انجمن را در گوگل محبوب کنيد :
|
|||||||


| تبليغات سايت | |||||||||||||||||||||||||||||
  |
|
|
LinkBack | ابزارهاي تاپيک | نحوه نمايش |
 ۰۲-۸-۱۳۸۷, ۱۱:۵۹ بعد از ظهر
۰۲-۸-۱۳۸۷, ۱۱:۵۹ بعد از ظهر
|
#1 (لینک دائم) |
|
Administrator
 
تاريخ عضويت: ارديبهشت ۱۳۸۷
محل سكونت: تهران
پست ها: 179
تشكرها: 27
439 تشكر در 108 پست
My Mood:

|
در این پست مثالی در ارتباط با الگوریتم ژنتیک را می خواهیم بررسی کنیم. این مثال از مقاله ای با نام طراحی شبکه ی دیده بانی کیفیت آب در رودخانه های بزرگ به کمک ژنتیک الگوریتم انتخاب شده که در ژورنال ELSEVIER به چاپ رسیده که به اعتبار آن می افزاید.
در طراحی شبکه های دیده بانی کیفیت آب، نقاطی که از آنها آب نمونه برداری می شود از اهمیت بسیار زیادی برخوردارند در نتیجه ایستگاه ها باید با دقت انتخاب شوند که تمام اهداف مورد نظر را برآورد کنند. این ایستگاه ها باید خاصیت های زیر را داشته باشند:
تشریح محدوده در این مقاله محدوده ی رودخانه ی Nakdong بررسی شده که دومین رودخانه ی کره از نظر بزرگی است. شاخه ی اصلی این رودخانه 521.5 کیلومتر طول دارد. 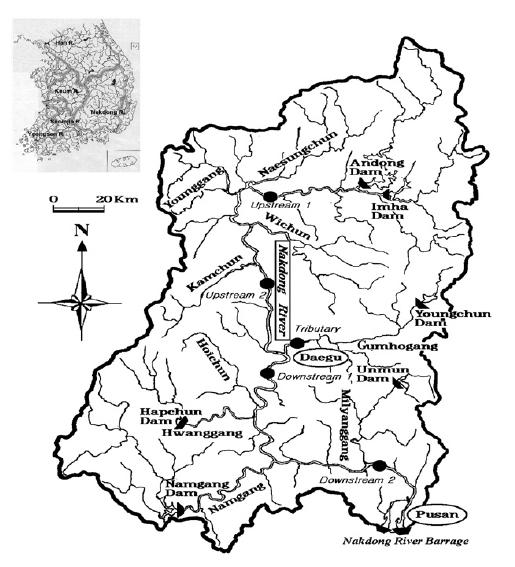 ارتباط GIS و GA مراحل کلی فرایند ژنتیک الگوریتم: 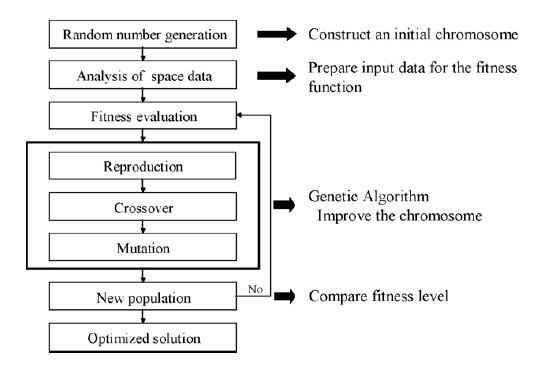 برای این بهینه سازی باید یک سیستم اطلاعات جغرافیایی (Geographic Information System) داشته باشیم که در اینجا از ArcView 3.2 به عنوان GIS استفاده شده. همچنین از library به نام GAlib و محیط برنامه نویسی VC++ برای اجرای عملیات الگوریتم ژنتیک استفاده شده.به منظور بهینه سازی هر مدلی توسط الگوریتم ژنتیک ابتدا باید موارد زیر به دقت تعیین شوند:
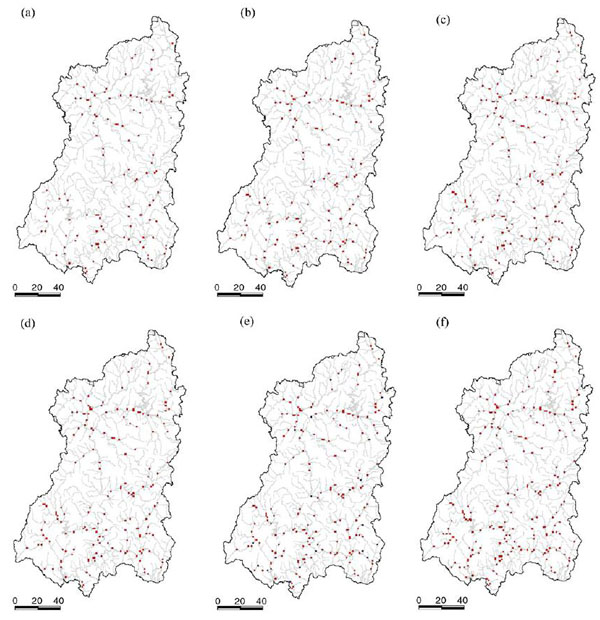
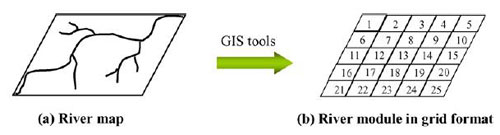 هر ژن می تواند یکی از آن عدد های یکتا باشد. مجموعه ای از این ژن ها یک کرومزم را تشکیل می دهند. تعداد ژن های هر کرومزم بستگی به تعداد ایستگاه هایی دارد که می خواهیم داشته باشیم. به عنوان مثال در این مقاله می خواهیم 110 ایستگاه داشته باشیم، پس تعداد ژن های هر کرومزم 110 عدد می باشد. هر کرومزوم دارای یک fitness می باشد. هر چه این fitness بالاتر باشد نشان دهنده ی نزدیک تر بودن آن به حالت مورد نظر ما می باشد.  ببخشید! شما گفتید که کل نقشه را جدول بندی می کنیم! که شامل رودخانه و خشکی می شود. اما اینطوری که من متوجه شدم ایستگاه ها حتما باید در کنار رودخانه باشند پس به نظر من درست این بود که فقط قسمت هایی که رودخانه در آن قرار دارد را شماره دهی کنیم! ببخشید! شما گفتید که کل نقشه را جدول بندی می کنیم! که شامل رودخانه و خشکی می شود. اما اینطوری که من متوجه شدم ایستگاه ها حتما باید در کنار رودخانه باشند پس به نظر من درست این بود که فقط قسمت هایی که رودخانه در آن قرار دارد را شماره دهی کنیم! " نکته ی خیلی خوبی را اشاره کردید. یکی از راه ها برای حل این مشکل راهی بود که شما به آن اشاره کردید که کمی سخت است. در این مقاله به جای این کار در قسمت fitness دهی به خانه هایی که رودخانه در آنها نیست ضریب صفر داده می شود و در نتیجه به خاطر سلامتی صفر خود به خود حذف خواهند شد! " " نکته ی خیلی خوبی را اشاره کردید. یکی از راه ها برای حل این مشکل راهی بود که شما به آن اشاره کردید که کمی سخت است. در این مقاله به جای این کار در قسمت fitness دهی به خانه هایی که رودخانه در آنها نیست ضریب صفر داده می شود و در نتیجه به خاطر سلامتی صفر خود به خود حذف خواهند شد! "پس هر کرومزوم نشان دهنده ی مکان تمامی ایستگاه ها و هر ژن نشان دهنده ی مکان یک ایستگاه می باشد! حال باید تابع fitness را تعریف کنیم.در بالا گفته شد هر ایستگاه باید دارای 6 خاصیت باشد. تابع سلامت باید هر شش خاصیت را بپوشاند. در این مقاله 6 خاصیت در 4 تابع گنجانده شده و تابع سلامت هر ژن به صورت مجموع این چهار تابع با یک وزن مشخص تعیین گردیده: 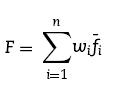  در الگوریتم ژنتیک همیشه یک سری کرومزم به عنوان جمعیت اولیه داریم که پس از محاسبه ی سلامت هر یک از آنها عملیات ترکیب و جهش روی آنها انجام شده و جمعیت جدید بوجود می آید. همانطور که می دانیم کرومزومی که سلامت بیشتری دارد امکان ترکیب و بقایش بیشتر می باشد. ترکیب بصورت تعویض چند ژن در دو کرومزم و جهش با تغییر تصادفی یک ژن صورت می گیرد. در هر نسل تعدادی جمعیت در فرایند ترکیب بوجود آمده و ما بقی مانند جمعیت اولیه تولید می شوند. اینجا سوال پیش می آید که تعداد جمعیت اولیه و درصد ترکیب و جهش در هر دوره چه مقدار باشد تا بهترین نتیجه حاصل شود! معمولا بهترین حالت برای این موارد با آزمایش و خطا بدست می آید. تجربه نشان داده که بهترین حالت معمولا با درصد ترکیب بالا و درصد جهش پایین بدست می آید. در این مقاله چهار حالت زیر امتحان شده و پس از گذشت 4000 نسل بهترین نتیجه در مورد دوم با جمعیت اولیه ی 300 و در صد ترکیب و جهش به ترتیب 80% و 1% مشاهده شده. 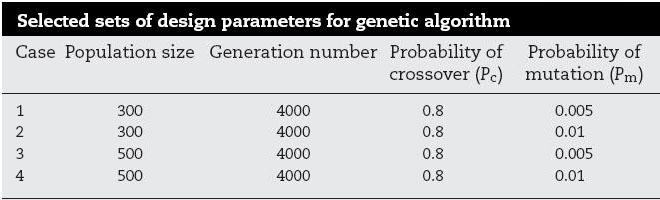 در زیر نمودار سلامت کرومزم های هر چهار حالت را مشاهده می کنید: 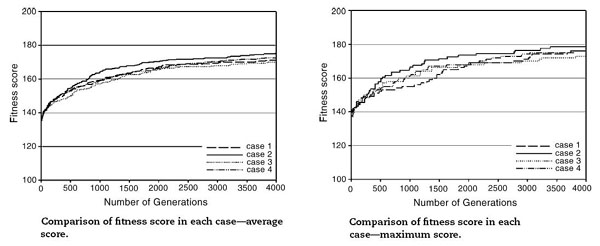 در زیر نتیجه ی نهایی این مقاله (در سمت راست) و حالت فعلی قرار گیری ایستگاه ها (در سمت چپ) را می توانید ببینید: 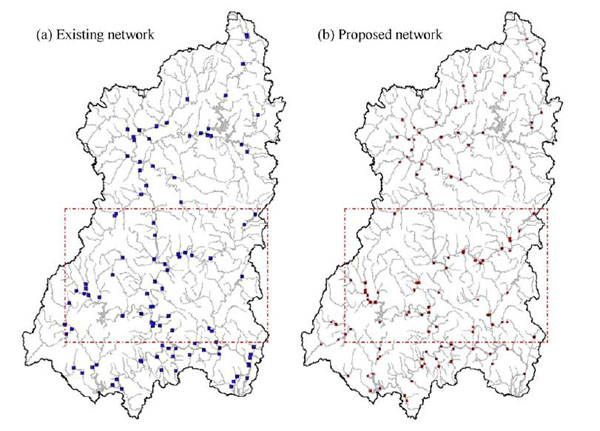 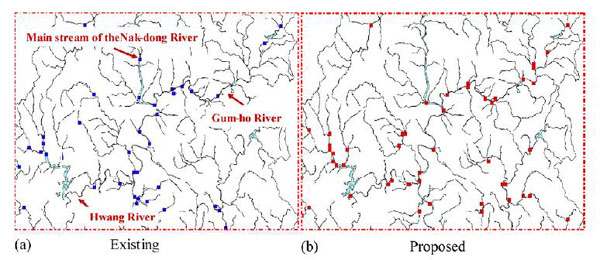 در این 110 ایستگاه محل 35 ایستگاه بین حالت بدست آمده و حالت موجود یکی می باشد و بقیه ی آنها با هم متفاوت می باشد که به این معنا است که برای بهبود سودمندی شبکه باید در بقیه ی آنها تغییر مکان ایجاد شود. در نهایت نتیجه ی این مقاله در صورتی که تعداد ایستگاه ها 130، 150، 170، 190 و 210 عدد می بود ارائه شده که به شکل زیر می باشد:
__________________
|

|

|

| #ADS | |
|
نشان دهنده تبلیغات
تبليغگر
تاريخ عضويت: -
محل سكونت: -
سن: 2010
پست ها: -
|
|

|
|
«
-
|
bio It
»
| كاربران در حال ديدن تاپيک: 1 (0 عضو و 1 مهمان) | |
 Linear Mode
Linear Mode

|
|

زمان محلي شما با تنظيم GMT +3.5 هم اکنون ۱۱:۲۵ بعد از ظهر ميباشد.





