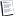
ШіЩ„Ш§Щ…
Ш§ШІ ШҜЩҲШіШӘШ§ЩҶЫҢ Ъ©ЩҮ ШҜШұ ШІЩ…ЫҢЩҶЩҮ ШЁШ§ШІЫҢШ§ШЁЫҢ ШӘШөЩҲЫҢШұ Ъ©Ш§Шұ Ъ©ШұШҜЩҶ Ъ©ШҙЫҢ Щ…ЫҢ ШӘЩҲЩҶЩҮ Ш§ЫҢЩҶ Ш§Щ„ЪҜЩҲШұЫҢШӘЩ… ШұШ§ ШӘЩҲШ¶ЫҢШӯ ШҜЩҮШҜ
Input: a query object x1 (a labeled data)
the database objects X = {x2, ...xn} (unlabeled data)
Process:
Create a n Г— n probabilistic transition matrix P1 based on one
type of shape similarity (eg. SC)
Create a nГ—n probabilistic transition matrix P2 based on another
type of shape similarity (eg. IDSC)
Create two sets Y1, Y2 such that Y1 = Y2 = {x1}
Create two sets X1,X2 such that X1 = X2 = X
Loop for m iterations:
Use P1 to learn a new similarity sim1j by graph transduction
when Y1 is used as the query objects (j = 1, ...,m is the iteration index)
Use P2 to learn a new similarity simj2 by graph transduction
when Y2 is used as the query objects
Add the p nearest neighbors from X1 to Y1 based on the
similarity simj1 to Y2
Add the p nearest neighbors from X2 to Y2 based on the
similarity simj2 to Y1
X1 = X1 вҲ’ Y1
X2 = X2 вҲ’ Y2
(Then X1,X2 will be unlabeled data for graph transduction
in the next iteration)
Co-transduction algorithm
|