ ШұЩҲШҙШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШўШІЩ…Ш§ЩҠШҙ вҖҸЩҮШ§ЩҠ ШўЩ…Ш§ШұЩҠ ШЁШІШұЪҜЩҠ ШұШ§ ШұШ§ЩҮ Ш§ЩҶШҜШ§ШІЩҠ ЩҶЩ…ЩҲШҜЩҮ ЩҲ ШўЩҶЩҮШ§ ШұШ§ ШЁШұШ§ЩҠ Ш§Ш¬ШұШ§ШҢ ШұЩҮШ§ ЩҶЩ…ЩҲШҜ. ЩҲШұШ§ЩҠ Ш§ЩҠЩҶ ЩҲШ§ШіШ· вҖҸЩҮШ§ЩҠ ШӘШ№Ш§Щ…Щ„ЩҠШҢ Ш№Щ…Щ„ЩғШұШҜ ЩҫШ§ЩҠЩҮ Ш§ЩҠ Weka ЩӮШұШ§Шұ ШҜШ§ШұШҜ. ШӘЩҲШ§ШЁШ№ ЩҫШ§ЩҠЩҮ Ш§ЩҠ Weka ШҢ Ш§ШІ Ш·ШұЩҠЩӮ Ш®Ш· ЩҒШұЩ…Ш§ЩҶ [16] вҖҸЩҮШ§ЩҠ Щ…ШӘЩҶЩҠ ЩӮШ§ШЁЩ„ ШҜШіШӘШұШіЩҠ ЩҮШіШӘЩҶШҜ. ШІЩ…Ш§ЩҶЩҠ ЩғЩҮ Weka ШҢ ЩҒШ№Ш§Щ„ Щ…ЩҠвҖҸ ШҙЩҲШҜШҢ Ш§Щ…ЩғШ§ЩҶ Ш§ЩҶШӘШ®Ш§ШЁ ШЁЩҠЩҶ ЪҶЩҮШ§Шұ ЩҲШ§ШіШ· ЩғШ§ШұШЁШұЩҠ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ: Explorer ШҢ knowledge ШҢ Experimenter ЩҲ ЩҲШ§ШіШ· Ш®Ш· ЩҒШұЩ…Ш§ЩҶ. Ш§ЩғШ«Шұ ЩғШ§ШұШЁШұШ§ЩҶШҢ ШӯШҜШ§ЩӮЩ„ ШҜШұ Ш§ШЁШӘШҜШ§ЩҠ ЩғШ§Шұ Explorer ШұШ§ ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҲШ§ШіШ· ЩғШ§ШұШЁШұЩҠ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҠвҖҸ ЩғЩҶЩҶШҜ. 3. ЩӮШ§ШЁЩ„ЩҠШӘЩҮШ§ЩҠ Weka Щ…ШіШӘЩҶШҜШіШ§ШІЩҠ ШҜШұ Щ„ШӯШёЩҮШҢ ЩғЩҮ ШЁЩҮ ШөЩҲШұШӘ Ш®ЩҲШҜЩғШ§Шұ Ш§ШІ ЩғШҜ Ш§ШөЩ„ЩҠ ШӘЩҲЩ„ЩҠШҜ Щ…ЩҠвҖҸ ШҙЩҲШҜ ЩҲ ШҜЩӮЩҠЩӮШ§ЩӢ ШіШ§Ш®ШӘШ§Шұ ШўЩҶ ШұШ§ ШЁЩҠШ§ЩҶ Щ…ЩҠвҖҸ ЩғЩҶШҜШҢ ЩӮШ§ШЁЩ„ЩҠШӘ Щ…ЩҮЩ…ЩҠ Ш§ШіШӘ ЩғЩҮ ШӯЩҠЩҶ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Weka ЩҲШ¬ЩҲШҜШҜШ§ШұШҜ. ЩҶШӯЩҲЩҮ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Ш§ЩҠЩҶ Щ…ШіШӘЩҶШҜШ§ШӘ ЩҲ ЪҶЪҜЩҲЩҶЪҜЩҠ ШӘШ№ЩҠЩҠЩҶ ЩҫШ§ЩҠЩҮ вҖҸЩҮШ§ЩҠ ШіШ§Ш®ШӘЩ…Ш§ЩҶЩҠ Ш§ШөЩ„ЩҠ Weka ШҢ Щ…ШҙШ®Шө ЩғШұШҜЩҶ ШЁШ®Шҙ вҖҸЩҮШ§ЩҠЩҠ ЩғЩҮ Ш§ШІ ШұЩҲШҙ вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШЁШ§ ШіШұЩҫШұШіШӘ Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЩҠвҖҸ ЩғЩҶШҜШҢ Ш§ШЁШІШ§ШұЩҠ ШЁШұШ§ЩҠ ЩҫЩҠШҙ ЩҫШұШҜШ§ШІШҙ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШЁЩғШ§Шұ Щ…ЩҠвҖҸ ШұЩҲШҜ ЩҲ Ш§ЩҠЩҶЩғЩҮ ЪҶЩҮ ШұЩҲШҙ вҖҸЩҮШ§ЩҠЩҠ ШЁШұШ§ЩҠ ШіШ§ЩҠШұ ШЁШұЩҶШ§Щ…ЩҮ вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜШҢ ШҜШұ Ш§ШҜШ§Щ…ЩҮ ШӘШҙШұЩҠШӯ Ш®ЩҲШ§ЩҮШҜ ШҙШҜ. ШӘЩҶЩҮШ§ ШЁЩҮ Щ„ЩҠШіШӘ ЩғШ§Щ…Щ„ЩҠ Ш§ШІ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ Щ…ЩҲШ¬ЩҲШҜ Ш§ЩғШӘЩҒШ§ Щ…ЩҠвҖҸ ШҙЩҲШҜ ШІЩҠШұШ§ Weka ШЁЩҮ Ш·ЩҲШұ ЩҫЩҠЩҲШіШӘЩҮ ШӘЩғЩ…ЩҠЩ„ Щ…ЩҠвҖҸ ШҙЩҲШҜ ЩҲ ШЁЩҮ Ш·ЩҲШұ Ш®ЩҲШҜЩғШ§Шұ Ш§ШІ ЩғШҜ Ш§ШөЩ„ЩҠ ШӘЩҲЩ„ЩҠШҜ Щ…ЩҠвҖҸ ШҙЩҲШҜ. Щ…ШіШӘЩҶШҜШ§ШӘ ШҜШұ Щ„ШӯШёЩҮ ЩҮЩ…ЩҠШҙЩҮ ШЁЩҮ ЩҮЩҶЪҜШ§Щ… ШҙШҜЩҮ Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. Ш§ЪҜШұ Ш§ШҜШ§Щ…ЩҮ ШҜШ§ШҜЩҶ ШЁЩҮ Щ…ШұШ§ШӯЩ„ ШЁШ№ШҜЩҠ ЩҲ ШҜШіШӘШұШіЩҠ ШЁЩҮ ЩғШӘШ§ШЁШ®Ш§ЩҶЩҮ Ш§ШІ ШЁШұЩҶШ§Щ…ЩҮ Ш¬Ш§ЩҲШ§ ШҙШ®ШөЩҠ ЩҠШ§ ЩҶЩҲШҙШӘЩҶ ЩҲ ШўШІЩ…Ш§ЩҠШҙ ЩғШұШҜЩҶ ШЁШұЩҶШ§Щ…ЩҮ вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШҙШ®ШөЩҠ Щ…ЩҲШұШҜ ЩҶЩҠШ§ШІ ШЁШ§ШҙШҜШҢ Ш§ЩҠЩҶ ЩҲЩҠЪҳЪҜЩҠ ШЁШіЩҠШ§Шұ ШӯЩҠШ§ШӘЩҠ Ш®ЩҲШ§ЩҮШҜ ШЁЩҲШҜ. ШҜШұ Ш§ШәЩ„ШЁ ШЁШұЩҶШ§Щ…ЩҮ вҖҸЩҮШ§ЩҠ ЩғШ§ШұШЁШұШҜЩҠ ШҜШ§ШҜЩҮ ЩғШ§ЩҲЩҠШҢ Ш¬ШІШЎ ЩҠШ§ШҜЪҜЩҠШұЩҠ Щ…Ш§ШҙЩҠЩҶЩҠШҢ ШЁШ®Шҙ ЩғЩҲЪҶЩғЩҠ Ш§ШІ ШіЩҠШіШӘЩ… ЩҶШұЩ… Ш§ЩҒШІШ§ШұЩҠ ЩҶШіШЁШӘШ§ЩӢ ШЁШІШұЪҜЩҠ ШұШ§ ШҙШ§Щ…Щ„ Щ…ЩҠвҖҸ ШҙЩҲШҜ. ШҜШұ ШөЩҲШұШӘЩҠ ЩғЩҮ ЩҶЩҲШҙШӘЩҶ ШЁШұЩҶШ§Щ…ЩҮ ЩғШ§ШұШЁШұШҜЩҠ ШҜШ§ШҜЩҮ ЩғШ§ЩҲЩҠ Щ…ШҜ ЩҶШёШұ ШЁШ§ШҙШҜШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШЁШ§ ШЁШұЩҶШ§Щ…ЩҮ ЩҶЩҲЩҠШіЩҠ Ш§ЩҶШҜЩғЩҠ ШЁЩҮ ШЁШұЩҶШ§Щ…ЩҮ вҖҸЩҮШ§ЩҠ Weka Ш§ШІ ШҜШ§Ш®Щ„ ЩғШҜ ШҙШ®ШөЩҠ ШҜШіШӘШұШіЩҠ ШҜШ§ШҙШӘ. Ш§ЪҜШұ ЩҫЩҠШҜШ§ ЩғШұШҜЩҶ Щ…ЩҮШ§ШұШӘ ШҜШұ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ Щ…Ш§ШҙЩҠЩҶЩҠ Щ…ШҜЩҶШёШұ ШЁШ§ШҙШҜШҢ Ш§Ш¬ШұШ§ЩҠ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ШҙШ®ШөЩҠ ШЁШҜЩҲЩҶ ШҜШұЪҜЩҠШұ Ш¬ШІЩҠЩҠШ§ШӘ ШҜШіШӘ ЩҲ ЩҫШ§ ЪҜЩҠШұ ШҙШҜЩҶ Щ…Ш«Щ„ Ш®ЩҲШ§ЩҶШҜЩҶ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ Ш§ШІ ЩҠЩғ ЩҒШ§ЩҠЩ„ШҢ Ш§Ш¬ШұШ§ЩҠ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ЩҒЩҠЩ„ШӘШұЩҠЩҶЪҜ ЩҠШ§ ШӘЩҮЩҠЩҮ ЩғШҜ ШЁШұШ§ЩҠ Ш§ШұШІЩҠШ§ШЁЩҠ ЩҶШӘШ§ЩҠШ¬ ЩҠЩғЩҠ Ш§ШІ Ш®ЩҲШ§ШіШӘЩҮ вҖҸЩҮШ§ Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. Weka ШҜШ§ШұШ§ЩҠ ЩҮЩ…ЩҮ Ш§ЩҠЩҶ Щ…ШІЩҠШӘ вҖҸЩҮШ§ Ш§ШіШӘ. ШЁШұШ§ЩҠ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩғШ§Щ…Щ„ Ш§ШІ Ш§ЩҠЩҶ ЩҲЩҠЪҳЪҜЩҠШҢ ШЁШ§ЩҠШҜ ШЁШ§ ШіШ§Ш®ШӘШ§ШұЩҮШ§ЩҠ ЩҫШ§ЩҠЩҮ Ш§ЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШўШҙЩҶШ§ ШҙШҜ. 4. ШҜШұЩҠШ§ЩҒШӘ Weka ЩҶШұЩ… Ш§ЩҒШІШ§Шұ Weka ШҢ ШҜШұ ШўШҜШұШі http://www.cs.waikato.ac.nz/me/weka ШҢ ШҜШұ ШҜШіШӘШұШі Ш§ШіШӘ. Ш§ШІ Ш§ЩҠЩҶ Ш·ШұЩҠЩӮ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ЩҶШөШЁ ЩғЩҶЩҶШҜЩҮ [17] Щ…ШӘЩҶШ§ШіШЁ ШЁШ§ ЩҠЩғ ЩҫЩ„ШӘ ЩҒШұЩ… Щ…Ш№ЩҠЩҶШҢ ЩҠШ§ ЩҠЩғ ЩҒШ§ЩҠЩ„ Java jar ШұШ§ ЩғЩҮ ШҜШұ ШөЩҲШұШӘ ЩҶШөШЁ ШЁЩҲШҜЩҶ Ш¬Ш§ЩҲШ§ ШЁЩҮ ШұШ§ШӯШӘЩҠ ЩӮШ§ШЁЩ„ Ш§Ш¬ШұШ§ Ш§ШіШӘШҢ ШҜШ§ЩҶЩ„ЩҲШҜ [18] ЩҶЩ…ЩҲШҜ. 5. Щ…ШұЩҲШұЩҠ ШЁШұ Explorer ЩҲШ§ШіШ· ЪҜШұШ§ЩҒЩҠЩғЩҠ Ш§ШөЩ„ЩҠ ШЁШұШ§ЩҠ ЩғШ§ШұШЁШұШ§ЩҶШҢвҖҢ Explorer Ш§ШіШӘ ЩғЩҮ Ш§Щ…ЩғШ§ЩҶ ШҜШіШӘШұШіЩҠ ШЁЩҮ ЩҮЩ…ЩҮ Ш§Щ…ЩғШ§ЩҶШ§ШӘ Weka ШұШ§ Ш§ШІ Ш·ШұЩҠЩӮ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҶЩҲЩҮШ§ ЩҲ ЩҫШұ ЩғШұШҜЩҶ ЩҒШұЩ…ЩҮШ§ ЩҒШұШ§ЩҮЩ… Щ…ЩҠ ШўЩҲШұШҜ. ШҙЩғЩ„ 2ШҢвҖҢ ЩҶЩ…Ш§ЩҠ Explorer вҖҢ ШұШ§ ЩҶШҙШ§ЩҶ Щ…ЩҠ ШҜЩҮШҜ. ШҜШұ Ш§ЩҠЩҶ ЩҲШ§ШіШ·ШҢ ШҙШҙ ЩҫШ§ЩҶЩ„ [19] Щ…Ш®ШӘЩ„ЩҒ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ ЩғЩҮ Ш§ШІ Ш·ШұЩҠЩӮ ЩҶЩҲШ§Шұ [20] ШЁШ§Щ„Ш§ЩҠ ШөЩҒШӯЩҮ ЩӮШ§ШЁЩ„ Ш§ЩҶШӘШ®Ш§ШЁ ЩҮШіШӘЩҶШҜ ЩҲ ШЁШ§ ЩҲШёШ§ЩҠЩҒ [21] ШҜШ§ШҜЩҮ ЩғШ§ЩҲЩҠ ЩҫШҙШӘЩҠШЁШ§ЩҶЩҠ ШҙШҜЩҮ ШӘЩҲШіШ· Weka вҖҢ Щ…ШӘЩҶШ§ШёШұ Щ…ЩҠ ШЁШ§ШҙЩҶШҜ. 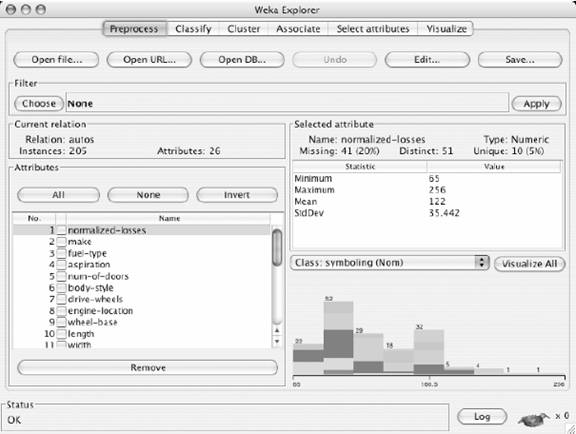 ШҙЩғЩ„ 2. ЩҲШ§ШіШ· ЪҜШұШ§ЩҒЩҠЩғЩҠ Explorer ШҜЩҲ ЪҜШІЩҠЩҶЩҮ Ш§ШІ ШҙШҙ ЪҜШІЩҠЩҶЩҮ ШЁШ§Щ„Ш§ЩҠ ЩҫЩҶШ¬ШұЩҮ Explorer ШҜШұ ШҙЩғЩ„ ЩҮШ§ЩҠ 3 ЩҲ 4 ШЁЩҮ Ш·ЩҲШұ Ш®Щ„Ш§ШөЩҮ ШӘШҙШұЩҠШӯ ШҙШҜЩҮ Ш§ШіШӘ. ШЁЩҮ Ш·ЩҲШұ Ш®Щ„Ш§ШөЩҮШҢ ЩғШ§ШұЩғШұШҜ ШӘЩ…Ш§Щ… ЪҜШІЩҠЩҶЩҮ вҖҸЩҮШ§ ШЁЩҮ ШҙШұШӯ Ш°ЩҠЩ„ Ш§ШіШӘ. Preprocess : Ш§ЩҶШӘШ®Ш§ШЁ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ЩҲ Ш§ШөЩ„Ш§Шӯ [22] ШўЩҶ Ш§ШІ ШұШ§ЩҮ вҖҸЩҮШ§ЩҠ ЪҜЩҲЩҶШ§ЪҜЩҲЩҶ Classify : ШўЩ…ЩҲШІШҙ [23] ШЁШұЩҶШ§Щ…ЩҮ вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩғЩҮ ШұШҜЩҮвҖҸШЁЩҶШҜЩҠ ЩҠШ§ ШұЪҜШұШіЩҠЩҲЩҶ Ш§ЩҶШ¬Ш§Щ… Щ…ЩҠвҖҸ ШҜЩҮЩҶШҜ ЩҲ Ш§ШұШІЩҠШ§ШЁЩҠ ШўЩҶЩҮШ§. Cluster : ЩҠШ§ШҜЪҜЩҠШұЩҠ Ш®ЩҲШҙЩҮ вҖҸЩҮШ§ ШЁШұШ§ЩҠ Щ…Ш¬Щ…ЩҲШ№ЩҮ ЩҮШ§ЩҠ ШҜШ§ШҜЩҮ Associate : ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩӮЩҲШ§Ш№ШҜ Ш§ЩҶШ¬Щ…ЩҶЩҠ ШЁШұШ§ЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ЩҲ Ш§ШұШІЩҠШ§ШЁЩҠ ШўЩҶЩҮШ§ Select attributes : Ш§ЩҶШӘШ®Ш§ШЁ Щ…ШұШӘШЁШ· ШӘШұЩҠЩҶ Ш¬ЩҶШЁЩҮ [24] ЩҮШ§ ШҜШұ Щ…Ш¬Щ…ЩҲШ№ЩҮ ЩҮШ§ЩҠ ШҜШ§ШҜЩҮ Visualize : Щ…ШҙШ§ЩҮШҜЩҮ ЩҶЩ…ЩҲШҜШ§ШұЩҮШ§ЩҠ Щ…Ш®ШӘЩ„ЩҒ ШҜЩҲШЁШ№ШҜЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ЩҲ ШӘШ№Ш§Щ…Щ„ ШЁШ§ ШўЩҶЩҮШ§ 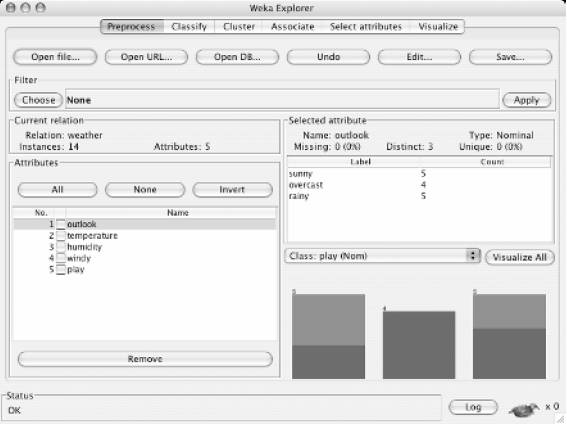 ШҙЩғЩ„ 3. Ш®ЩҲШ§ЩҶШҜЩҶ ЩҒШ§ЩҠЩ„ ШҜШ§ШҜЩҮ ЩҮШ§ЩҠ ШўШЁ ЩҲ ЩҮЩҲШ§ Weka Exphorer Ш§Щ…ЩғШ§ЩҶ ШұШҜЩҮ ШЁЩҶШҜЩҠ ШҜШ§ШұШҜШҢ ЪҶЩҶШ§ЩҶЪҶЩҮ ШЁЩҮ ЩғШ§ШұШЁШұШ§ЩҶ Ш§Ш¬Ш§ШІЩҮ Щ…ЩҠвҖҸ ШҜЩҮШҜ ШЁЩҮ ШөЩҲШұШӘ ШӘШ№Ш§Щ…Щ„ЩҠ Ш§ЩӮШҜШ§Щ… ШЁЩҮ ШіШ§Ш®ШӘ ШҜШұШ®ШӘ ШӘШөЩ…ЩҠЩ…вҖҸЪҜЩҠШұЩҠ ЩғЩҶЩҶШҜ. Weka ЩҶЩ…ЩҲШҜШ§Шұ ЩҫШұШ§ЩғЩҶШҜЪҜЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШұШ§ ЩҶШіШЁШӘ ШЁЩҮ ШҜЩҲ ЩҲЩҠЪҳЪҜЩҠ Ш§ЩҶШӘШ®Ш§ШЁ ШҙШҜЩҮШҢ ЩҒШұШ§ЩҮЩ… Щ…ЩҠвҖҸ ШўЩҲШұШҜ. ЩҲЩӮШӘЩҠ ШІЩҲШ¬ ЩҲЩҠЪҳЪҜЩҠВӯШ§ЩҠ ЩғЩҮ ШұШҜЩҮ вҖҸЩҮШ§ ШұШ§ ШЁЩҮ Ш®ЩҲШЁЩҠ Ш¬ШҜШ§ Щ…ЩҠвҖҸ ЩғЩҶШҜШҢ ЩҫЩҠШҜШ§ ШҙШҜШҢ Ш§Щ…ЩғШ§ЩҶ Ш§ЩҠШ¬Ш§ШҜ ШҜЩҲ ШҙШ§Ш®ЩҮ ШЁШ§ ЩғШҙЩҠШҜЩҶ ЪҶЩҶШҜ Ш¶Щ„Ш№ЩҠ Ш§Ш·ШұШ§ЩҒ ЩҶЩӮШ§Ш· ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШЁШұ ЩҶЩ…ЩҲШҜШ§Шұ ЩҫШұШ§ЩғЩҶШҜЪҜЩҠ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ.  ШҙЩғЩ„ 4. ЩҶЩҲШ§Шұ Classify ЩҮШұ ЩҶЩҲШ§ШұШҢ ШҜШіШӘШұШіЩҠ ШЁЩҮ ШҜШ§Щ…ЩҶЩҮ ЩғШ§Щ…Щ„ЩҠ Ш§ШІ Ш§Щ…ЩғШ§ЩҶШ§ШӘ ШұШ§ ЩҒШұШ§ЩҮЩ… Щ…ЩҠ ЩғЩҶШҜ. ШҜШұ ЩҫШ§ЩҠЩҠЩҶ ЩҮШұ ЩҫШ§ЩҶЩ„ШҢ Ш¬Ш№ШЁЩҮ status ЩҲ ШҜЩғЩ…ЩҮ log ЩӮШұШ§Шұ ШҜШ§ШұШҜ. Ш¬Ш№ШЁЩҮ status ЩҫЩҠШәШ§Щ… вҖҸЩҮШ§ЩҠЩҠ Ш§ШіШӘ ЩғЩҮ ЩҶШҙШ§ЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ЪҶЩҮ Ш№Щ…Щ„ЩҠШ§ШӘЩҠ ШҜШұ ШӯШ§Щ„ Ш§ЩҶШ¬Ш§Щ… ШҜШ§ШҜЩҮ ШҙШҜЩҶ Ш§ШіШӘ. Щ…Ш«Щ„Ш§ЩӢ Ш§ЪҜШұ Explores Щ…ШҙШәЩҲЩ„ Ш®ЩҲШ§ЩҶШҜЩҶ ЩҠЩғ ЩҒШ§ЩҠЩ„ ШЁШ§ШҙШҜШҢ Ш¬Ш№ШЁЩҮ status ШўЩҶ ШұШ§ ЪҜШІШ§ШұШҙ Щ…ЩҠвҖҸ ШҜЩҮШҜ. ЩғЩ„ЩҠЩғ ШұШ§ШіШӘ ШҜШұ ЩҮШұ Ш¬Ш§ ШҜШ§Ш®Щ„ Ш§ЩҠЩҶ Ш¬Ш№ШЁЩҮ ЩҠЩғ Щ…ЩҶЩҲ ЩғЩҲЪҶЩғ ШЁШ§ ШҜЩҲ ЪҜШІЩҠЩҶЩҮ Щ…ЩҠвҖҸ ШўЩҲШұШҜШҢ ЩҶЩ…Ш§ЩҠШҙ Щ…ЩҠШІШ§ЩҶ ШӯШ§ЩҒШёЩҮ ШҜШұ ШҜШіШӘШұШі Weka ЩҲ Ш§Ш¬ШұШ§ЩҠ Java garbage collector .. Щ„Ш§ШІЩ… Ш§ШіШӘ ШӘЩҲШ¬ЩҮ ШҙЩҲШҜ ЩғЩҮ garbage collector ШЁЩҮ Ш·ЩҲШұ Ш«Ш§ШЁШӘ ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҠЩғ Ш№Щ…Щ„ ЩҫЩҠШҙ ШІЩ…ЩҠЩҶЩҮ [25] ШҜШұ ЩҮШұ ШӯШ§Щ„ Ш§Ш¬ШұШ§ Щ…ЩҠвҖҸ ШҙЩҲШҜ ЩғЩ„ЩҠЩғ ШҜЩғЩ…ЩҮ log ШҢ ЪҜШІШ§ШұШҙ Ш№Щ…Щ„ЩғШұШҜ Щ…ШӘЩҶЩҠ ЩғШ§ШұЩҮШ§ЩҠЩҠ ЩғЩҮ Weka ШӘШ§ЩғЩҶЩҲЩҶ ШҜШұ Ш§ЩҠЩҶ ШЁШ®Шҙ Ш§ЩҶШ¬Ш§Щ… ШҜШ§ШҜЩҮ Ш§ШіШӘ ШЁШ§ ШЁШұЪҶШіШЁ ШІЩ…Ш§ЩҶЩҠ Ш§ШұШ§ЩҠЩҮ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ШІЩ…Ш§ЩҶЩҠЩғЩҮ Weka ШҜШұ ШӯШ§Щ„ Ш№Щ…Щ„ЩҠШ§ШӘ Ш§ШіШӘШҢ ЩҫШұЩҶШҜЩҮ ЩғЩҲЪҶЩғЩҠ ЩғЩҮ ШҜШұ ЩҫШ§ЩҠЩҠЩҶ ШіЩ…ШӘ ШұШ§ШіШӘ ЩҫЩҶШ¬ШұЩҮ Ш§ШіШӘШҢ ШЁШ§Щ„Ш§ ЩҲ ЩҫШ§ЩҠЩҠЩҶ Щ…ЩҠвҖҸ ЩҫШұШҜ. Ш№ШҜШҜ ЩҫШҙШӘ Г— ЩҶШҙШ§ЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ЩғЩҮ ШЁЩҮ Ш·ЩҲШұ ЩҮЩ…ШІЩ…Ш§ЩҶ ЪҶЩҶШҜ Ш№Щ…Щ„ЩҠШ§ШӘ ШҜШұ ШӯШ§Щ„ Ш§ЩҶШ¬Ш§Щ… Ш§ШіШӘ. Ш§ЪҜШұ ЩҫШұЩҶШҜЩҮ ШЁШ§ЩҠШіШӘШҜ ШҜШұ ШӯШ§Щ„ЩҠЩғЩҮ ШӯШұЩғШӘ ЩҶЩ…ЩҠвҖҸ ЩғЩҶШҜШҢ Ш§ЩҲ Щ…ШұЩҠШ¶ Ш§ШіШӘ! Ш§ШҙШӘШЁШ§ЩҮ ШұШ® ШҜШ§ШҜЩҮ Ш§ШіШӘ ЩҲ ШЁШ§ЩҠШҜ Explorer Ш§ШІ ЩҶЩҲ Ш§Ш¬ШұШ§ ШҙЩҲШҜ. 1. Ш®ЩҲШ§ЩҶШҜЩҶ ЩҲ ЩҒЩҠЩ„ШӘШұ ЩғШұШҜЩҶ ЩҒШ§ЩҠЩ„ вҖҸЩҮШ§ ШҜШұ ШЁШ§Щ„Ш§ЩҠ ЩҫШ§ЩҶЩ„ Preprocess ШҜШұ ШҙЩғЩ„ 3ШҢ ШҜЩғЩ…ЩҮ вҖҸЩҮШ§ЩҠЩҠ ШЁШұШ§ЩҠ ШЁШ§ШІ ЩғШұШҜЩҶ ЩҒШ§ЩҠЩ„ШҢ URL вҖҸЩҮШ§ ЩҲ ЩҫШ§ЩҠЪҜШ§ЩҮ ЩҮШ§ЩҠ ШҜШ§ШҜЩҮ вҖҸ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ. ШҜШұ Ш§ШЁШӘШҜШ§ ШӘЩҶЩҮШ§ ЩҒШ§ЩҠЩ„ вҖҸЩҮШ§ЩҠ ШЁШ§ ЩҫШіЩҲЩҶШҜ arff . ШҜШұ browser ЩҒШ§ЩҠЩ„ ЩҶЩ…Ш§ЩҠШҙ ШҜШ§ШҜЩҮ Щ…ЩҠвҖҸ ШҙЩҲШҜ. ШЁШұШ§ЩҠ ШҜЩҠШҜЩҶ ШіШ§ЩҠШұ ЩҒШ§ЩҠЩ„ вҖҸЩҮШ§ ЩҠШ§ЩҠШҜ ЪҜШІЩҠЩҶЩҮ [26] Format ШҜШұ Ш¬Ш№ШЁЩҮ Ш§ЩҶШӘШ®Ш§ШЁ ЩҒШ§ЩҠЩ„ ШӘШәЩҠЩҠШұ ШҜШ§ШҜЩҮ ШҙЩҲШҜ. 2. ШӘШЁШҜЩҠЩ„ ЩҒШ§ЩҠЩ„ вҖҸЩҮШ§ ШЁЩҮ ЩҒШұЩ…ШӘ ARFF ЩҶШұЩ… Ш§ЩҒШІШ§Шұ Weka ШҜШ§ШұШ§ЩҠ ШіЩҮ Щ…ШЁШҜЩ„ ЩҒШұЩ…ШӘ ЩҒШ§ЩҠЩ„ [27] Щ…ЩҠвҖҸ ШЁШ§ШҙШҜШҢ ШЁШұШ§ЩҠ ЩҒШ§ЩҠЩ„ вҖҸЩҮШ§ЩҠ ШөЩҒШӯЩҮ ЪҜШіШӘШұШҜЩҮ [28] ШЁШ§ ЩҫШіЩҲЩҶШҜ CSV ШҢ ШЁШ§ ЩҒШұЩ…ШӘ ЩҒШ§ЩҠЩ„ C4.5 ШЁШ§ ЩҫШіЩҲЩҶШҜ names . ЩҲ data ЩҲ ШЁШұШ§ЩҠ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШіШұЩҠ ШЁШ§ ЩҫШіЩҲЩҶШҜ bsi . Ш§ЪҜШұ Weka ЩӮШ§ШҜШұ ШЁЩҮ Ш®ЩҲШ§ЩҶШҜЩҶ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ЩҶШЁШ§ШҙШҜШҢ ШіШ№ЩҠ Щ…ЩҠвҖҸ ЩғЩҶШҜ ШўЩҶ ШұШ§ ШЁЩҮ ШөЩҲШұШӘ ARFF ШӘЩҒШіЩҠШұ ЩғЩҶШҜ. Ш§ЪҜШұ ЩҶШӘЩҲШ§ЩҶШҜ Ш¬Ш№ШЁЩҮ ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮ ШҙШҜЩҮ ШҜШұ ШҙЩғЩ„ 5 (Ш§Щ„ЩҒ) ШёШ§ЩҮШұ Щ…ЩҠвҖҸ ШҙЩҲШҜ.  (Ш§Щ„ЩҒ)  (ШЁ)  (Ш¬) ШҙЩғЩ„ 5. ЩҲЩҠШұШ§ЩҠШҙЪҜШұ Ш№Щ…ЩҲЩ…ЩҠ Ш§ШҙЩҠШ§ШЎ (Ш§Щ„ЩҒ) ЩҲЩҠШұШ§ЩҠШҙЪҜШұ (ШЁ) Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ШЁЩҠШҙШӘШұ (ЩҒШҙШұШҜЩҶ ШҜЪҜЩ…ЩҮ More ) (Ш¬) Ш§ЩҶШӘШ®Ш§ШЁ ЩҠЩғ Щ…ШЁШҜЩ„ Ш§ЩҠЩҶШҢ ЩҠЩғ ЩҲЩҠШұШ§ЩҠШҙЪҜШұ Ш№Щ…ЩҲЩ…ЩҠ [29] Ш§ШҙЩҠШ§ШЎ Ш§ШіШӘ ЩғЩҮ ШҜШұ Weka ШЁШұШ§ЩҠ Ш§ЩҶШӘШ®Ш§ШЁ ЩҲ ШӘЩҶШёЩҠЩ… Ш§ШҙЩҠШ§ ШЁЩғШ§Шұ Щ…ЩҠвҖҸ ШұЩҲШҜ. ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ Щ…Ш«Ш§Щ„ ЩҲЩӮШӘЩҠ ЩҫШ§ШұШ§Щ…ШӘШұЩҠ ШЁШұШ§ЩҠ Classifier ШӘЩҶШёЩҠЩ… Щ…ЩҠвҖҸ ШҙЩҲШҜШҢ Ш¬Ш№ШЁЩҮ Ш§ЩҠ ШЁШ§ ЩҶЩҲШ№ Щ…ШҙШ§ШЁЩҮ ШЁЩғШ§Шұ ШЁШұШҜЩҮ Щ…ЩҠвҖҸ ШҙЩҲШҜ. CSV Loader ШЁШұШ§ЩҠ ЩҒШ§ЩҠЩ„ вҖҸЩҮШ§ЩҠ ШЁШ§ ЩҫШіЩҲЩҶШҜ CSV . ШЁЩҮ Ш·ЩҲШұ ЩҫЩҠШҙ ЩҒШұШ¶ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҠвҖҸ ШҙЩҲШҜ. ШҜЩғЩ…ЩҮ More Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ШЁЩҠШҙШӘШұЩҠ ШҜШұ Щ…ЩҲШұШҜ ШўЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ЩғЩҮ ШҜШұ ШҙЩғЩ„ 5 (ШЁ) ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮ ШҙШҜЩҮ Ш§ШіШӘ. ЩҮЩ…ЩҠШҙЩҮ Щ…Ш·Ш§Щ„Ш№ЩҮ Щ…ШіШӘЩҶШҜШ§ШӘ [30] Ш§ШұШІШҙЩ…ЩҶШҜШ§ШіШӘ! ШҜШұ Ш§ЩҠЩҶ ШӯШ§Щ„ШӘ ЩҶШҙШ§ЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ЩғЩҮ ШұШҜЩҠЩҒ ЩҶШ®ШіШӘ ШөЩҒШӯЩҮ ЪҜШіШӘШұШҜЩҮШҢ ЩҶШ§Щ… ЩҲЩҠЪҳЪҜЩҠ ШұШ§ ШӘШ№ЩҠЩҠЩҶ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ШЁШұШ§ЩҠ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Ш§ЩҠЩҶ Щ…ШЁШҜЩ„ ШЁШ§ЩҠШҜ ШЁШұ Ok ЩғЩ„ЩҠЩғ ШҙЩҲШҜ. ШЁШұШ§ЩҠ Щ…ЩҲШұШҜ Щ…Ш®ШӘЩ„ЩҒ Щ„Ш§ШІЩ… Ш§ШіШӘ ШЁШұ choose ЩғЩ„ЩҠЩғ ШҙЩҲШҜ ШӘШ§ Ш§ШІ Щ„ЩҠШіШӘ ШҙЩғЩ„ 5 (Ш¬) Ш§ЩҶШӘШ®Ш§ШЁ Ш§ЩҶШ¬Ш§Щ… ШҙЩҲШҜ. ЪҜШІЩҠЩҶЩҮ Ш§ЩҲЩ„ШҢ Arffloader Ш§ШіШӘ ЩҲ ЩҒЩӮШ· ШЁЩҮ ШҜЩ„ЩҠЩ„ ЩҶШ§Щ…ЩҲЩҒЩӮ ШЁЩҲШҜЩҶ ШЁЩҮ Ш§ЩҠЩҶ ЩҶЩӮШ·ЩҮ Щ…ЩҠвҖҸ ШұШіЩҠЩ…. CSVLoader ЩҫЩҠШҙ ЩҒШұШ¶ Ш§ШіШӘ ЩҲ ШҜШұ ШөЩҲШұШӘ ЩҶЩҠШ§ШІ ШЁЩҮ ЩҒШұШ¶ ШҜЩҠЪҜШұШҢ choose ЩғЩ„ЩҠЩғ Щ…ЩҠвҖҸ ШҙЩҲШҜ. ШіЩҲЩ…ЩҠЩҶ ЪҜШІЩҠЩҶЩҮШҢ Щ…ШұШЁЩҲШ· ШЁЩҮ ЩҒШұЩ…ШӘ C4.5 Ш§ШіШӘ ЩғЩҮ ШҜЩҲ ЩҒШ§ЩҠЩ„ ШЁШұШ§ЩҠ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ ЩҠЩғЩҠ Ш§ШіЩ… вҖҸЩҮШ§ ЩҲ ШҜЩҠЪҜЩҖШұЩҠ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ЩҠ ЩҲШ§ЩӮШ№ЩҖЩҠ Щ…ЩҠвҖҸ ШЁШ§ШҙШҜ. ЪҶЩҮШ§ШұЩ…ЩҠЩҶ ШЁШұШ§ЩҠ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШіШұЩҠШ§Щ„ЩҠ [31] ШҢ ШЁШұШ§ЩҠ ШЁШ§ШІШ®ЩҲШ§ЩҶЩҠ [32] Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ Ш§ЩҠ Ш§ШіШӘ ЩғЩҮ ШЁЩҮ ШөЩҲШұШӘ ШҙЩҠШҰ ШіШұЩҠШ§Щ„ЩҠ ШҙШҜЩҮ Ш¬Ш§ЩҲШ§ Ш°Ш®ЩҠШұЩҮ ШҙШҜЩҮ Ш§ШіШӘ. ЩҮШұ ШҙЩҠШЎ ШҜШұ Ш¬Ш§ЩҲШ§ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШҜШұ Ш§ЩҠЩҶ ШҙЩғЩ„ Ш°Ш®ЩҠШұЩҮ ЩҲ ШЁШ§ШІШ®ЩҲШ§ЩҶЩҠ ШҙЩҲШҜ. ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҠЩғ ЩҒШұЩ…ШӘ ШЁЩҲЩ…ЩҠ Ш¬Ш§ЩҲШ§ [33] ШҢ ШіШұЩҠШ№ ШӘШұ Ш§ШІ ЩҒШ§ЩҠЩ„ ARFF Ш®ЩҲШ§ЩҶШҜЩҮ Щ…ЩҠвҖҸ ШҙЩҲШҜ ЪҶШұШ§ ЩғЩҮ ЩҒШ§ЩҠЩ„ ARFF ШЁШ§ЩҠШҜ ШӘШ¬ШІЩҠЩҮ [34] ЩҲ ЩғЩҶШӘШұЩ„ ШҙЩҲШҜ. ЩҲЩӮШӘЩҠ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ШЁШІШұЪҜ Щ…ЩғШұШұШ§ ШЁШ§ШІШ®ЩҲШ§ЩҶЩҠ Щ…ЩҠвҖҸ ШҙЩҲШҜШҢ Ш°Ш®ЩҠШұЩҮ ШўЩҶ ШҜШұ Ш§ЩҠЩҶ ШҙЩғЩ„ ШіЩҲШҜЩ…ЩҶШҜ Ш§ШіШӘ. ЩҲЩҠЪҳЪҜЩҠвҖҸЩҮШ§ЩҠ ШҜЩҠЪҜШұ ЩҲЩҠШұШ§ЩҠШҙЪҜШұ Ш№Щ…ЩҲЩ…ЩҠ Ш§ШҙЩҠШ§ ШҜШұ ШҙЩғЩ„ 5 (Ш§Щ„ЩҒ)ШҢ save ЩҲ open Ш§ШіШӘ ЩғЩҮ ШЁЩҮ ШӘШұШӘЩҠШЁ ШЁШұШ§ЩҠ Ш°Ш®ЩҠШұЩҮ Ш§ШҙЩҠШ§ЩҠ ШӘЩҶШёЩҠЩ… ШҙШҜЩҮ ЩҲ ШЁШ§ШІЩғШұШҜЩҶ ШҙЩҠШҰЩҠ ЩғЩҮ ЩҫЩҠШҙ Ш§ШІ Ш§ЩҠЩҶ Ш°Ш®ЩҠШұЩҮ ШҙШҜЩҮ Ш§ШіШӘШҢ ШЁЩҮ ЩғШ§Шұ Щ…ЩҠ ШұЩҲШҜ. Ш§ЩҠЩҶЩҮШ§ ШЁШұШ§ЩҠ Ш§ЩҠЩҶ ЩҶЩҲШ№ Ш®Ш§Шө ШҙЩҠШҰ Щ…ЩҒЩҠШҜ ЩҶЩҠШіШӘЩҶШҜ. Щ„ЩғЩҶ ЩҫШ§ЩҶЩ„ вҖҸЩҮШ§ЩҠ ШҜЩҠЪҜШұ ЩҲЩҠШұШ§ЩҠШҙЪҜШұ Ш№Щ…ЩҲЩ…ЩҠ Ш§ШҙЩҠШ§ШЎШҢ Ш®ЩҲШ§Шө ЩӮШ§ШЁЩ„ ЩҲЩҠШұШ§ЩҠШҙ ШІЩҠШ§ШҜЩҠ ШҜШ§ШұЩҶШҜ. ШЁЩҮ ШҜЩ„ЩҠЩ„ Щ…ШҙЩғЩ„Ш§ШӘЩҠ ЩғЩҮ Щ…Щ…ЩғЩҶ Ш§ШіШӘ ШӯЩҠЩҶ ШӘЩҶШёЩҠЩ… Щ…Ш¬ШҜШҜ ШўЩҶЩҮШ§ ШұШ® ШҜЩҮШҜШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШӘШұЩғЩҠШЁ Ш§ШҙЩҠШ§ШЎ Ш§ЩҠШ¬Ш§ШҜ ШҙШҜЩҮ ШұШ§ ШЁШұШ§ЩҠ Ш§ШіШӘЩҒШ§ШҜЩҮ вҖҸЩҮШ§ЩҠ ШЁШ№ШҜЩҠШҢ Ш°Ш®ЩҠШұЩҮ ЩғШұШҜ. ШӘЩҶЩҮШ§ Щ…ЩҶШЁШ№ [35] Щ…Ш¬Щ…ЩҲШ№ЩҮ вҖҸЩҮШ§ЩҠ ШҜШ§ШҜЩҮ ШЁШұШ§ЩҠ Weka ШҢ ЩҒШ§ЩҠЩ„ вҖҸЩҮШ§ЩҠ Щ…ЩҲШ¬ЩҲШҜ ШұЩҲЩҠ ЩғШ§Щ…ЩҫЩҠЩҲШӘШұ ЩҶЩҠШіШӘЩҶШҜ. Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ЩҠЩғ URL ШұШ§ ШЁШ§ШІ ЩғШұШҜ ШӘШ§ Weka Ш§ШІ ЩҫШұЩҲШӘЩғЩ„ HTTP ШЁШұШ§ЩҠ ШҜШ§ЩҶЩ„ЩҲШҜ ЩғШұШҜЩҶ ЩҠЩғ ЩҒШ§ЩҠЩ„ Arff Ш§ШІ ШҙШЁЩғЩҮ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩғЩҶШҜ. ЩҮЩ…ЪҶЩҶЩҠЩҶ Щ…ЩҠвҖҸШӘЩҲШ§ЩҶ ЩҠЩғ ЩҫШ§ЩҠЪҜШ§ЩҮ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШұШ§ ШЁШ§ШІ ЩҶЩ…ЩҲШҜ ( open DB ЩҖ ЩҮШұ ЩҫШ§ЩҠЪҜШ§ЩҮ ШҜШ§ШҜЩҮ Ш§ЩҠ ЩғЩҮ ШҜШұШ§ЩҠЩҲШұ Ш§ШӘШөШ§Щ„ ШЁЩҮ Щ…Ш¬Щ…ЩҲШ№ЩҮ ЩҮШ§ЩҠ ШҜШ§ШҜЩҮ ШЁЩҮ ШІШЁШ§ЩҶ Ш¬Ш§ЩҲШ§ JDBC ШұШ§ ШҜШ§ШұШҜ.) ЩҲ ШЁЩҮ ЩҲШіЩҠЩ„ЩҮ ШҜШіШӘЩҲШұ select ШІШЁШ§ЩҶ SQL ШҢ ЩҶЩ…ЩҲЩҶЩҮ вҖҸвҖҸЩҮШ§ ШұШ§ ШЁШ§ШІЩҠШ§ШЁЩҠ ЩҶЩ…ЩҲШҜ. ШҜШ§ШҜЩҮ вҖҸЩҮШ§ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶЩҶШҜ ШЁЩҮ ЩғЩ…Щғ ШҜЪҜЩ…ЩҮ save ШЁЩҮ ЩҮЩ…ЩҮ ЩҒШұЩ…ШӘ вҖҸЩҮШ§ЩҠ Ш°ЩғШұ ШҙШҜЩҮШҢ Ш°Ш®ЩҠШұЩҮ ШҙЩҲЩҶШҜ. Ш¬ШҜШ§ЩҠ Ш§ШІ ШЁШӯШ« ШЁШ§ШұЪҜШ°Ш§ШұЩҠ ЩҲ Ш°Ш®ЩҠШұЩҮ Щ…Ш¬Щ…ЩҲШ№ЩҮ вҖҸЩҮШ§ЩҠ ШҜШ§ШҜЩҮШҢ ЩҫШ§ЩҶЩ„ preprocess ШЁЩҮ ЩғШ§ШұШЁШұ Ш§Ш¬Ш§ШІЩҮ ЩҒЩҠЩ„ШӘШұ ЩғШұШҜЩҶ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ ШұШ§ Щ…ЩҠвҖҸ ШҜЩҮШҜ. ЩҒЩҠЩ„ШӘШұЩҮШ§ШҢ Ш§Ш¬ШІШ§ЩҠ Щ…ЩҮЩ… Weka ЩҮШіШӘЩҶШҜ. 3. ШЁЩғШ§ШұЪҜЩҠШұЩҠ ЩҒЩҠЩ„ШӘШұЩҮШ§ ШЁШ§ ЩғЩ„ЩҠЩғ ШҜЪҜЩ…ЩҮ choose (ЪҜЩҲШҙЩҮ ШЁШ§Щ„Ш§ ЩҲ ШіЩ…ШӘ ЪҶЩҫ) ШҜШұ ШҙЩғЩ„ 3 Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШЁЩҮ Щ„ЩҠШіШӘЩҠ Ш§ШІ ЩҒЩҠЩ„ШӘШұЩҮШ§ ШҜШіШӘ ЩҠШ§ЩҒШӘ. Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ Ш§ШІ ЩҒЩҠЩ„ШӘШұЩҮШ§ ШЁШұШ§ЩҠ ШӯШ°ЩҒ ЩҲЩҠЪҳЪҜЩҠвҖҸЩҮШ§ЩҠ Щ…ЩҲШұШҜ ЩҶШёШұЩҠ Ш§ШІ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ ШҜШ§ШҜЩҮ ЩҲ Ш§ЩҶШӘШ®Ш§ШЁ ШҜШіШӘЩҠ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩҶЩ…ЩҲШҜ. Щ…ШҙШ§ШЁЩҮ Ш§ЩҠЩҶ ЩҶШӘЩҠШ¬ЩҮ ШұШ§ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШЁЩҮ ЩғЩ…Щғ Ш§ЩҶШӘШ®Ш§ШЁ ЩҲЩҠЪҳЪҜЩҠвҖҸЩҮШ§ЩҠ Щ…ЩҲШұШҜ ЩҶШёШұ ШЁШ§ ШӘЩҠЩғ ШІШҜЩҶ ШўЩҶЩҮШ§ ЩҲ ЩҒШҙШ§Шұ ШҜШ§ШҜЩҶ ЩғЩ„ЩҠЩҮ Remove ШЁЩҮ ШҜШіШӘ ШўЩҲШұШҜ. 4. Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ШІЩ…Ш§ЩҶЩҠ ЩғЩҮ ЩҠЩғ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… ЩҠШ§ШҜЪҜЩҠШұЩҠ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШҜЪҜЩ…ЩҮ choose ШҜШұ ЩҫШ§ЩҶЩ„ classify Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҠвҖҸ ШҙЩҲШҜШҢ ЩҶШіШ®ЩҮ Ш®Ш· ЩҒШұЩ…Ш§ЩҶЩҠ ШұШҜЩҮ ШЁЩҶШҜ ШҜШұ ШіШ·ШұЩҠ ЩҶШІШҜЩҠЩғ ШЁЩҮ ШҜЪҜЩ…ЩҮ ШёШ§ЩҮШұ Щ…ЩҠвҖҸ ЪҜШұШҜШҜ. Ш§ЩҠЩҶ Ш®Ш· ЩҒШұЩ…Ш§ЩҶ ШҙШ§Щ…Щ„ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЩҠ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… Ш§ШіШӘ ЩғЩҮ ШЁШ§ Ш®Ш· ШӘЩҠШұЩҮ Щ…ШҙШ®Шө Щ…ЩҠвҖҸВӯШҙЩҲЩҶШҜ. ШЁШұШ§ЩҠ ШӘШәЩҠЩҠШұ ШўЩҶЩҮШ§ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶ ШұЩҲЩҠ ШўЩҶ Ш®Ш· ЩғЩ„ЩҠЩғ ЩҶЩ…ЩҲШҜ ШӘШ§ ЩҲЩҠШұШ§ЩҠШҙЪҜШұ Щ…ЩҶШ§ШіШЁ ШҙЩҠШЎШҢ ШЁШ§ШІ ШҙЩҲШҜ. Ш¬ШҜЩҲЩ„ ШҙЩғЩ„ 6ШҢ Щ„ЩҠШіШӘ Ш§ШіШ§Щ…ЩҠ ШұШҜЩҮ ШЁЩҶШҜЩҮШ§ЩҠ Weka ШұШ§ ЩҶЩ…Ш§ЩҠШҙ Щ…ЩҠвҖҸ ШҜЩҮШҜ. Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… вҖҸЩҮШ§ ШЁЩҮ ШұШҜЩҮ ШЁЩҶШҜЩҮШ§ЩҠ Bayesian ШҢ trees ШҢ functions rules ШҢ lazy ЩҲ ШҜШіШӘЩҮ ЩҶЩҮШ§ЩҠЩҠ ШҙШ§Щ…Щ„ ШұЩҲШҙ вҖҸЩҮШ§ЩҠ Щ…ШӘЩҒШұЩӮЩҮ ШӘЩӮШіЩҠЩ… ШҙШҜЩҮ Ш§ЩҶШҜ. 4-1. Trees Decision stump ЩғЩҮ ШЁШұШ§ЩҠ Ш§ШіШӘЩҒШ§ШҜЩҮ ШӘЩҲШіШ· ШұЩҲШҙ вҖҸЩҮШ§ЩҠ boosting Ш·ШұШ§ШӯЩҠ ШҙШҜЩҮ Ш§ШіШӘШҢ ШЁШұШ§ЩҠ Щ…Ш¬Щ…ЩҲШ№ЩҮ вҖҸЩҮШ§ЩҠ ШҜШ§ШҜЩҮ Ш№ШҜШҜЩҠ ЩҠШ§ ШұШҜЩҮ Ш§ЩҠШҢ ШҜШұШ®ШӘ ШӘШөЩ…ЩҠЩ…вҖҸЪҜЩҠШұЩҠ ЩҠЩғ ШіШ·ШӯЩҠ Щ…ЩҠвҖҸ ШіШ§ШІШҜ. Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ШҢ ШЁШ§ Щ…ЩӮШ§ШҜЩҠШұ Ш§ШІ ШҜШіШӘ ШұЩҒШӘЩҮШҢ ШЁЩҮ ШөЩҲШұШӘ Щ…ЩӮШ§ШҜЩҠШұ Щ…Ш¬ШІШ§ ШЁШұШ®ЩҲШұШҜ ЩғШұШҜЩҮ ЩҲ ШҙШ§Ш®ЩҮ ШіЩҲЩ…ЩҠ Ш§ШІ ШҜШұШ®ШӘ ШӘЩҲШіШ№ЩҮ Щ…ЩҠвҖҸ ШҜЩҮШҜ. 4-2. Rules Decision Table ЩҠЩғ ШұШҜЩҮ ШЁЩҶШҜ ШЁШұ Ш§ШіШ§Ші Ш§ЩғШ«ШұЩҠШӘ Ш¬ШҜЩҲЩ„ ШӘШөЩ…ЩҠЩ…вҖҸЪҜЩҠШұЩҠ Щ…ЩҠвҖҸ ШіШ§ШІШҜ. Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ШҢ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Ш¬ШіШӘШ¬ЩҲЩҠ Ш§ЩҲЩ„ЩҠЩҶ ШЁЩҮШӘШұЩҠЩҶШҢ ШІЩҠШұ ШҜШіШӘЩҮ вҖҸЩҮШ§ЩҠ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ ШұШ§ Ш§ШұШІЩҠШ§ШЁЩҠ Щ…ЩҠвҖҸ ЩғЩҶШҜ ЩҲ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ Ш§ШІ Ш§Ш№ШӘШЁШ§ШұШіЩҶШ¬ЩҠ ШӘЩӮШ§Ш·Ш№ЩҠ ШЁШұШ§ЩҠ Ш§ШұШІЩҠШ§ШЁЩҠ ШЁЩҮШұЩҮ ШЁШЁШұШҜ (1995ШҢ Kohavi ). ЩҠЩғ Ш§Щ…ЩғШ§ЩҶ Ш§ЩҠЩҶ Ш§ШіШӘ ЩғЩҮ ШЁЩҮ Ш¬Ш§ЩҠ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Ш§ЩғШ«ШұЩҠШӘ Ш¬ШҜЩҲЩ„ ШӘШөЩ…ЩҠЩ…вҖҸЪҜЩҠШұЩҠ ЩғЩҮ ШЁШұ Ш§ШіШ§Ші ШҜШіШӘЩҮ ЩҲЩҠЪҳЪҜЩҠвҖҸЩҮШ§ЩҠ Щ…ШҙШ§ШЁЩҮ Ш№Щ…Щ„ Щ…ЩҠвҖҸВӯЩғЩҶШҜШҢ Ш§ШІ ШұЩҲШҙ ЩҶШІШҜЩҠЩғШӘШұЩҠЩҶ ЩҮЩ…ШіШ§ЩҠЩҮ ШЁШұШ§ЩҠ ШӘШ№ЩҠЩҠЩҶ ШұШҜЩҮ ЩҮШұ ЩҠЩғ Ш§ШІ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ ЩғЩҮ ШӘЩҲШіШ· Щ…ШҜШ®Щ„ [36] Ш¬ШҜЩҲЩ„ ШӘШөЩ…ЩҠЩ…вҖҸЪҜЩҠШұЩҠ ЩҫЩҲШҙШҙ ШҜШ§ШҜЩҮ ЩҶШҙШҜЩҮ Ш§ЩҶШҜШҢ Ш§ШіШӘЩҒШ§ШҜЩҮ ШҙЩҲШҜ. Conjunctive Rule ЩӮШ§Ш№ШҜЩҮ Ш§ЩҠ ШұШ§ ЩҠШ§ШҜ Щ…ЩҠвҖҸ ЪҜЩҠШұШҜ ЩғЩҮ Щ…ЩӮШ§ШҜЩҠШұ ШұШҜЩҮ вҖҸЩҮШ§ЩҠ Ш№ШҜШҜЩҠ ШұШ§ ШұШҜЩҮ Ш§ЩҠ ШұШ§ ЩҫЩҠШҙвҖҸШЁЩҠЩҶЩҠ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўШІЩ…Ш§ЩҠШҙЩҠ ШЁЩҮ Щ…ЩӮШ§ШҜЩҠШұ ЩҫЩҠШҙ ЩҒШұШ¶ ШұШҜЩҮ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўЩ…ЩҲШІШҙЩҠШҢ Щ…ЩҶШіЩҲШЁ Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜ. ШіЩҫШі ШӘЩӮЩҲЩҠШӘ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ (ШЁШұШ§ЩҠ ШұШҜЩҮ вҖҸЩҮШ§ЩҠ ШұШіЩ…ЩҠ)ШҢ ЩҠШ§ ЩғШ§ЩҮШҙ ЩҲШ§ШұЩҠШ§ЩҶШі (ШЁШұШ§ЩҠ ШұШҜЩҮ ЩҮШ§ЩҠ Ш№ШҜШҜЩҠ) Щ…ШұШЁЩҲШ· ШЁЩҮ ЩҮШұ ЩҲШ§Щ„ШҜ Щ…ШӯШ§ШіШЁЩҮ ШҙШҜЩҮ ЩҲ ШЁЩҮ ШұЩҲШҙ ЩҮШұШі ЩғШұШҜЩҶ ШЁШ§ Ш®Ш·Ш§ЩҠ ЩғШ§ЩҮШҙ ЩҠШ§ЩҒШӘЩҮ [37] ШҢ ЩӮЩҲШ§Ш№ШҜ ЩҮШұШі Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜ. ZeroR ШЁШұШ§ЩҠ ШұШҜЩҮ вҖҸЩҮШ§ЩҠ Ш§ШіЩ…ЩҠШҢ Ш§ЩғШ«ШұЩҠШӘ ШҜШ§ШҜЩҮ вҖҸЩҮШ§ЩҠ Щ…ЩҲШұШҜ ШўШІЩ…Ш§ЩҠШҙ ЩҲ ШЁШұШ§ЩҠ ШұШҜЩҮ вҖҸЩҮШ§ЩҠ Ш№ШҜШҜЩҠШҢ Щ…ЩҠШ§ЩҶЪҜЩҠЩҶ ШўЩҶЩҮШ§ ШұШ§ ЩҫЩҠШҙвҖҸШЁЩҠЩҶЩҠ Щ…ЩҠвҖҸ ЩғЩҶШҜ. Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… ШЁШіЩҠШ§Шұ ШіШ§ШҜЩҮ Ш§ШіШӘ. M5Rules ШҢ ШЁЩҮ ЩғЩ…Щғ M5 Ш§ШІ ШұЩҲЩҠ ШҜШұШ®ШӘ вҖҸЩҮШ§ЩҠ Щ…ШҜЩ„ШҢ ЩӮЩҲШ§Ш№ШҜ ШұЪҜШұШіЩҠЩҲЩҶ Ш§ШіШӘШ®ШұШ§Ш¬ Щ…ЩҠвҖҸ ЩғЩҶШҜ.  ШҙЩғЩ„ 6.Ш§Щ„ЩҒ. Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ЩҮШ§ЩҠ ШұШҜЩҮ ШЁЩҶШҜЩҠ ШҜШұ Weka  ШҙЩғЩ„ 6.ШЁ. Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ЩҮШ§ЩҠ ШұШҜЩҮ ШЁЩҶШҜЩҠ ШҜШұ Weka ШҜШұ Ш§ЩҠЩҶ ШЁШ®Шҙ ШЁЩҮ ШҙШұШӯ Щ…Ш®ШӘШөШұЩҠ ШЁШұШ®ЩҠ Ш§ШІ Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ЩҮШ§ ЩҲ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЩҠШҙШ§ЩҶ ЩғЩҮ ЩӮШ§ШЁЩ„ЩҠШӘ ЩғШ§Шұ ШЁШ§ ЩҲЩҠЪҳЪҜЩҠ ЩҮШ§ЩҠ Ш№ШҜШҜЩҠ ШұШ§ ШҜШ§ШұЩҶШҜШҢ ЩҫШұШҜШ§Ш®ШӘЩҮ Щ…ЩҠвҖҸ ШҙЩҲШҜ. 4-3. Functions Simple Linear Regresion Щ…ШҜЩ„ ШұЪҜШұШіЩҠЩҲЩҶ Ш®Ш·ЩҠ ЩҠЩғ ЩҲЩҠЪҳЪҜЩҠ Щ…ШҙШ®Шө ШұШ§ ЩҠШ§ШҜ Щ…ЩҠвҖҸ ЪҜЩҠШұШҜ. ШўЩҶЪҜШ§ЩҮ Щ…ШҜЩ„ ШЁШ§ ЩғЩ…ШӘШұЩҠЩҶ Ш®Ш·Ш§ЩҠ Щ…ШұШЁШ№Ш§ШӘ ШұШ§ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ШҜШұ Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ШҢ Щ…ЩӮШ§ШҜЩҠШұ Ш§ШІ ШҜШіШӘ ШұЩҒШӘЩҮ ЩҲ Щ…ЩӮШ§ШҜЩҠШұ ШәЩҠШұШ№ШҜШҜЩҠ Щ…Ш¬Ш§ШІ ЩҶЩҠШіШӘЩҶШҜ [38] . Linear Regression ШұЪҜШұШіЩҠЩҲЩҶ Ш®Ш·ЩҠ Ш§ШіШӘШ§ЩҶШҜШ§ШұШҜ ЩғЩ…ШӘШұЩҠЩҶ Ш®Ш·Ш§ЩҠ Щ…ШұШЁШ№Ш§ШӘ ШұШ§ Ш§ЩҶШ¬Ш§Щ… Щ…ЩҠвҖҸ ШҜЩҮШҜ Щ…ЩҠвҖҸШӘЩҲШ§ЩҶШҜ ШЁЩҮ Ш·ЩҲШұ Ш§Ш®ШӘЩҠШ§ШұЩҠ ШЁЩҮ Ш§ЩҶШӘШ®Ш§ШЁ ЩҲЩҠЪҳЪҜЩҠ ШЁЩҫШұШҜШ§ШІШҜШҢ Ш§ЩҠЩҶ ЩғШ§Шұ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШЁЩҮ ШөЩҲШұШӘ ШӯШұЩҠШөШ§ЩҶЩҮ [39] ШЁШ§ ШӯШ°ЩҒ Ш№ЩӮШЁ ШұЩҲЩҶШҜЩҮ [40] Ш§ЩҶШ¬Ш§Щ… ШҙЩҲШҜШҢ ЩҠШ§ ШЁШ§ ШіШ§Ш®ШӘЩҶ ЩҠЩғ Щ…ШҜЩ„ ЩғШ§Щ…Щ„ Ш§ШІ ЩҮЩ…ЩҮ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ ЩҲ ШӯШ°ЩҒ ЩҠЩғЩҠ ЩҠЩғЩҠ Ш¬Щ…Щ„ЩҮ вҖҸЩҮШ§ ШЁШ§ ШӘШұШӘЩҠШЁ ЩҶШІЩҲЩ„ЩҠ Ш¶ШұШ§ЩҠШЁ Ш§ШіШӘШ§ЩҶШҜШ§ШұШҜ ШҙШҜЩҮ ШўЩҶЩҮШ§ШҢ ШӘШ§ ШұШіЩҠШҜЩҶ ШЁЩҮ ШҙШұШ· ШӘЩҲЩӮЩҒ Щ…Ш·Щ„ЩҲШЁ Ш§ЩҶШ¬Ш§Щ… ЪҜЩҠШұШҜ. Least Med sq ЩҠЩғ ШұЩҲШҙ ШұЪҜШұШіЩҠЩҲЩҶ Ш®Ш·ЩҠ Щ…ЩӮШ§ЩҲЩ… Ш§ШіШӘ ЩғЩҮ Щ…ЩҠШ§ЩҶЩҮ [41] (ШЁЩҮ Ш¬Ш§ЩҠ Щ…ЩҠШ§ЩҶЪҜЩҠЩҶ [42] ) Щ…ШұШЁШ№Ш§ШӘ Ш§ЩҶШӯШұШ§ЩҒ Ш§ШІ Ш®Ш· ШұЪҜШұШіЩҠЩҲЩҶ ШұШ§ ЩғЩ…ЩҠЩҶЩҮ Щ…ЩҠвҖҸ ЩғЩҶШҜ. Ш§ЩҠЩҶ ШұЩҲШҙ ШЁЩҮ Ш·ЩҲШұ Щ…ЩғШұШұ ШұЪҜШұШіЩҠЩҲЩҶ Ш®Ш·ЩҠ Ш§ШіШӘШ§ЩҶШҜШ§ШұШҜ ШұШ§ ШЁЩҮ ШІЩҠШұЩ…Ш¬Щ…ЩҲШ№ЩҮ вҖҸЩҮШ§ЩҠЩҠ Ш§ШІ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ Ш§Ш№Щ…Ш§Щ„ Щ…ЩҠвҖҸВӯЩғЩҶШҜ ЩҲ ЩҶШӘШ§ЩҠШ¬ЩҠ ШұШ§ ШЁЩҠШұЩҲЩҶ Щ…ЩҠвҖҸ ШҜЩҮШҜ ЩғЩҮ ЩғЩ…ШӘШұЩҠЩҶ Ш®Ш·Ш§ЩҠ Щ…ШұШЁШ№ Щ…ЩҠШ§ЩҶЩҮ ШұШ§ ШҜШ§ШұЩҶШҜ. SMO teg Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… ШЁЩҮЩҠЩҶЩҮ ШіШ§ШІЩҠ ШӯШҜШ§ЩӮЩ„ ШӘШұШӘЩҠШЁЩҠ ШұШ§ ШұЩҲЩҠ Щ…ШіШ§ЩҠЩ„ ШұЪҜШұШіЩҠЩҲЩҶ Ш§Ш№Щ…Ш§Щ„ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ( Scholkopf, 1998 ШҢ Smola ) Pace Regression ШҢ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШӘЩғЩҶЩҠЩғ ШұЪҜШұШіЩҠЩҲЩҶ pace ШҢ Щ…ШҜЩ„ вҖҸЩҮШ§ЩҠ ШұЪҜШұШіЩҠЩҲЩҶ Ш®Ш·ЩҠ ШӘЩҲЩ„ЩҠШҜ Щ…ЩҠвҖҸ ЩғЩҶШҜ (2002 ШҢ Wang ЩҲ Witten ). ШұЪҜШұШіЩҠЩҲЩҶ pace ШҢ ШІЩ…Ш§ЩҶЩҠ ЩғЩҮ ШӘШ№ШҜШ§ШҜ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ Ш®ЩҠЩ„ЩҠ ШІЩҠШ§ШҜ Ш§ШіШӘШҢ ШЁЩҮ Ш·ЩҲШұ ЩҲЩҠЪҳЩҮ Ш§ЩҠ ШҜШұ ШӘШ№ЩҠЩҠЩҶ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ЩҠЩҠ ЩғЩҮ ШЁШ§ЩҠШҜ ШөШұЩҒвҖҸЩҶШёШұ ШҙЩҲЩҶШҜШҢ Ш®ЩҲШЁ Ш№Щ…Щ„ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ШҜШұ ЩҲШ§ЩӮШ№ ШҜШұ ШөЩҲШұШӘ ЩҲШ¬ЩҲШҜ ЩҶШёЩ… ЩҲ ШӘШұШӘЩҠШЁ Ш®Ш§ШөЩҠШҢ Ш«Ш§ШЁШӘ Щ…ЩҠвҖҸ ШҙЩҲШҜ ЩғЩҮ ШЁШ§ ШЁЩҠ ЩҶЩҮШ§ЩҠШӘ ШҙШҜЩҶ ШӘШ№ШҜШ§ШҜ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ШҢ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… ШЁЩҮЩҠЩҶЩҮ Ш№Щ…Щ„ Щ…ЩҠвҖҸ ЩғЩҶШҜ. RBF Network ШҢ ЩҠЩғ ШҙШЁЩғЩҮ ШЁШ§ ШӘШ§ШЁШ№ ЩҫШ§ЩҠЩҮ Ш§ЩҠ ЪҜЩҲШіЩҠ ШҙШ№Ш§Ш№ЩҠ ШұШ§ ЩҫЩҠШ§ШҜЩҮ ШіШ§ШІЩҠ Щ…ЩҠвҖҸ ЩғЩҶШҜ. Щ…ШұШ§ЩғШІ ЩҲ Ш№ШұШ¶ вҖҸЩҮШ§ЩҠ ЩҲШ§ШӯШҜЩҮШ§ЩҠ Щ…Ш®ЩҒЩҠ ШЁЩҮ ЩҲШіЩҠЩ„ЩҮ ШұЩҲШҙ Щ…ЩҠШ§ЩҶЪҜЩҠЩҶ K [43] ШӘШ№ЩҠЩҠЩҶ Щ…ЩҠвҖҸ ШҙЩҲШҜ. ШіЩҫШі Ш®ШұЩҲШ¬ЩҠ вҖҸЩҮШ§ЩҠ ЩҒШұШ§ЩҮЩ… ШҙШҜЩҮ Ш§ШІ Щ„Ш§ЩҠЩҮ вҖҸЩҮШ§ЩҠ Щ…Ш®ЩҒЩҠ [44] ШҢ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШұЪҜШұШіЩҠЩҲЩҶ Щ…ЩҶШ·ЩӮЩҠ ШҜШұ Щ…ЩҲШұШҜ ШұШҜЩҮ вҖҸЩҮШ§ЩҠ Ш§ШіЩ…ЩҠ ЩҲ ШұЪҜШұШіЩҠЩҲЩҶ Ш®Ш·ЩҠ ШҜШұ Щ…ЩҲШұШҜ ШұШҜЩҮ вҖҸЩҮШ§ЩҠ Ш№ШҜШҜЩҠШҢ ШЁШ§ ЩҠЩғШҜЩҠЪҜШұ ШӘШұЩғЩҠШЁ Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜ. ЩҒШ№Ш§Щ„ ШіШ§ШІЩҠ вҖҸЩҮШ§ЩҠ ШӘЩҲШ§ШЁШ№ ЩҫШ§ЩҠЩҮ ЩҫЩҠШҙ Ш§ШІ ЩҲШұЩҲШҜ ШЁЩҮ Щ…ШҜЩ„ вҖҸЩҮШ§ЩҠ Ш®Ш·ЩҠШҢ ШЁШ§ Ш¬Щ…Ш№ ШҙШҜЩҶ ШЁШ§ Ш№ШҜШҜ ЩҠЩғШҢ ЩҶШұЩ…Ш§Щ„ЩҠШІЩҮ Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜ. ШҜШұ Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҢ K ШӘШ№ШҜШ§ШҜ Ш®ЩҲШҙЩҮ вҖҸЩҮШ§ШҢ ШЁЩҠШҙШӘШұЩҠЩҶ ШӘШ№ШҜШ§ШҜ ШӘЩғШұШ§ШұЩҮШ§ЩҠ ШұЪҜШұШіЩҠЩҲЩҶ вҖҸЩҮШ§ЩҠ Щ…ЩҶШ·ЩӮЩҠ ШЁШұШ§ЩҠ Щ…ШіШЈЩ„ЩҮ вҖҸЩҮШ§ЩҠ ШұШҜЩҮ вҖҸЩҮШ§ЩҠ ШұШіЩ…ЩҠШҢ ШӯШҜШ§ЩӮЩ„ Ш§ЩҶШӯШұШ§ЩҒ Щ…Ш№ЩҠШ§Шұ Ш®ЩҲШҙЩҮ вҖҸЩҮШ§ШҢ ЩҲ Щ…ЩӮШҜШ§Шұ ШЁЩҠШҙЩҠЩҶЩҮ ШұЪҜШұШіЩҠЩҲЩҶ ШұШ§ ШӘШ№ЩҠЩҠЩҶ ЩҶЩ…ЩҲШҜ. Ш§ЪҜШұ ШұШҜЩҮ вҖҸЩҮШ§ ШұШіЩ…ЩҠ ШЁШ§ШҙШҜШҢ Щ…ЩҠШ§ЩҶЪҜЩҠЩҶ K ШЁЩҮ Ш·ЩҲШұ Ш¬ШҜШ§ЪҜШ§ЩҶЩҮ ШЁЩҮ ЩҮШұ ШұШҜЩҮ Ш§Ш№Щ…Ш§Щ„ Щ…ЩҠвҖҸ ШҙЩҲШҜ ШӘШ§ K Ш®ЩҲШҙЩҮ Щ…ЩҲШұШҜ ЩҶШёШұ ШЁШұШ§ЩҠ ЩҮШұ ШұШҜЩҮ Ш§ШіШӘШ®ШұШ§Ш¬ ЪҜШұШҜШҜ. 4-4. ШұШҜЩҮ ШЁЩҶШҜЩҮШ§ЩҠ Lazy ЩҠШ§ШҜЩҠЪҜШұЩҶШҜЩҮ вҖҸЩҮШ§ЩҠ lazy ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўЩ…ЩҲШІШҙЩҠ ШұШ§ Ш°Ш®ЩҠШұЩҮ Щ…ЩҠвҖҸ ЩғЩҶЩҶШҜ ЩҲ ШӘШ§ ШІЩ…Ш§ЩҶ ШұШҜЩҮ ШЁЩҶШҜЩҠ ЩҮЩҠЪҶ ЩғШ§Шұ ЩҲШ§ЩӮШ№ЩҠ Ш§ЩҶШ¬Ш§Щ… ЩҶЩ…ЩҠвҖҸ ШҜЩҮЩҶШҜ. IB1 ЩҠЩғ ЩҠШ§ШҜЪҜЩҠШұЩҶШҜЩҮ Ш§ШЁШӘШҜШ§ЩҠЩҠ ШЁШұ ЩҫШ§ЩҠЩҮ ЩҶЩ…ЩҲЩҶЩҮ Ш§ШіШӘ ЩғЩҮ ЩҶШІШҜЩҠЩғ ШӘШұЩҠЩҶ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўЩ…ЩҲШІШҙЩҠ ШЁЩҮ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўШІЩ…Ш§ЩҠШҙЩҠ ШҜШ§ШҜЩҮ ШҙШҜЩҮ ШұШ§ Ш§ШІ ЩҶШёШұ ЩҒШ§ШөЩ„ЩҮ Ш§ЩӮЩ„ЩҠШҜШіЩҠ ЩҫЩҠШҜШ§ ЩғШұШҜЩҮ ЩҲ ЩҶШІШҜЩҠЩғШӘШұЩҠЩҶ ШұШҜЩҮ Ш§ЩҠ Щ…ШҙШ§ШЁЩҮ ШұШҜЩҮ ЩҮЩ…Ш§ЩҶ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўЩ…ЩҲШІШҙЩҠ ШұШ§ ШӘШ®Щ…ЩҠЩҶ Щ…ЩҠвҖҸ ШІЩҶШҜ. IBK ЩҠЩғ ШұШҜЩҮ ШЁЩҶШҜ ШЁШ§ K ЩҮЩ…ШіШ§ЩҠЩҮ ЩҶШІШҜЩҠЩғ Ш§ШіШӘ ЩғЩҮ Щ…Ш№ЩҠШ§Шұ ЩҒШ§ШөЩ„ЩҮ Ш°ЩғШұ ШҙШҜЩҮ ШұШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЩҠвҖҸ ЩғЩҶШҜ. ШӘШ№ШҜШ§ШҜ ЩҶШІШҜЩҠЩғШӘШұЩҠЩҶ ЩҒШ§ШөЩ„ЩҮ вҖҸЩҮШ§ (ЩҫЩҠШҙ ЩҒШұШ¶ 1= K ) Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШЁЩҮ Ш·ЩҲШұ ШөШұЩҠШӯ ШҜШұ ЩҲЩҠШұШ§ЩҠШҙЪҜШұ ШҙЩҠШЎ ШӘШ№ЩҠЩҒ ШҙЩҲШҜ. ЩҫЩҠШҙвҖҸШЁЩҠЩҶЩҠ вҖҸЩҮШ§ЩҠ Щ…ШӘШ№Щ„ЩӮ ШЁЩҮ ЩҫЩҠШҙ Ш§ШІ ЩҠЩғ ЩҮЩ…ШіШ§ЩҠЩҮ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШЁШұ Ш§ШіШ§Ші ЩҒШ§ШөЩ„ЩҮ ШўЩҶЩҮШ§ ШӘШ§ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўШІЩ…Ш§ЩҠШҙЩҠШҢ ЩҲШІЩҶ ШҜШ§Шұ ЪҜШұШҜШҜ. ШҜЩҲ ЩҒШұЩ…ЩҲЩ„ Щ…ШӘЩҒШ§ЩҲШӘ ШЁШұШ§ЩҠ ШӘШЁШҜЩҠЩ„ ЩҒШ§ШөЩ„ЩҮ ШЁЩҮ ЩҲШІЩҶШҢ ЩҫЩҠШ§ШҜЩҮ ШіШ§ШІЩҠ ШҙШҜЩҮ Ш§ЩҶШҜ. ШӘШ№ШҜШ§ШҜ ЩҶЩ…ЩҲЩҶЩҮ ЩҮШ§ЩҠ ШўЩ…ЩҲШІШҙЩҠ ЩғЩҮ ШЁЩҮ ЩҲШіЩҠЩ„ЩҮ ШұШҜЩҮ ШЁЩҶШҜ ЩҶЪҜЩҮШҜШ§ШұЩҠ Щ…ЩҠвҖҸ ШҙЩҲШҜШҢ Щ…ЩҠвҖҸ ШӘЩҲШ§ЩҶШҜ ШЁШ§ ШӘЩҶШёЩҠЩ… ЪҜШІЩҠЩҶЩҮ Ш§ЩҶШҜШ§ШІЩҮ ЩҫЩҶШ¬ШұЩҮ Щ…ШӯШҜЩҲШҜ ЪҜШұШҜШҜ. ШІЩ…Ш§ЩҶЩҠ ЩғЩҮ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ Ш¬ШҜЩҠШҜ Ш§Ш¶Ш§ЩҒЩҮ Щ…ЩҠвҖҸ ШҙЩҲЩҶШҜШҢ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ЩӮШҜЩҠЩ…ЩҠ ШӯШ°ЩҒ ШҙШҜЩҮ ШӘШ§ ШӘШ№ШҜШ§ШҜ ЩғЩ„ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ШўЩ…ЩҲШІШҙЩҠ ШҜШұ Ш§ЩҶШҜШ§ШІЩҮ ШӘШ№ЩҠЩҠЩҶ ШҙШҜЩҮ ШЁШ§ЩӮЩҠ ШЁЩ…Ш§ЩҶШҜ. Kstar ШҢ ЩҠЩғ ШұЩҲШҙ ЩҶШІШҜЩҠЩғШӘШұЩҠЩҶ ЩҮЩ…ШіШ§ЩҠЩҮ Ш§ШіШӘ ЩғЩҮ Ш§ШІ ШӘШ§ШЁШ№ ЩҒШ§ШөЩ„ЩҮ Ш§ЩҠ Ш№Щ…ЩҲЩ…ЩҠ ШҙШҜЩҮ ШЁШұ Ш§ШіШ§Ші ШӘШЁШҜЩҠЩ„Ш§ШӘ Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЩҠвҖҸ ЩғЩҶШҜ. LWL ЩҠЩғ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… ЩғЩ„ЩҠ ШЁШұШ§ЩҠ ЩҠШ§ШҜЪҜЩҠШұЩҠ ЩҲШІЩҶ ШҜШ§Шұ ШҙШҜЩҮ ШЁЩҮ ШөЩҲШұШӘ Щ…ШӯЩ„ЩҠ Ш§ШіШӘ. Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ… ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ЩҠЩғ ШұЩҲШҙ ШЁШұ ЩҫШ§ЩҠЩҮ ЩҶЩ…ЩҲЩҶЩҮШҢ ЩҲШІЩҶ вҖҸЩҮШ§ ШұШ§ ЩҶШіШЁШӘ Щ…ЩҠвҖҸ ШҜЩҮШҜ ЩҲ Ш§ШІ ШұЩҲЩҠ ЩҶЩ…ЩҲЩҶЩҮ вҖҸЩҮШ§ЩҠ ЩҲШІЩҶ ШҜШ§Шұ ШҙШҜЩҮШҢ ШұШҜЩҮ ШЁЩҶШҜ ШұШ§ Щ…ЩҠвҖҸ ШіШ§ШІШҜ. ШұШҜЩҮ ШЁЩҶШҜ ШҜШұ ЩҲЩҠШұШ§ЩҠШҙЪҜШұ ШҙЩҠШЎ LWL Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҠвҖҸ ШҙЩҲШҜ. Nave Bayes ШЁШұШ§ЩҠ Щ…ШіШ§ЩҠЩ„ ШұШҜЩҮ ШЁЩҶШҜЩҠ ЩҲ ШұЪҜШұШіЩҠЩҲЩҶ Ш®Ш·ЩҠ ШЁШұШ§ЩҠ Щ…ШіШ§ЩҠЩ„ ШұЪҜШұШіЩҠЩҲЩҶШҢ Ш§ЩҶШӘШ®Ш§ШЁ вҖҸЩҮШ§ЩҠ Ш®ЩҲШЁЩҠ ЩҮШіШӘЩҶШҜ. Щ…ЩҠвҖҸВӯШӘЩҲШ§ЩҶ ШҜШұ Ш§ЩҠЩҶ Ш§Щ„ЪҜЩҲШұЩҠШӘЩ…ШҢ ШӘШ№ШҜШ§ШҜ ЩҮЩ…ШіШ§ЩҠЩҮ вҖҸЩҮШ§ЩҠ Щ…ЩҲШұШҜ Ш§ШіШӘЩҒШ§ШҜЩҮ ШұШ§ ЩғЩҮ ЩҫЩҮЩҶШ§ЩҠ ШЁШ§ЩҶШҜ ЩҮШіШӘЩҮ ЩҲ ШҙЩғЩ„ ЩҮШіШӘЩҮ Щ…ЩҲШұШҜ Ш§ШіШӘЩҒШ§ШҜЩҮ ШЁШұШ§ЩҠ ЩҲШІЩҶ ШҜШ§Шұ ЩғШұШҜЩҶ ШұШ§ (Ш®Ш·ЩҠШҢ Щ…Ш№ЩғЩҲШіШҢ ЩҠШ§ ЪҜЩҲШіЩҠ) Щ…ШҙШ®Шө Щ…ЩҠвҖҸ ЩғЩҶШҜШҢ ШӘШ№ЩҠЩҠЩҶ ЩҶЩ…ЩҲШҜ. ЩҶШұЩ…Ш§Щ„ ШіШ§ШІЩҠ ЩҲЩҠЪҳЪҜЩҠвҖҸвҖҸЩҮШ§ ШЁЩҮ Ш·ЩҲШұ ЩҫЩҠШҙ ЩҒШұШ¶ ЩҒШ№Ш§Щ„ Ш§ШіШӘ[ Data Mining, witten et Al. 2005 ]. [1] Visualization [2] Preprocessing [3] User friendly [4] Platform [5] Workbench [6] T ool kit [7] GNU General Public License [8] Personal Digital Assistant [9] Postprocessing [10] D iscretization [11] Relational [12] Interactive interface [13] Menu [14] Related attribute [15] Box [16] Command-line [17] Installer [18] Download [19] Panel [20] Tab [21] Tasks [22] Modify [23] Train [24] Aspect [25] Background task [26] Item [27] File format converter [28] Spreadsheet [29] Generic [30] Documentation [31] Serialized instances [32] Reloading [33] Native Java format [34] Parse [35] Source [36] Entry [37] R educed-error pruning [38] Not allowed [39] Greedily [40] Backward elimination [41] Median [42] Mean [43] K-means [44] Hidden layer |
|
|
|
|
Ы°Ыҙ-ЫұЫё-ЫұЫіЫёЫ№, ЫұЫұ:ЫұЫІ ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#4 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Ш№Ш¶ЩҲ Ш¬ШҜЫҢШҜ
 
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ШЁЩҮЩ…ЩҶ ЫұЫіЫёЫё
ЩҫШіШӘ ЩҮШ§: 1
ШӘШҙЩғШұЩҮШ§: 0
0 ШӘШҙЩғШұ ШҜШұ 0 ЩҫШіШӘ
|
ШЁШ§ Ш№ШұШ¶ ШіЩ„Ш§Щ… ЩҲ Ш®ШіШӘЩҮ ЩҶШЁШ§ШҙЫҢШҜ Ш®ШҜЩ…ШӘ Щ…ШҜЫҢШұ Ъ©Щ„ Щ…ШӯШӘШұЩ… ШіШ§ЫҢШӘ ЩҲ ШӘШҙЪ©Шұ Ш§ШІ ШІШӯЩ…Ш§ШӘШҙЩҲЩҶ
Щ…ЩҶ ШЁЩҮ ШҙШҜШӘ Ш§ШӯШӘЫҢШ§Ш¬ ШЁЩҮ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ spss clementine ШҜШ§ШұЩ… ЩҲЩ„ЫҢ Щ…ШӘШ§ШіЩҒШ§ЩҶЩҮ ЩҮЫҢЪҶ Ш¬Ш§ Щ„ЫҢЩҶЪ©ЫҢ ШЁШұШ§ЫҢ ШҜШ§ЩҶЩ„ЩҲШҜШҙ ШұЩҲ ЩҫЫҢШҜШ§ ЩҶЪ©ШұШҜЩ… ! ШҜШұШ®ЩҲШ§ШіШӘ Ъ©Щ…Ъ© ШҜШ§ШұЩ… Ш§ШІШӘЩҲЩҶ . Ш§ЫҢЩҶ ЩҮЩ… ШўШҜШұШі Ш§ЫҢЩ…ЫҢЩ„ Щ…ЩҶЩҮ : kayarsalan@gmail.com ШЁШ§ ШӘШҙЪ©Шұ ЩҒШұШ§ЩҲШ§ЩҶ |
|
|
|
|
Ы°Ыҙ-ЫІЫө-ЫұЫіЫёЫ№, ЫұЫұ:ЫөЫө ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#5 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Ш№Ш¶ЩҲ ЩҒШ№Ш§Щ„
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ШўШЁШ§ЩҶ ЫұЫіЫёЫё
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: Щ…ШҙЩҮШҜ
ЩҫШіШӘ ЩҮШ§: 18
ШӘШҙЩғШұЩҮШ§: 14
71 ШӘШҙЩғШұ ШҜШұ 8 ЩҫШіШӘ
My Mood:

|
ШҜЩҲШіШӘ Ш№ШІЫҢШІ ШіЩ„Ш§Щ…
Ш§Щ…ЫҢШҜЩҲШ§ШұЩ… Ш§ЫҢЩҶ ШЁШӘЩҲЩҶЩҮ Ъ©Щ…Ъ©ШӘ Ъ©ЩҶЩҮ ШӘШіШӘШҙ Ъ©ШұШҜЩ… ШҜШұШіШӘ ШЁЩҲШҜ http://lfiles3.brothersoft.com/busin...7_win_en-1.exe |
|
|
|
|
Ы°Ыё-ЫұЫҙ-ЫұЫіЫёЫ№, Ы°Ы·:ЫөЫІ ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#6 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Ш№Ш¶ЩҲ Ш¬ШҜЫҢШҜ
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Щ…ЩҮШұ ЫұЫіЫёЫ№
ЩҫШіШӘ ЩҮШ§: 1
ШӘШҙЩғШұЩҮШ§: 0
0 ШӘШҙЩғШұ ШҜШұ 0 ЩҫШіШӘ
My Mood:

|
ШЁШ§ ШіЩ„Ш§Щ… ЩҲШ®ШіШӘЩҮ ЩҶШЁШ§ШҙЫҢШҜ
Щ…ЩҶ ЫҢЪ© Ъ©ШӘШ§ШЁ ШўЩ…ЩҲШІШҙ Ш¬Ш§Щ…Ш№ ШҜШұЩ…ЩҲШұШҜ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ (ЩҮШ§ЫҢ) ШҜШ§ШҜЩҮ Ъ©Ш§ЩҲЫҢ Щ…ЫҢ Ш®ЩҲШ§ШіШӘЩ… ШҢШәЫҢШұ Ш§ШІ Ш§ЩҲЩҶЫҢ Ъ©ЩҮ ШҜШұ Щ…ЩҲШұШҜ weka ЩҶЩҲШҙШӘЩҮ ШҙШҜЩҮ. Ш®ЫҢЩ„ЫҢ Щ…Щ…ЩҶЩҲЩҶ |
|
|
|

|
Ы°Ы№-Ы·-ЫұЫіЫёЫ№, Ы°Ы№:ЫұЫ¶ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#7 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) | |
|
Ш№Ш¶ЩҲ Ш¬ШҜЫҢШҜ
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ШҙЩҮШұЩҠЩҲШұ ЫұЫіЫёЫ№
ЩҫШіШӘ ЩҮШ§: 5
ШӘШҙЩғШұЩҮШ§: 4
2 ШӘШҙЩғШұ ШҜШұ 2 ЩҫШіШӘ
|
ЩҶЩӮЩ„ ЩӮЩҲЩ„:
|
|
|
|
|

| Ш§ШІ iutai ШӘШҙЩғШұ ЩғШұШҜЩҮ Ш§ШіШӘ: | ma.nejati (ЫұЫІ-Ыө-ЫұЫіЫёЫ№) |
|
Ы°Ы№-Ы№-ЫұЫіЫёЫ№, ЫұЫІ:ЫөЫө ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#8 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Ш№Ш¶ЩҲ ЩҒЩҲЩӮ ЩҒШ№Ш§Щ„
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ШҙЩҮШұЩҠЩҲШұ ЫұЫіЫёЫ№
ЩҫШіШӘ ЩҮШ§: 27
ШӘШҙЩғШұЩҮШ§: 7
22 ШӘШҙЩғШұ ШҜШұ 7 ЩҫШіШӘ
|
ШЁШ§ ШіЩ„Ш§Щ…
ШҜШұ ЩӮШіЩ…ШӘ Ш§Ъ©ШӘШҙШ§ЩҒ ЪҜЩҒШӘЫҢШҜ ШҜШұ ЩҶШұЩ…вҖҢШ§ЩҒШІШ§ШұЩҮШ§ЩҠ ШҜШ§ШҜЩҮвҖҢЩғШ§ЩҲЩҠ Щ…ШЁШӘЩҶЩҠ ШЁШұ Щ…ШҜЩ„вҖҢЩҮШ§ЩҠ ЩҫЩҠШҙЪҜЩҲЩҠЩҠШҢ Ш§Щ„ЪҜЩҲЩҮШ§ЩҠЩҠ ЩғЩҮ Ш§ШІ ЩҠЩғ ШЁШ§ЩҶЩғ ШҜШ§ШҜЩҮ ЩғШҙЩҒ Щ…ЩҠвҖҢШҙЩҲЩҶШҜШҢ ШЁШұШ§ЩҠ ЩҫЩҠШҙвҖҢШЁЩҠЩҶЩҠ ШўЩҠЩҶШҜЩҮ ШЁЩҮ ЩғШ§Шұ Щ…ЩҠвҖҢШұЩҲЩҶШҜ. ЫҢШ№ЩҶЫҢ ШҜШұ ШӘШҙШ®ЫҢШө ШЁЫҢЩ…Ш§ШұЫҢ ЩҮШ§ ЩҶЫҢШІ Щ…ЫҢШӘЩҲШ§ЩҶ Ш§ШІ ШўЩҶ Ш§ШіШӘЩҒШ§ШҜЩҮ Ъ©ШұШҜ. Щ…Щ…Ъ©ЩҶ Ш§ШіШӘ ШҜШұ Ш§ЫҢЩҶ ШІЩ…ЫҢЩҶЩҮ Щ…Ш«Ш§Щ„ ЫҢШ§ Щ…ЩӮШ§Щ„ЩҮ Ш§ЫҢ ШЁЪҜШ°Ш§ШұЫҢШҜШҹ ШЁШ§ ШӘШҙЪ©Шұ |
|
|
|
|
ЫұЫұ-ЫұЫұ-ЫұЫіЫёЫ№, Ы°Ыі:ЫұЫө ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#9 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) | |
|
Moderator

ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ШЁЩҮЩ…ЩҶ ЫұЫіЫёЫ№
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ
ЩҫШіШӘ ЩҮШ§: 88
ШӘШҙЩғШұЩҮШ§: 41
93 ШӘШҙЩғШұ ШҜШұ 42 ЩҫШіШӘ
|
ЩҶЩӮЩ„ ЩӮЩҲЩ„:
|
|
|
|
|
|
ЫұЫұ-ЫұЫұ-ЫұЫіЫёЫ№, Ы°Ыі:ЫұЫ№ ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ
|
#10 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) | |
|
Moderator
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ШЁЩҮЩ…ЩҶ ЫұЫіЫёЫ№
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ
ЩҫШіШӘ ЩҮШ§: 88
ШӘШҙЩғШұЩҮШ§: 41
93 ШӘШҙЩғШұ ШҜШұ 42 ЩҫШіШӘ
|
ЩҶЩӮЩ„ ЩӮЩҲЩ„:
ШӘЩҲ Ъ©Щ„ Щ…ЩӮШ§Щ„Ш§ШӘ Ъ©ЩҮ ЩҶЩ…Ш§ЫҢЩҮ isi ШҜШ§ШұЩҶШҜ ЩҒЩӮШ· 2 Щ…ЩӮШ§Щ„ЩҮ ШҜШұ Ш§ЫҢЩҶ ШІЩ…ЫҢЩҶЩҮ ЩҲШ¬ЩҲШҜ ШҜШ§ШұЩҮ:ШҜЫҢ ШЁШ§ЩҲШұ ЩҶЪ©ШұШҜЩҶЫҢЩҮ ЩҶЩҮШҹ Ш§ЪҜЩҮ Ш§ЩҶЪҜЩ„ЫҢШіЫҢШҙ ШұЩҲ Щ…ЫҢ Ш®ЩҲШ§ЩҮЫҢШҜ Щ…ЫҢ ШӘЩҲЩҶЩ… ШЁШұШ§ШӘЩҲЩҶ ШЁШІШ§ШұЩ…:ШҜЫҢ Ш§Щ…Ш§ ЩҒШ§ШұШіЫҢ ЪҶЫҢШІЫҢ ЩҶШҜШ§ШұЩ… Ш¬ШІ ЫҢЩҮ Ъ©ШӘШ§ШЁ ШӘШұШ¬Щ…ЩҮ ШҙШҜЩҮ Ш§ЩҒШӘШ¶Ш§Шӯ Ъ©ЩҮ ШҜШұ ШӯЩӮЫҢЩӮШӘ ШўЩ…ЩҲШІШҙ ЩҶШұЩ… Ш§ЩҒШІШ§Шұ spss ЩҲ Ъ©Ш§ШұШЁШұШҜ ШҙШЁЪ©ЩҮ Ш№ШөШЁЫҢ ШҜШұ ЩҫЫҢШҙ ШЁЫҢЩҶЫҢ ЩҮШІЫҢЩҶЩҮ ЩҮШ§ЫҢ ШҜШұЩ…Ш§ЩҶ ЩҮШіШӘШҙ. |
|
|
|
|
|
| ЩғШ§ШұШЁШұШ§ЩҶ ШҜШұ ШӯШ§Щ„ ШҜЩҠШҜЩҶ ШӘШ§ЩҫЩҠЪ©: 1 (0 Ш№Ш¶ЩҲ ЩҲ 1 Щ…ЩҮЩ…Ш§ЩҶ) | |
 Linear Mode
Linear Mode

|
|

ШІЩ…Ш§ЩҶ Щ…ШӯЩ„ЩҠ ШҙЩ…Ш§ ШЁШ§ ШӘЩҶШёЩҠЩ… GMT +3.5 ЩҮЩ… Ш§Ъ©ЩҶЩҲЩҶ Ы°Ыё:ЫІЫ¶ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ Щ…ЩҠШЁШ§ШҙШҜ.





