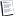 reg tree
reg tree
ШЁЩҮ ШҜЩ„Ш§ЫҢЩ„ ШІЫҢШұ Ъ©Ш§Шұ ШЁШ§Щ…ШҜЩ„ ШҜШұШ®ШӘЫҢ ЩҫЫҢШҙЩҶЩҮШ§ШҜ Щ…ЫҢ ШҙЩҲШҜ : 1- Ш§ЫҢЩҶ Щ…ШҜЩ„ ШЁЩҮ Ш·ЩҲШұ Щ…ШіШӘЩӮЫҢЩ… ШЁШ§ Щ…ШӘШәЫҢШұ ЩҮШ§ЫҢ ЩҫЫҢШҙ ШЁЫҢЩҶЫҢ Ъ©ЩҶЩҶШҜЩҮ Щ…ШұШӘШЁШ· Щ…ЫҢ ШЁШ§ШҙШҜ ШЁЩҶШ§ШЁШұШ§ЫҢЩҶ ЩҶШӘШ§ЫҢШ¬ Щ…ШҜЩ„ ШЁШұШ§ЫҢ ЩҒЩҮЩ…ЫҢШҜЩҶ ЩҲ ШҙШЁЫҢЩҮ ШіШ§ШІЫҢ ШўШіШ§ЩҶ ЩҮШіШӘЩҶШҜ .
2- ШҜШұШ®ШӘ ЩҮШ§ЫҢ ШӘШөЩ…ЫҢЩ… ЪҜЫҢШұЫҢ ШәЫҢШұ ЩҫШ§ШұШ§Щ…ШӘШұЫҢЪ© ШЁЩҲШҜЩҮ ЩҲ ЩҮЫҢЪҶ ШҜШ®Ш§Щ„ШӘЫҢ Ш§ШІ ШіЩҲЫҢ Ъ©Ш§ШұШЁШұ ШЁШұ ШұЩҲЫҢ ШўЩҶЩҮШ§ ШөЩҲШұШӘ ЩҶЩ…ЫҢ ЪҜЫҢШұШҜ .
3- Ш®ШұЩҲШ¬ЫҢ Щ…ШҜЩ„ Ш§ШІ ШҜЩӮШӘ ШЁШ§Щ„Ш§ЫҢ ШЁШұШ®ЩҲШұШҜШ§Шұ Ш§ШіШӘ Ъ©ЩҮ Щ…ЫҢ ШӘЩҲШ§ЩҶ ШўЩҶ ШұШ§ ШЁШ§ ШіШ§ЫҢШұ Щ…ШҜЩ„ ЩҮШ§ Щ…ЩӮШ§ЫҢШіЩҮ Ъ©ШұШҜ .
ШҜШұШ®ШӘ ШӘШөЩ…ЫҢЩ… ЪҶЫҢШіШӘ Шҹ
ЫҢЪ© ШҜШұШ®ШӘ Щ…Ш№Щ…ЩҲЩ„Ш§ Ш§ШІ ШұЫҢШҙЩҮ (root) ШҢ ШҙШ§Ш®ЩҮ (beach) ШҢ ЪҜШұЩҮ ЩҮШ§ (nods) ШҢ ШЁШұЪҜЩҮШ§ (leaf) ШӘШҙЪ©ЫҢЩ„ ШҙШҜЩҮ Ш§ШіШӘ ШҜШұШ®ШӘ ШӘШөЩ…ЫҢЩ… ЩҮЩ… ШЁЩҮ Ш·ЩҲШұ Щ…ШҙШ§ШЁЩҮ Ш§ШІ ЪҜШұЩҮ ЩҮШ§ Ъ©ЩҮ ШЁШ§ ШҜШ§ЫҢШұЩҮ ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮ Щ…ЫҢ ШҙЩҲЩҶШҜ ЩҲ ШҙШ§Ш®ЩҮ ЩҮШ§ Ъ©ЩҮ ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ Ш§ШӘШөШ§Щ„ ШЁЫҢЩҶ ЪҜШұЩҮ ЩҮШ§ Щ…ЫҢ ШЁШ§ШҙЩҶШҜ ШҢ ШӘШҙЪ©ЫҢЩ„ ШҙШҜЩҮ Ш§ШіШӘ . ШҜШұШ®ШӘ ШӘШөЩ…ЫҢЩ… ШЁЩҮ Щ…ЩҶШёЩҲШұ ШіШ§ШҜЪҜЫҢ ШҜШұ ШұШіЩ… Щ…Ш№Щ…ЩҲЩ„Ш§ Ш§ШІ ЪҶЩҫ ШЁЩҮ ШұШ§ШіШӘ ЩҲ ЫҢШ§ Ш§ШІ ШЁШ§Щ„Ш§ ШЁЩҮ ЩҫШ§ЫҢЫҢЩҶ Ъ©ШҙЫҢШҜЩҮ Щ…ЫҢ ШҙЩҲШҜ ШЁЩҮ Ш·ЩҲШұЫҢ Ъ©ЩҮ ШұЫҢШҙЩҮ (ЪҜШұЩҮ Ш§ЩҲЩ„ ШұШ§ ШұЫҢШҙЩҮ Щ…ЫҢ ЪҜЩҲЫҢЩҶШҜ) ШҜШұ ШЁШ§Щ„Ш§ ЩӮШұШ§Шұ ЪҜЫҢШұШҜ . Ш§ЩҶШӘЩҮШ§ЫҢ ЫҢЪ© ШІЩҶШ¬ЫҢШұЩҮ ШұЫҢШҙЩҮ ШҢ ШҙШ§Ш®ЩҮШҢ ЪҜШұЩҮ ШұШ§ ЫҢЪ© ШЁШұЪҜ Щ…ЫҢ ЩҶШ§Щ…ЩҶШҜ . Ш§ШІ ЩҮШұ ЫҢЪ© Ш§ШІ ЪҜШұЩҮ ЩҮШ§ЫҢ ШҜШ§Ш®Щ„ЫҢ (ЫҢШ№ЩҶЫҢ ЪҜШұЩҮ Ш§ЫҢ Ъ©ЩҮ ШЁШұЪҜ ЩҶШЁШ§ШҙШҜ) ШҜЩҲ ЫҢШ§ ЪҶЩҶШҜ ШҙШ§Ш®ЩҮ ШҜЫҢЪҜШұ Щ…ЫҢ ШӘЩҲШ§ЩҶЩҶШҜ Щ…ЩҶШҙШ№ШЁ ШҙЩҲЩҶШҜ . ЩҮШұ ЪҜШұЩҮ Щ…ШұШЁЩҲШ· ШЁЩҮ ЫҢЪ© Ш®ШөЩҲШөЫҢШӘ Щ…Ш№ЫҢЩҶ Ш§ШіШӘ ЩҲШҙШ§Ш®ЩҮ ЩҮШ§ ШЁЩҮ Щ…Ш№ЩҶШ§ЫҢ ШЁШ§ШІЩҮ Ш§ЫҢ Ш§ШІ Щ…ЩӮШ§ШҜЫҢШұ ЩҮШіШӘЩҶШҜ ШҢ Ш§ЫҢЩҶ ШЁШ§ШІЩҮ ЩҮШ§ЫҢ Щ…ЩӮШ§ШҜЫҢШұ ШҢ ШЁШ§ЫҢШҜ ШЁШ®Шҙ ЩҮШ§ЫҢ Щ…Ш®ШӘЩ„ЩҒ Щ…Ш¬Щ…ЩҲШ№ЩҮ Щ…ЩӮШ§ШҜЫҢШұ Щ…Ш№Щ„ЩҲЩ… ШұШ§ ШЁШұШ§ЫҢ Ш®ШөЩҲШөЫҢШӘ ЩҮШ§ ШЁЩҮ ШҜШіШӘ ШҜЩҮЩҶШҜ . Ш№Щ…Щ„ Ш§ЩҶШҙШ№Ш§ШЁ ШӘЩҲШіШ· ЫҢЪ©ЫҢ Ш§ШІ Щ…ШӘШәЫҢШұЩҮШ§ЫҢ ЩҫЫҢШҙ ШЁЫҢЩҶЫҢ Ъ©ЩҶЩҶШҜЩҮ Ш§ЩҶШ¬Ш§Щ… Щ…ЫҢ ЩҫШ°ЫҢШұШҜ ШҢ ШЁШ§ШІЩҮ ЩҮШ§ЫҢ Ш§ЩҶШҙШ№Ш§ШЁ Ш·ЩҲШұЫҢ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЫҢ ШҙЩҲЩҶШҜ Ъ©ЩҮ Щ…Ш¬Щ…ЩҲШ№ Щ…Ш¬Ш°ЩҲШұ Ш§ЩҶШӯШұШ§ЩҒ Ш§ШІ Щ…ЫҢШ§ЩҶЪҜЫҢЩҶ ШҜШ§ШҜЩҮ ЩҮШ§ЫҢ ЩҮШұ ЪҜШұЩҮ ШұШ§ ШӯШҜШ§ЩӮЩ„ Ъ©ЩҶЩҶШҜ .
ЩҮЩҶЪҜШ§Щ…ЩҠ ЩғЩҮ Ш®ШұЩҲШ¬ЩҠ ЩҠЩғ ШҜШұШ®ШӘШҢ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ ЪҜШіШіШӘЩҮ Ш§ШІ ЩҠЩғ Щ…Ш¬Щ…ЩҲШ№ЩҮ Щ…ЩӮШ§ШҜЩҠШұ Щ…Щ…ЩғЩҶ Ш§ШіШӘШӣ ШЁЩҮ ШўЩҶ Ш·ШЁЩӮЩҮ ШЁЩҶШҜЫҢ ШҜШұШ®ШӘЫҢ ЪҜЩҒШӘЩҮ Щ…ЩҠ ШҙЩҲШҜ (Щ…Ш«Щ„Ш§ Щ…ЩҲЩҶШ« ЫҢШ§ Щ…Ш°Ъ©ШұШҢШЁШұЩҶШҜЩҮ ЫҢШ§ ШЁШ§ШІЩҶШҜЩҮ) ЩҮЩҶЪҜШ§Щ…ЩҠ ЩғЩҮ ШЁШӘЩҲШ§ЩҶ Ш®ШұЩҲШ¬ЩҠ ШҜШұШ®ШӘ ШұШ§ ЩҠЩғ Ш№ШҜШҜ ШӯЩӮЩҠЩӮЩҠ ШҜШұ ЩҶШёШұ ЪҜШұЩҒШӘ ШўЩҶ ШұШ§ШҢ ШұЪҜШұШіЫҢЩҲЩҶ ШҜШұШ®ШӘЫҢ Щ…ЩҠ ЩҶШ§Щ…ЩҶШҜ ЩҲЫҢШ§ ШЁЩҮ Ш№ШЁШ§ШұШӘ ШҜЫҢЪҜШұ Ш§ЪҜШұ Щ…ШӘШәЫҢШұ ЩҮШ§ЫҢ Щ…Ш§ Ш№ШҜШҜЫҢ (numerical) ШЁШ§ШҙЩҶШҜ Ш§ШІ ШұЪҜШұШіЫҢЩҲЩҶ ШҜШұШ®ШӘЫҢ (regression tree) ЩҲШ§ЪҜШұ Щ…Ш·Щ„ЩӮ ЩҲ ЩӮЫҢШ§ШіЫҢ ШЁШ§ШҙЩҶШҜ Ш§ШІ Ш·ШЁЩӮЩҮ ШЁЩҶШҜЫҢ ШҜШұШ®ШӘЫҢ(classification tree) Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢ Ъ©ЩҶЫҢЩ… . ЩҒШұШ§ЫҢЩҶШҜ Ш§ЩҶШҙШ№Ш§ШЁ ШҜШұ ЩҮШұ ЪҜШұЩҮ ШЁШ§ШұЩҮШ§ ШӘЪ©ШұШ§Шұ Щ…ЫҢ ШҙЩҲШҜ ШӘШ§ ШЁЩҮ ЪҜШұЩҮ ЩҫШ§ЫҢШ§ЩҶЫҢ ЫҢШ§ ЩҮЩ…Ш§ЩҶ ШЁШұЪҜ ШЁШұШіШҜ Ъ©ЩҮ ШҜШұ ШЁШұЪҜ Щ…Ш¬Щ…ЩҲШ№ Щ…Ш¬Ш°ЩҲШұ Ш§ЩҶШӯШұШ§ЩҒ Ш§ШІ Щ…ЫҢШ§ЩҶЪҜЫҢЩҶ ШҜШ§ШҜЩҮ ЩҮШ§ ШӯШҜЩҲШҜШ§ ШЁЩҮ ШөЩҒШұ Щ…ЫҢ ШұШіШҜ ШҢ ШЁШ§ Ш§ЫҢЩҶ Ъ©Ш§Шұ ШҜШұШ®ШӘ ШЁШІШұЪҜЫҢ ШӘЩҲШіШ№ЩҮ ЩҫЫҢШҜШ§ Ш®ЩҲШ§ЩҮШҜ Ъ©ШұШҜ . ЩҒШұШўЫҢЩҶШҜ ШӘШҙЪ©ЫҢЩ„ ШҜШ§ШҜЩҶ ШұЪҜШұШіЫҢЩҲЩҶ ШҜШұШ®ШӘЫҢ ШҙШ§Щ…Щ„ 5 Щ…ШұШӯЩ„ЩҮ Ш§ШіШӘ .
1)- Щ…ШұШӯЩ„ЩҮ Щ…ЩӮШҜШ§Шұ ШҜЩҮЫҢ Ш§ЩҲЩ„ЫҢЩҮ (initialization) : ШҜШұ Ш§ЫҢЩҶ Щ…ШұШӯЩ„ЩҮ Щ…ШӘШәЫҢШұ ЩҮШ§ЫҢ ЩҫЫҢШҙ ШЁЫҢЩҶЫҢ Ъ©ЩҶЩҶШҜЩҮ Ш§ЩҶШӘШ®Ш§ШЁ ШҙШҜЩҮ ЩҲ ЩҒШұШ§ЫҢЩҶШҜ ЩҫЫҢШҙ ЩҫШұШҜШ§ШІЫҢ ШҜШ§ШҜЩҮ ЩҮШ§ Ш§ЩҶШ¬Ш§Щ… Щ…ЫҢ ЪҜЫҢШұШҜ .
2)- ШіШ§Ш®ШӘЩҶ ШҜШұШ®ШӘ (tree building) : Ш§ЫҢЩҶ Щ…ШұШӯЩ„ЩҮ ШЁШ§ ШӘЩӮШіЫҢЩ… ШҙШҜЩҶ ЪҜШұЩҮ ЩҲШ§Щ„ШҜ ШЁЩҮ ШҜЩҲ ЪҜШұЩҮ ЩҒШұШІЩҶШҜ ШҙШұЩҲШ№ Щ…ЫҢ ШҙЩҲШҜ ШҢ ШҜШұ ЩҮШұ ЪҜШұЩҮ ЩҲШ§Щ„ШҜ ШӘЩ…Ш§Щ… Щ…ЩҲШ¶ЩҲШ№Ш§ШӘ ЩҲ Ш§ЩҶШҙШ№Ш§ШЁШ§ШӘ Щ…Щ…Ъ©ЩҶ Ш§ШұШІЫҢШ§ШЁЫҢ Щ…ЫҢ ШҙЩҲШҜ ЩҲ ШіШұ Ш§ЩҶШ¬Ш§Щ… ШЁЩҮШӘШұЫҢЩҶ Ш§ЩҶШҙШ№Ш§ШЁ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЫҢ ШҙЩҲШҜ
ШЁЩҮШӘШұЫҢЩҶ Ш§ЩҶШҙШ№Ш§ШЁ Ш§ЩҶШҙШ№Ш§ШЁЫҢ Ш§ШіШӘ Ъ©ЩҮ ШЁЫҢШҙШӘШұЫҢЩҶ Щ…ЩӮШҜШ§Шұ ШұШ§ ШҜШ§ШҙШӘЩҮ ШЁШ§ШҙШҜ . ШЁШ§ ШӘЪ©ШұШ§Шұ ЩҫШұЩҲШіЩҮ ШЁШ§Щ„Ш§ ШЁШұШ§ЫҢ ЩҮШұ Ш§ЩҶШҙШ№Ш§ШЁ ШҜШұШ®ШӘ ШЁШІШұЪҜЫҢ ШҙЪ©Щ„ Щ…ЫҢ ЪҜЫҢШұШҜ Ъ©ЩҮ ШЁЩҮ ШҜШұШ®ШӘ ШӯШҜШ§Ъ©Ш«Шұ (maximal tree ) Щ…Ш№ШұЩҲЩҒ Ш§ШіШӘ Ъ©ЩҮ ШҙШ§Ш®ЩҮ ЩҮШ§ ЩҲ ЪҜШұЩҮ ЩҮШ§ЫҢ ШІЫҢШ§ШҜЫҢ ШҜШ§ШұШҜ ЩҲ Ъ©Ш§Шұ ШЁШ§ ШўЩҶ ШіШ®ШӘ Щ…ЫҢ ШЁШ§ШҙШҜ ШЁЩҶШ§ШЁШұШ§ЫҢЩҶ ШЁШұШ§ЫҢ ШұШіЫҢШҜЩҶ ШЁЩҮ ЫҢЪ© ШҜШұШ®ШӘ ШЁЩҮЫҢЩҶЩҮ ЩҲ Ъ©Ш§Шұ ШўЩ…ШҜ ШЁШ§ЫҢШҜ ШҙШ§Ш®ЩҮ ЩҮШ§ЫҢ Ш§Ш¶Ш§ЩҒЫҢ ШұШ§ ЩҮШұШі Ъ©ШұШҜ .
3)- ЩҮШұШі Ъ©ШұШҜЩҶ ШҜШұШ®ШӘ (tree pruning) : ШҜЩҲ ШұЩҲШҙ ШӯШұШө ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ 1- ЩҮШұШі ЩӮШЁЩ„ Ш§ШІ ШҙЪ©Щ„ ЪҜЫҢШұЫҢ ШҜШұШ®ШӘ ШӯШҜШ§Ъ©Ш«Шұ (pre-pruning) 2- ЩҮШұШі ШЁШ№ШҜ Ш§ШІ ШҙЪ©Щ„ ЪҜЫҢШұЫҢ ШҜШұШ®ШӘ ШӯШҜШ§Ъ©Ш«Шұ (past-pruning)
ШҜШұ ШұЩҲШҙ Ш§ЩҲЩ„ ЩҒШұШ§ЫҢЩҶШҜ ЩҮШұШі Ш§Ш¬Ш§ШІЩҮ ЩҶЩ…ЫҢ ШҜЩҮШҜ ШҙШ§Ш®ЩҮ ЩҮШ§ЫҢ Ш§Ш¶Ш§ЩҒЫҢ ШӘЩҲЩ„ЫҢШҜ ШҙЩҲЩҶШҜ ЩҲЩ„ЫҢ ШҜШұ ШұЩҲШҙ ШҜЩҲЩ… Ш§ШЁШӘШҜШ§ ШҜШұШ®ШӘ ШӯШҜШ§Ъ©Ш«Шұ ШӘШҙЪ©ЫҢЩ„ Щ…ЫҢ ШҙЩҲШҜ ЩҲ ШіЩҫШі ЩҒШұШўЫҢЩҶШҜ ЩҮШұШі Ш§ЩҶШ¬Ш§Щ… Щ…ЫҢ ЪҜЫҢШұШҜ . ШҜШұ Ш§ЫҢЩҶ Ш·ШұШӯ Ш§ШІ ЫҢЪ©ЫҢ Ш§ШІ ШӘЪ©ЩҶЫҢЪ© ЩҮШ§ЫҢ ШұЩҲШҙ ШҜЩҲЩ… ШЁЩҮ ЩҶШ§Щ… ЩҮШІЫҢЩҶЩҮ ЩҫЫҢЪҶЫҢШҜЪҜЫҢ ЩҮШұШі (cost complexity pruning ) Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢ ШҙЩҲШҜ( ШЁШұЫҢЩ…Ш§ЩҶ ЩҲ ЩҮЩ…Ъ©Ш§ШұШ§ЩҶ 1984).
4)- Ш§ЩҶШӘШ®Ш§ШЁ ШҜШұШ®ШӘ ШЁЩҮЫҢЩҶЩҮ (optimal tree selection) : ШҜШұШ®ШӘ ШЁЩҮЫҢЩҶЩҮ ШЁШұ Ш§ШіШ§Ші ШӯШҜШ§ЩӮЩ„ Ъ©ШұШҜЩҶ Ш®Ш·Ш§ЫҢ ЩҫЫҢШҙ ШЁЫҢЩҶЫҢ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЫҢ ШҙЩҲШҜ Ъ©ЩҮ ШҜЩҲ ШұЩҲШҙ ШЁШұШ§ЫҢ Щ…ШӯШ§ШіШЁЩҮ Ш®Ш·Ш§ЫҢ ЩҫЫҢШҙ ШЁЫҢЩҶЫҢ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ 1- ШўШІЩ…ЩҲЩҶ ШҜШіШӘЪҜШ§ЩҮ Щ…ШіШӘЩӮЩ„ 2- ШўШІЩ…ЩҲЩҶ ШөШӯШӘ ШіЩҶШ¬ЫҢ Ъ©ЩҮ ШұЩҲШҙ Ш§ЩҲЩ„ ЩҮЩҶЪҜШ§Щ…ЫҢ Щ…ЩҲШұШҜ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩӮШұШ§Шұ Щ…ЫҢ ЪҜЫҢШұШҜ Ъ©ЩҮ ШӘШ№ШҜШ§ШҜ ШҜШ§ШҜЩҮ ЩҮШ§ЫҢ ШІЫҢШ§ШҜЫҢ ШҜШ§ШҙШӘЩҮ ШЁШ§ШҙЫҢЩ… ШҜШұ ШәЫҢШұ ШўЫҢЩҶ ШөЩҲШұШӘ Ш§ШІ ШұЩҲШҙ ШҜЩҲЩ… Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢ ШҙЩҲШҜ .
ЩҲЩҠШұШ§ЩҠШҙ ШҙШҜЩҮ ШӘЩҲШіШ· arsalan_4421; Ы°Ыі-ЫұЫ¶-ЫұЫіЫёЫ№ ШҜШұ ШіШ§Ш№ШӘ Ы°Ыі:Ы°Ы· ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|