بهبود تصاویر
در این پروژه از روشهای مختلفی برای بهبود تصاویر استفاده شده است .
Adaptive Median ******
***** میانه یکی از روشهای آماری است که در پردازش تصاویر برای کم کردن نویز استفاده می شود . در این ***** پنجره ای با اندازه مشخص روی پیکسل ها حرکت داده می شود . هر بار اندازه شدت نور پیکسلهای درون پنجره مرتب شده و مقدار میانه آن برای پیکسل وسط پنجره انتخاب می شود . این ***** باعث کم شدن وضوح تصویر و در نتیجه خرابی لبه ها می شود . برای تشخیص کاراکترها در یک تصویر ، کیفیت لبه های کاراکترها خیلی مهم است .
***** دیگری که با استفاده از روش میانه کار می کند Adaptive median است . این ***** با توجه به شدت نورهای مختلف درون پنجره ، شدت نور خروجی را انتخاب می کند . این انتخاب در بین میانه ، حداکثر و حداقل شدت نورهای درون پنجره و شدت نور پیکسل مورد نظر( مرکز پنجره) انجام می شود . در این ***** لبه ها بهتر از ***** معمولی باقی می ماند .
Spatial Smoothing
یکی از روشهای حذف نویز میانگین گیری از شدت نورهای درون پنجره است . هر چه پنجره بزرگتری استفاده شود میزان بلور شدن بیشتر شده و نویزهای بیشتری حذف می شود . البته این روش لبه ها را تخریب می کند .
Thresholding
قطعه بندی کردن تصویری که دودویی شده است عملیات آسان تری نسبت به قطعه بندی عکس با چند رنگ می باشد . از دودویی کردن تصاویر برای جدا کردن زمینه از قسمت بیرونی تصویر یا جدا کردن بخش مورد نظر در تصویر نیز می توان استفاده کرد . در دودویی کردن تصویر ، مقدار شدت نور پیکسلهایی که شدت نور آن از عدد N کمتر باشد ، 0 و در غیر این صورت 255 انتخاب می شود . پیدا کردن مقدار N به شکل خودکار یکی از مسائلی است که روشهای مختلفی برای آن پیشنهاد شده . در این پروژه از روش Otsu استفاده شده است . در روش Otsu فرض بر این است که تصویر از دو بخش کلی زمینه و foreground تشکیل شده باشد . با استفاده از عملیات آماری بر روی هیستوگرام تصویر ، بهترین شدت نوری که بتواند دو بخش را از هم جدا کند پیشنهاد می شود .
Projection افقی و عمودی
یکی از ساده ترین روشهای قطعه بندی تصاویر به بخشهای تشکیل دهنده آن استفاده از projection افقی یا عمودی است . در روش افقی ، تعداد پیکسلهایی در هر سطر که شدت نور آن برابر مقدار معینی باشد مشخص می شود . در روش عمودی ، تعداد پیکسلهایی در هر ستون که شدت نور آن برابر مقدار معینی باشد مشخص می شود .

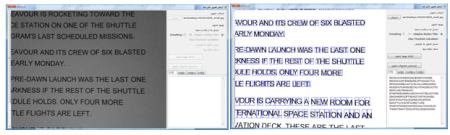
همانطور که در شکل 2 مشخص است با استفاده از روش افقی و بررسی محلهای حداقل شدن تعداد پیکسل ها می توان مکان سطرهای متن را پیدا کرد . اگر سطرها دارای زاویه باشند یا در تصویر نویز وجود داشته باشد نمودار projection دارای خطا خواهد بود که عملا ً استفاده از این روش را محدود به تصاویر با کیفیت بالا و سطرهای کاملا ً افقی می کند .
حذف نقاط تنها
نقطه هایی که بعد از استفاده از ***** و دودویی کردن تصویر باقی می ماند می تواند عملیات projection را با خطای زیادی روبرو کند . برای حذف این نقاط پنجره ایی روی تصویر حرکت داده می شود و اگر الگوهایی به شکل ماتریس های زیر دیده شود پیکسل مرکزی آن تغییر رنگ داده می شود .
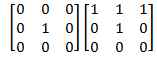
پیاده سازی و اجرا
روال کلی اجرای نرم افزار به این شرح است که ، ابتدا مجموعه ای از تصاویر حروف بزرگ انگلیسی به عنوان وزن اولیه و مجموعه دیگری که شامل تصاویر حروف الفبای بزرگ انگلیسی در فونت های دیگری است به نرم افزار داده می شود . پس از یادگیری وزنها می توان پنجره تشخیص تک کاراکتر یا تشخیص محتویات یک عکس اسکن شده را اجرا کرد .
تصاویر حروف بزرگ الفبای انگلیسی بدین شرح تهیه شده اند . حروف در نرم افزار Word نوشته شده ، از روی صفحه عکس گرفته شده ( print screen) و با استفاده از نرم افزار Paint حروف مانند تصویر زیر انتخاب شدند و در یک فایل با فرمت PNG ذخیره شد .

تصویر بالا به عنوان ورودی به نرم افزاری که در VB.NET نوشته شده و بوسیله روش projection کاراکترهای را از هم جدا می کند داده شده و خروجی آن تصاویر تک تک کاراکترها می باشد . در شکل زیر تعدادی از تصاویر قطعه قطعه شده از شکل 4 را مشاهده می کنید .
یک مجموعه برای وزنهای اولیه و ده مجموعه برای یادگیری با همین روش تهیه شده است . اندازه تصاویر عرض 10 و ارتفاع 13 پیکسل در نظر گرفته شده . شبکه LVQ ی که برای این مساله در نظر گرفته شده ماتریسی با ابعاد 130 در 26 است . 26 کلاس برای حروف الفبا و 130 وزن برای هر کدام از کلاس ها . پیکسلهای سفید ارزش 1- و پیکسلهای سیاه ارزش 1 را دارند .
در قسمت پردازش تصویر اسکن شده ، ابتدا تصویر به سیاه و سفید تبدیل شده ، سپس با یکی از روشهای انتخابی ***** می شود . بعد از ***** شدن ، شدت نور مناسب برای thresholding محاسبه شده و عملیات دودویی کردن تصویر انجام می شود . در آخر نیز "نقاط تنها" در تصویر حذف می شوند .
آزمایش یک کاراکتر
در ادامه چند تصویر از عملکرد تشخیص را مشاهده می کنید :

آزمایش تصویر اسکن شده
شکل زیر قبل و بعد از عملیات بهبود تصویر را نشان می دهد .
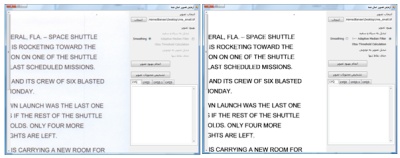
بعد از به اتمام رسیدن کار ، متن نهایی در جعبه متن های سمت راست پنجره برای هر کدام از شبکه های LVQ نمایش داده می شود . همچنین نحوه قطعه بندی کردن تصویر نیز در سمت چپ مشخص می شود .
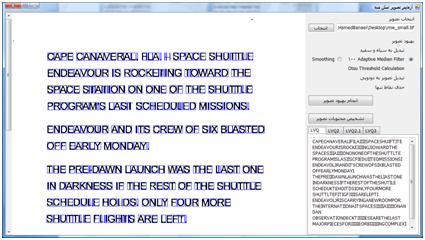
شکل های زیر همان متن اسکن شده است ولی از برگه چاپ شده آن بوسیله دوربین دیجیتال عکس گرفته شده . همان طور که مشاهده می شود انحنایی که دوربین در تصویر ایجاد می کند میزان قطعه بندی با استفاده از projection را به شدت با خطا روبرو می کند . در تابع OCR ، فرض بر این است که قطعه بندی به شکلی باشد که یک حرف تمام یک قطعه را بگیرد . اما در سطرهای پایین به علت زاویه دار بودن سطر ، کاراکتر بالا یا پایین قطعه قرار گرفته و باعث شده است که OCR تفسیر اشتباهی از تصویر قطعه قطعه شده داشته باشد .
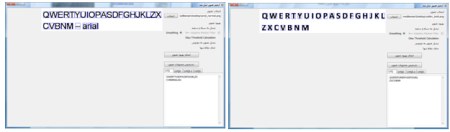
شکل زیر screen shot از پنجره Word است که تمامی حروف الفبای بزرگ انگلیسی در آن با فونت Arial و Calibri نوشته شده است . برای حذف نویز (screen shot نویز ندارد !) از smoothing معمولی استفاده شده است . همانطور که قابل مشاهده است قطعه بندی به شکل صحیحی صورت گرفته و حروف به درستی تشخیص داده شده اند . تصاویر به فرمت png هستند .
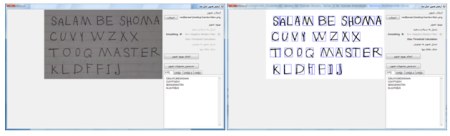
تصویر زیر عکسی است که با دوربین تلفن همراه از یک برگ کاغذ که با خودکار مشکی روی آن نوشته شده است تهیه شده . قطعه بندی و تشخیص دست خط پیچیده تر از روش پیاده سازی شده در این پروژه است . تعداد بسیار کمی از حروف در این شکل تشخیص داده شده اند .
منابع
Fundamentals of neural networks , Laurence Fausett
Digital Image Processing , Gonzalez
An Overview Of Character Recognition Focused On Off-line Handwriting Nafiz Arica, Student Member, IEEE and Fatos T. Yarman-Vural, Senior Member, IEEE
Wikipedia
Retrieval of Machine-printed Latin Documents through Word Shape Coding Shijian Lu, Chew Lim Tan