انجمن را در گوگل محبوب کنيد :
|
|||||||


| تبليغات سايت | |||||||||||||||||||||||||||||||||||||||||||||
  |
|
|
LinkBack | ابزارهاي تاپيک | نحوه نمايش |
 ۰۱-۱۷-۱۳۸۹, ۰۸:۲۱ بعد از ظهر
۰۱-۱۷-۱۳۸۹, ۰۸:۲۱ بعد از ظهر
|
#1 (لینک دائم) |
|
Administrator
 
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:

 |
تشخیص کاراکتر با استفاده از شبکه عصبی lvq
مقدمه شبیه سازی فعالیت های انسان توسط ماشین ها یکی از زمینه های تحقیقاتی از زمان اختراع کامپیوترهای دیجیتال بوده است . در برخی زمینه ها که نوع خاصی از هوشمندی را نیاز داشته ؛ مانند بازی شطرنج ؛ پیشرفت های خوبی صورت گرفته است اما در مسائلی مانند بینایی ماشین حتی قدرتمندترین کامپیوترها نیز به راحتی از انسان شکست می خورند . شبیه سازی خواندن انسان نیز یکی از بخشهای جذابی است که طی سه دهه گذشته موضوع تحقیقات بسیاری از دانشمندان بوده و هنوز تا تکامل آن راه بسیاری در پیش است . شبیه سازی خواندن و تشخیص متن توسط ماشین به 2 گروه کلی تقسیم می شود : 1. جمع آوری اطلاعات برای تشخیص : الف. Offline : شامل تصاویری است که از نوشته ها تهیه می شود . مانند عکس توسط دوربین دیجیتالی ، اسکن نامه ها و صفحه های کتاب و از این دست تصاویر . ب. Online : در این مدل تشخیص متن ، همزمان با نوشتن آن ، متن ِ نوشته شده تشخیص داده شده و تبدیل به کاراکترهای آن می شود . مانند تشخیص دست خط در handled ها و یا در TabletPC ها . 2. نوع متن الف. دست نویس ب. متن تایپ شده که توسط ماشین چاپ شده است ، مانند کتابها ، مجلات و ... عملیات تشخیص متن عموما ً شامل مراحل زیر است : 1. پیش پردازش : شامل روش های مختلف پردازش تصویر است که تصویری بدون نویز و مناسب برای قطعه بندی را آماده می کند . 2. قطعه بندی : مهمترین و مشکلترین کاری که برای تشخیص متن باید انجام شود قطعه بندی تصویر به قطعاتی است که توسط قسمت تشخیص متن باید به کاراکتر یا کلمه تفسیر شود . قطعه بندی اشتباه تصویر منجر به تفسیری اشتباه از کاراکتر نقاشی شده در آن می شود . انواع قطعه بندی به شرح زیر است : الف. External Segmentation : هدف در این نوع قطعه بندی جدا کردن اجزای کلی متن مانند پاراگراف و سطرها می باشد . امکان برچسب زنی بر روی اجزای صفحه ، مانند عنوان یا چکیده نیز در این نوع قطعه بندی می تواند وجود داشته باشد . ب. Internal Segmentation : برای جدا کردن کاراکترها از یکدیگر استفاده می شود . یک. Implicit segmentation : تشخیص کاراکترها با توجه به معانی که از قطعات جدا شده قابل تفسیر است صورت می گیرد . دو. Explicit Segmentation : جدا کردن کاراکترها با توجه مشخصه هایی که برای آنها قابل تصور است . مثلا ً horizontal projection که از روی قله ها یا دره ها در هیستوگرام افقی یا عمودی سطر، کلمه یا حرف را پیدا می کند . 3. آموزش و تشخیص کاراکترها : بعد از قطعه بندی ، تصویر قطعه قطعه شده می بایست توسط الگوریتمی به متن تفسیر شود . روشهای مختلفی برای این کار وجود دارد که هر کدام از آنها را می توان با دو دیدگاه اجرایی کرد. در دیدگاه اول قطعات تصویر حاوی "کلمه" های متن اصلی هستند و الگوریتم باید کلمه ها را تشخیص دهد . در این دیدگاه دایره لغات کم خواهد بود ولی مشکل قطعه قطعه کردن تصویر کمتر است . برای تفسیر دست خط با توجه به تعدد روش نوشتن یک کلمه ، نرخ تفسیر کمتری از متن تایپی دارد . روش دوم روشهای analytic است که از پایین به بالا عمل کرده و سعی می کند کاراکترها را شناسایی کرده و با ترکیب آنها لغت ها را بسازد . در عمل از ترکیب روشهای زیر استفاده می شود : الف. Template Matching : تعدادی template از کاراکترها یا کلمات از قبل حاضر شده است . عکسهای قطعه قطعه شده با این template ها مقایسه می شود و با توجه به شباهت برنده انتخاب می شود . ب. روشهای آماری : با استفاده از برخی مشخصه های آماری و توابع تصمیم گیری آماری کار تشخیص نوع هر کدام از تصاویر قطعه قطعه شده را انجام می دهد . روشهای non-paramteric ، parametric ، cluster analysis و hidden markov modeling از انواع این روش است . پ. روشهای ساختاری : با توجه به تعدادی الگوی پایه که از قبل تعریف شده است و میزان استفاده هر کدام از تصاویر از این الگوهای پایه عملیات تشخیص انجام می شود . Grammatical methods و graphical methods از انواع این روشها می باشد . ت. شبکه های عصبی : با توجه به خاصیت شبکه های عصبی که قابلیت تطبیق پذیری با اطلاعات جدید و مختلف را در حد بالایی دارند ، از آنها برای تشخیص استفاده می شود . 4. پس پردازش : بعد از بدست آوردن متن از تصویر می توان آنها را با توجه به اطلاعاتی که درباره آن عکس داریم تصحیح کرد. مثلا ً با توجه به موضوع متن ، لغت هایی که احتمالا ً اشتباهی جزو متن تشخیص داده شده را حذف یا تصحیح کرد . استفاده از لغت نامه نیز یکی از ابزارهایی است که در این مرحله قابل استفاده می باشد . در ادامه خلاصه ای از تئوری شبکه عصبی LVQ و مباحث مربوطه به قطعه بندی شامل بهبود تصویر و روش projection افقی و عمودی شرح داده شده است . پس از آن روش پیاده سازی و نمونه اجرایی در حالت تک کاراکتر و تصویر اسکن شده آمده است . شبکه عصبی LVQ Learning Vector Quantization یا LVQ یک روش کلاس بندی الگو است که هر کدام از خروجی ها نمایش دهنده یک کلاس می باشند و هر کدام توسط بردار وزن آن کلاس مشخص می شود . بردار وزن هر کدام از کلاسها توسط یکی مجموعه های آموزشی مقدار دهی اولیه شده و سپس توسط الگوریتم های یادگیری (با نظارت) بهینه می شود. بعد از یادگیری ، شبکه LVQ ورودی را به کلاسی که برداری با نزدیک ترین فاصله به آن باشد ، نسبت می دهد . ساختار شبکه های LVQمانند شکل زیر است : 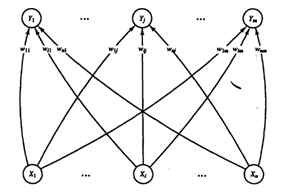 مولفه های بردار ورودی در x_i ها قرار می گیرد و y_i ها کلاسهای خروجی است . بردار وزن های کدام از کلاسهای خروجی ارتباط بین مولفه های ورودی و خروجی را برقرار می کند . الگوریتم یادگیری در LVQ به شکلی است که می خواهیم در صورت هم کلاس بودن ورودی و کلاس تشخیص داده شده ، وزنهای بردار مشخصه را به سمت ورودی نزدیک کنیم و اگر هم کلاس نبودند آنها را از هم دور کنیم . در الگوریتم یادگیری LVQ از عبارتهای زیر استفاده شده است : X بردار ورودی T کلاس صحیح برای بردار آموزشی 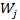 بردار وزن برای J امین کلاس بردار وزن برای J امین کلاس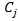 کلاس برای J امین واحد خروجی کلاس برای J امین واحد خروجی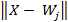 فاصله اقلیدسی بین بردار ورودی و J امین خروجی فاصله اقلیدسی بین بردار ورودی و J امین خروجیالگوریتم : مرحله اول : بردار وزن اولیه و مقدار نرخ یادگیری انتخاب شود . مرحله دوم : تا زمانی که شرط خروج مثبت نشده باشد مراحل 2 تا 6 را انجام دهد . مرحله سوم : J را به نحوی انتخاب کند که حداقل باشد .مرحله چهارم : را به شکل زیر بروز رسانی کند 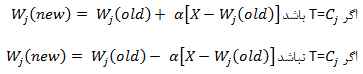 مرحله پنجم : نرخ یاد گیری را کاهش دهد . مرحله ششم : شرط خروجی را کنترل کند ( می تواند تعداد چرخش یا رسیدن نرخ یادگیری به یک حداقلی باشد ). شبکه عصبی LVQ مشتقات مختلفی دارد . LVQ2 ، LVQ2.1 و LVQ3 سه مشتق از الگوریتم اولیه هستند که در آنها به غیر از کلاس برنده ، کلاس دوم نیز آموزش می بیند . در این سه ، با توجه به فاصله کلاس اول و دوم و هم کلاس بودن با بردار ورودی نوع آموزش متفاوت است . |

|

|


| از Astaraki تشكر كرده است: | mehdinajafinia (۰۲-۳-۱۳۹۰) |
| #ADS | |
|
نشان دهنده تبلیغات
تبليغگر
تاريخ عضويت: -
محل سكونت: -
سن: 2010
پست ها: -
|
|

|
|
۰۱-۱۷-۱۳۸۹, ۰۸:۲۵ بعد از ظهر
|
#2 (لینک دائم) |
|
Administrator
تاريخ عضويت: خرداد ۱۳۸۷
محل سكونت: تهران-کرج!
پست ها: 3,465
تشكرها: 754
16,339 تشكر در 3,127 پست
My Mood:
|
بهبود تصاویر
در این پروژه از روشهای مختلفی برای بهبود تصاویر استفاده شده است . Adaptive Median ****** ***** میانه یکی از روشهای آماری است که در پردازش تصاویر برای کم کردن نویز استفاده می شود . در این ***** پنجره ای با اندازه مشخص روی پیکسل ها حرکت داده می شود . هر بار اندازه شدت نور پیکسلهای درون پنجره مرتب شده و مقدار میانه آن برای پیکسل وسط پنجره انتخاب می شود . این ***** باعث کم شدن وضوح تصویر و در نتیجه خرابی لبه ها می شود . برای تشخیص کاراکترها در یک تصویر ، کیفیت لبه های کاراکترها خیلی مهم است . ***** دیگری که با استفاده از روش میانه کار می کند Adaptive median است . این ***** با توجه به شدت نورهای مختلف درون پنجره ، شدت نور خروجی را انتخاب می کند . این انتخاب در بین میانه ، حداکثر و حداقل شدت نورهای درون پنجره و شدت نور پیکسل مورد نظر( مرکز پنجره) انجام می شود . در این ***** لبه ها بهتر از ***** معمولی باقی می ماند . Spatial Smoothing یکی از روشهای حذف نویز میانگین گیری از شدت نورهای درون پنجره است . هر چه پنجره بزرگتری استفاده شود میزان بلور شدن بیشتر شده و نویزهای بیشتری حذف می شود . البته این روش لبه ها را تخریب می کند . Thresholding قطعه بندی کردن تصویری که دودویی شده است عملیات آسان تری نسبت به قطعه بندی عکس با چند رنگ می باشد . از دودویی کردن تصاویر برای جدا کردن زمینه از قسمت بیرونی تصویر یا جدا کردن بخش مورد نظر در تصویر نیز می توان استفاده کرد . در دودویی کردن تصویر ، مقدار شدت نور پیکسلهایی که شدت نور آن از عدد N کمتر باشد ، 0 و در غیر این صورت 255 انتخاب می شود . پیدا کردن مقدار N به شکل خودکار یکی از مسائلی است که روشهای مختلفی برای آن پیشنهاد شده . در این پروژه از روش Otsu استفاده شده است . در روش Otsu فرض بر این است که تصویر از دو بخش کلی زمینه و foreground تشکیل شده باشد . با استفاده از عملیات آماری بر روی هیستوگرام تصویر ، بهترین شدت نوری که بتواند دو بخش را از هم جدا کند پیشنهاد می شود . Projection افقی و عمودی یکی از ساده ترین روشهای قطعه بندی تصاویر به بخشهای تشکیل دهنده آن استفاده از projection افقی یا عمودی است . در روش افقی ، تعداد پیکسلهایی در هر سطر که شدت نور آن برابر مقدار معینی باشد مشخص می شود . در روش عمودی ، تعداد پیکسلهایی در هر ستون که شدت نور آن برابر مقدار معینی باشد مشخص می شود .  همانطور که در شکل 2 مشخص است با استفاده از روش افقی و بررسی محلهای حداقل شدن تعداد پیکسل ها می توان مکان سطرهای متن را پیدا کرد . اگر سطرها دارای زاویه باشند یا در تصویر نویز وجود داشته باشد نمودار projection دارای خطا خواهد بود که عملا ً استفاده از این روش را محدود به تصاویر با کیفیت بالا و سطرهای کاملا ً افقی می کند . حذف نقاط تنها نقطه هایی که بعد از استفاده از ***** و دودویی کردن تصویر باقی می ماند می تواند عملیات projection را با خطای زیادی روبرو کند . برای حذف این نقاط پنجره ایی روی تصویر حرکت داده می شود و اگر الگوهایی به شکل ماتریس های زیر دیده شود پیکسل مرکزی آن تغییر رنگ داده می شود . 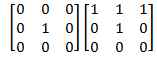 پیاده سازی و اجرا روال کلی اجرای نرم افزار به این شرح است که ، ابتدا مجموعه ای از تصاویر حروف بزرگ انگلیسی به عنوان وزن اولیه و مجموعه دیگری که شامل تصاویر حروف الفبای بزرگ انگلیسی در فونت های دیگری است به نرم افزار داده می شود . پس از یادگیری وزنها می توان پنجره تشخیص تک کاراکتر یا تشخیص محتویات یک عکس اسکن شده را اجرا کرد . تصاویر حروف بزرگ الفبای انگلیسی بدین شرح تهیه شده اند . حروف در نرم افزار Word نوشته شده ، از روی صفحه عکس گرفته شده ( print screen) و با استفاده از نرم افزار Paint حروف مانند تصویر زیر انتخاب شدند و در یک فایل با فرمت PNG ذخیره شد .  تصویر بالا به عنوان ورودی به نرم افزاری که در VB.NET نوشته شده و بوسیله روش projection کاراکترهای را از هم جدا می کند داده شده و خروجی آن تصاویر تک تک کاراکترها می باشد . در شکل زیر تعدادی از تصاویر قطعه قطعه شده از شکل 4 را مشاهده می کنید .  یک مجموعه برای وزنهای اولیه و ده مجموعه برای یادگیری با همین روش تهیه شده است . اندازه تصاویر عرض 10 و ارتفاع 13 پیکسل در نظر گرفته شده . شبکه LVQ ی که برای این مساله در نظر گرفته شده ماتریسی با ابعاد 130 در 26 است . 26 کلاس برای حروف الفبا و 130 وزن برای هر کدام از کلاس ها . پیکسلهای سفید ارزش 1- و پیکسلهای سیاه ارزش 1 را دارند . در قسمت پردازش تصویر اسکن شده ، ابتدا تصویر به سیاه و سفید تبدیل شده ، سپس با یکی از روشهای انتخابی ***** می شود . بعد از ***** شدن ، شدت نور مناسب برای thresholding محاسبه شده و عملیات دودویی کردن تصویر انجام می شود . در آخر نیز "نقاط تنها" در تصویر حذف می شوند . آزمایش یک کاراکتر در ادامه چند تصویر از عملکرد تشخیص را مشاهده می کنید :  آزمایش تصویر اسکن شده شکل زیر قبل و بعد از عملیات بهبود تصویر را نشان می دهد . 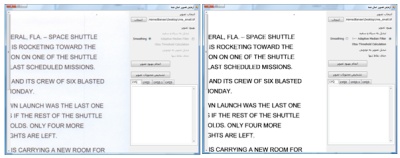 بعد از به اتمام رسیدن کار ، متن نهایی در جعبه متن های سمت راست پنجره برای هر کدام از شبکه های LVQ نمایش داده می شود . همچنین نحوه قطعه بندی کردن تصویر نیز در سمت چپ مشخص می شود . 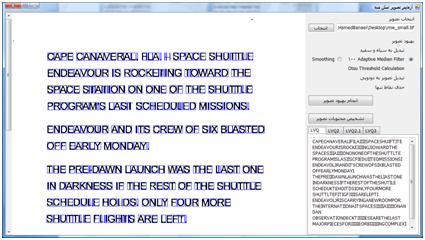 شکل های زیر همان متن اسکن شده است ولی از برگه چاپ شده آن بوسیله دوربین دیجیتال عکس گرفته شده . همان طور که مشاهده می شود انحنایی که دوربین در تصویر ایجاد می کند میزان قطعه بندی با استفاده از projection را به شدت با خطا روبرو می کند . در تابع OCR ، فرض بر این است که قطعه بندی به شکلی باشد که یک حرف تمام یک قطعه را بگیرد . اما در سطرهای پایین به علت زاویه دار بودن سطر ، کاراکتر بالا یا پایین قطعه قرار گرفته و باعث شده است که OCR تفسیر اشتباهی از تصویر قطعه قطعه شده داشته باشد . 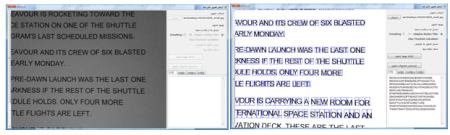 شکل زیر screen shot از پنجره Word است که تمامی حروف الفبای بزرگ انگلیسی در آن با فونت Arial و Calibri نوشته شده است . برای حذف نویز (screen shot نویز ندارد !) از smoothing معمولی استفاده شده است . همانطور که قابل مشاهده است قطعه بندی به شکل صحیحی صورت گرفته و حروف به درستی تشخیص داده شده اند . تصاویر به فرمت png هستند . 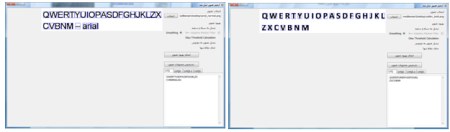 تصویر زیر عکسی است که با دوربین تلفن همراه از یک برگ کاغذ که با خودکار مشکی روی آن نوشته شده است تهیه شده . قطعه بندی و تشخیص دست خط پیچیده تر از روش پیاده سازی شده در این پروژه است . تعداد بسیار کمی از حروف در این شکل تشخیص داده شده اند . 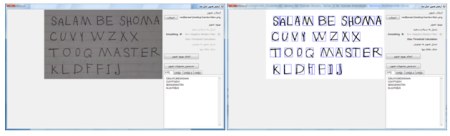 منابع Fundamentals of neural networks , Laurence Fausett
Digital Image Processing , Gonzalez An Overview Of Character Recognition Focused On Off-line Handwriting Nafiz Arica, Student Member, IEEE and Fatos T. Yarman-Vural, Senior Member, IEEE Wikipedia Retrieval of Machine-printed Latin Documents through Word Shape Coding Shijian Lu, Chew Lim Tan |
|
|
|
|
۰۵-۹-۱۳۸۹, ۰۹:۱۷ قبل از ظهر
|
#3 (لینک دائم) |
|
عضو جدید
 
تاريخ عضويت: مهر ۱۳۸۸
پست ها: 1
تشكرها: 0
1 تشكر در 1 پست
|
بهتر است هنگام کپی کردن منبع رو هم ذکر کنید ! حامد بنايی - تشخیص کاراکتر با استفاده از شبکه عصبی LVQ
|
|
|
|
| از banaei تشكر كرده است: | Astaraki (۰۵-۹-۱۳۸۹) |
|
«
یک الگوریتم جدید بهینه سازی مبتنی بر کلونینگ سیستم ایمنی مصنوعی و اعمال آن روی مسئله
|
استفاده از شبكه بيزين براي پيش بيني رفتار فراگير در آموزش الكترونيك
»
| كاربران در حال ديدن تاپيک: 1 (0 عضو و 1 مهمان) | |
 Linear Mode
Linear Mode

|
|

زمان محلي شما با تنظيم GMT +3.5 هم اکنون ۰۹:۱۹ بعد از ظهر ميباشد.





