ЩҫШұШҜШ§ШІШҙ ШөШҜШ§
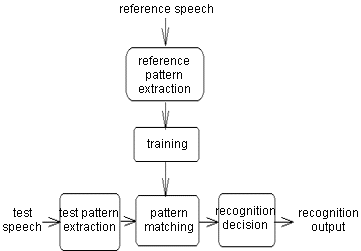
ШӘШҙШ®ЫҢШө ШөШҜШ§ ЫҢШ§ ШҙЩҶШ§ШіШ§ЫҢЫҢ ЪҜЩҲЫҢЩҶШҜЩҮ(Speaker Identification) ЫҢЪ©ЫҢ Ш§ШІ Щ…ШіШ§ЫҢЩ„ Ш№Щ„ЩҲЩ… ШұШ§ЫҢШ§ЩҶЩҮвҖҢ ЩҲ ЩҮЩҲШҙ Щ…ШөЩҶЩҲШ№ЫҢ Ш§ШіШӘ Ъ©ЩҮ ЩҮШҜЩҒ ШўЩҶ ШҙЩҶШ§ШіШ§ЫҢЫҢ ЫҢЪ© ЩҒШұШҜ ШӘЩҶЩҮШ§ Ш§ШІ ШұЩҲЫҢ ШөШҜШ§ЫҢ ШҙШ®Шө Ш§ШіШӘ. ЫҢЪ©ЫҢ Ш§ШІ Ш§ШөЩ„ЫҢвҖҢШӘШұЫҢЩҶ Ш§ШЁШІШ§ШұЩҮШ§ЫҢ ШұЫҢШ§Ш¶ЫҢ ШЁШұШ§ЫҢ ШӯЩ„ Ш§ЫҢЩҶ Щ…ШіЫҢЩ„ЩҮ Щ…ШҜЩ„ЩҮШ§ЫҢ ЩҫЩҶЩҮШ§ЩҶ Щ…Ш§ШұЪ©ЩҲЩҒ ЩҮШіШӘЩҶШҜ. ШЁШұШ§ЫҢ ШӯЩ„ Ш§ЫҢЩҶ Щ…ШіШҰЩ„ЩҮ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Щ…ШҜЩ„ ЩҫЩҶЩҮШ§ЩҶ Щ…Ш§ШұЪ©ЩҲЩҒ (Щ….Щҫ.Щ…) Ш§ЫҢЩҶ Щ…ШҜЩ„ЩҮШ§ЫҢ ШўЩ…Ш§ШұЫҢ Ш§ШЁШӘШҜШ§ ШЁШ§ЫҢШҜ Щ…ЩҲШұШҜ ШўЩ…ЩҲШІШҙ ЩӮШұШ§Шұ ШЁЪҜЫҢШұЩҶШҜ. ШЁШұШ§ЫҢ Ш§ЫҢЩҶ Щ…ШұШӯЩ„ЩҮ Ш§ШЁШӘШҜШ§ Щ…ЩӮШҜШ§Шұ ЩӮШ§ШЁЩ„ ШӘЩҲШ¬ЩҮЫҢ Ш§ШІ ШөШҜШ§ЫҢ Ш¶ШЁШ· ШҙШҜЩҮ Ш§ЩҒШұШ§ШҜ ЩҫШұШҜШ§ШІШҙ Щ…ЫҢвҖҢШҙЩҲШҜ. ШҜШ§ШҜЩҮвҖҢЩҮШ§ЫҢ ЩҫШұШҜШ§ШІШҙ ШҙШҜЩҮ Ъ©ЩҮ ШҜШұ ШӯЩӮЫҢЩӮЫҢШӘ Щ…Ш¬Щ…ЩҲШ№ЩҮ Ш№ШёЫҢЩ…ЫҢ Ш§ШІ Ш§Ш№ШҜШ§ШҜ Щ…ЫҢвҖҢвҖҢШЁШ§ШҙЩҶШҜ Щ…ШӘЩҶШ§ЩҲШЁШ§ЩӢ Щ…ЩҲШұШҜ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩӮШұШ§Шұ Щ…ЫҢЪҜЫҢШұЩҶШҜ ШӘШ§ Щ….Щҫ.Щ…. ШЁШұШ§ЫҢ ЩҮШұ ЪҜЩҲЫҢЩҶШҜЩҮ ШЁЩҮ ШҜШіШӘ ШўЫҢШҜ. ШҜШұ ШӯЩӮЫҢЩӮШӘ Щ….Щҫ.Щ….вҖҢЩҮШ§ Щ…Ш§ЩҶЩҶШҜ ЫҢЪ© Щ…Ш§ШҙЫҢЩҶ Ш№Щ…Щ„ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ Ъ©ЩҮ ЩҲШұЩҲШҜЫҢ ШўЩҶЩҮШ§ ЫҢЪ© ШіШұЫҢ ШҜШ§ШҜЩҮ Ш§ШіШӘ ЩҲ Ш®ШұЩҲШ¬ЫҢШҙШ§ЩҶ ЫҢЪ© Ш№ШҜШҜ ШЁШұШ§ЫҢ ЩҮШұ Щ…Ш¬Щ…ЩҲШ№ЩҮвҖҢШ§ЫҢ Ш§ШІ ШҜШ§ШҜЩҮвҖҢЩҮШ§ШҢ ШЁЩҮ Ш§ЫҢЩҶ ШөЩҲШұШӘ Ъ©ЩҮ ШўЩҶ Ш№ШҜШҜ ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ Ш§Ш®ШӘЩ„Ш§ЩҒ ШҜШ§ШҜЩҮвҖҢЩҮШ§ЫҢ ЩҲШұЩҲШҜЫҢ ШЁШ§ Щ….Щҫ.Щ… ЩҮШұ Щ…Ш§ШҙЫҢЩҶ Ш§ШіШӘ. ШЁШұШ§ЫҢ ШўЩ…ЩҲШІШҙ Щ….Щҫ.Щ… ШҜШұ ЩҮШұ ШӘЩҶШ§ЩҲШЁ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ШЁЩҮ Щ….Щҫ.Щ… ШҜШ§ШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ ЩҲ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЫҢ Щ….Щҫ.Щ… Ш°ШұЩҮвҖҢШ§ЫҢ ШӘШәЫҢЫҢШұ ШҜШ§ШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ ШӘШ§ Ш№ШҜШҜ Ш®ШұЩҲШ¬ЫҢ (Ъ©ЩҮ ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ Ш§Ш®ШӘЩ„Ш§ЩҒ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ШЁШ§ Щ….Щҫ.Щ… Ш§ШіШӘ) Ъ©ЩҲЪҶЪ©ШӘШұ ШҙЩҲШҜ. ШЁШұШ§ЫҢ Ш§Ш·Щ…ЫҢЩҶШ§ЩҶ Ш§ШІ Ш§ЫҢЩҶЪ©ЩҮ ШӘШәЫҢЫҢШұ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЫҢ Щ….Щҫ.Щ… ШҜШұ Ш¬ЩҮШӘ ШҜШұШіШӘ Ш§ЩҶШ¬Ш§Щ… Щ…ЫҢвҖҢЪҜЫҢШұШҜ ЩҲ ЩҶЩҮШ§ЫҢШӘШ§ ШЁЩҮ ШӯШҜШ§ЩӮЩ„ ШҙШҜЩҶ Ш№ШҜШҜ Ш®ШұЩҲШ¬ЫҢ Щ…ЫҢвҖҢШ§ЩҶШ¬Ш§Щ…ШҜ Ш§ШІ ЫҢЪ© ШұЩҲШҙ ШұЫҢШ§Ш¶ЫҢ ШЁЩҮ ЩҶШ§Щ… Expectation Maximization Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ШҜШұ ЩҶЩҮШ§ЫҢШӘ ШЁШ№ШҜ Ш§ШІ ШўЩ…ЩҲШІШҙ Ш§ЫҢЩҶ Щ…ШҜЩ„ЩҮШ§ Ъ©ЩҮ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШөШҜШ§ЫҢ Щ…ШұШ¬Ш№ Ш§ЩҶШ¬Ш§Щ… ШҙШҜЩҮШҢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ ШЁШұШ§ЫҢ ШўШІЩ…Ш§ЫҢШҙ ШіШ§Щ…Ш§ЩҶЩҮ ШөШҜШ§ЫҢ ЫҢЪ©ЫҢ Ш§ШІ Ш§ЩҒШұШ§ШҜЫҢ Ъ©ЩҮ ЩӮШЁЩ„Ш§ Ш§ШІ ШөШҜШ§ЫҢ ЩҲЫҢ ШЁШұШ§ЫҢ ШўЩ…ЩҲШІШҙ Щ….Щҫ.Щ… Ш§ШіШӘЩҒШ§ШҜЩҮ ШҙШҜЩҮ ШұШ§ ШЁЩҮ ЩҮШұ ЫҢЪ© Ш§ШІ Щ….Щҫ.Щ…вҖҢЩҮШ§ ШҜШ§ШҜ. Щ….Щҫ.Щ…вҖҢШ§ЫҢ Ъ©ЩҮ Ъ©ЩҲЪҶЪ©ШӘШұЫҢЩҶ Ш№ШҜШҜ ШұШ§ ШӘЩҲЩ„ЫҢШҜ Щ…ЫҢвҖҢЪ©ЩҶШҜ ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҒШұШҜ ШҙЩҶШ§ШіШ§ЫҢЫҢ ШҙШҜЩҮ ШҜШұ ЩҶШёШұ ЪҜШұЩҒШӘЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ.
ШіШ§Щ…Ш§ЩҶЩҮ ШЁШ§Щ„Ш§ ШЁЩҮ ШҜЩ„Ш§ЫҢЩ„ Щ…Ш®ШӘЩ„ЩҒЫҢ Ш§ШӯШӘЩ…Ш§Щ„ Ш®Ш·Ш§ ШҜШ§ШұШҜ. ШҙШЁШ§ЩҮШӘ ШөШҜШ§ЫҢ Ш§ЩҒШұШ§ШҜ ШЁЩҮ ЫҢЪ©ШҜЫҢЪҜШұ (Ъ©ЩҮ ЪҜШ§ЩҮЫҢ Ш§ЩҶШіШ§ЩҶЩҮШ§ ШұШ§ ЩҶЫҢШІ ШЁЩҮ Ш§ШҙШӘШЁШ§ЩҮ Щ…ЫҢвҖҢвҖҢШ§ЩҶШҜШ§ШІШҜ)ШҢ ШөШҜШ§ЩҮШ§ЫҢ ШӯШ§ШҙЫҢЩҮ (ЩҶЩҲЫҢШІ)ШҢ Щ…ШӯШҜЩҲШҜЫҢШӘ ШӯШ¬Щ… ШҜШ§ШҜЩҮвҖҢЩҮШ§ЫҢ Щ…ШұШ¬Ш№ ШЁШұШ§ЫҢ ШўЩ…ЩҲШІШҙ ЩҲ ШәЫҢШұЩҮ Ш§ШІ Ш¬Щ…Щ„ЩҮ Ш§ЫҢЩҶ Ш§ШҙШӘШЁШ§ЩҮвҖҢЩҮШ§ ЩҮШіШӘЩҶШҜ. ШЁШұШ§ЫҢ ШЁШ§Щ„Ш§ ШЁШұШҜЩҶ Ш¶ШұЫҢШЁ Ш§Ш·Щ…ЫҢЩҶШ§ЩҶ ШіШ§Щ…Ш§ЩҶЩҮ ШҙЩҶШ§ШіШ§ЫҢЫҢ ЪҜЩҲЫҢЩҶШҜЩҮ ШұЩҲШҙЩҮШ§ЫҢ Щ…Ш®ШӘЩ„ЩҒЫҢ ШЁЪ©Ш§Шұ Щ…ЫҢвҖҢШұЩҲШҜ Ъ©ЩҮ ЩҮШұ ШіШ§Щ„ЩҮ ЩҶЫҢШІ ШЁШ§ ЩҫЫҢШҙШұЩҒШӘ ШӘШӯЩӮЫҢЩӮШ§ШӘ ШҜШұ ШҜЩҶЫҢШ§ ШЁЩҮ ШўЩҶЩҮШ§ Ш§Ш¶Ш§ЩҒЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ.
Ш§ШІ Ш¬Щ…Щ„ЩҮ Ш§ШіШӘЩҒШ§ШҜЩҮ ШӘШұЪ©ЫҢШЁЫҢ Ш§ШІ ШӘШҙШ®ЫҢШө ЪҜЩҒШӘШ§Шұ ЩҲ ШӘШҙШ®ЫҢШө ШөШҜШ§ Ъ©ЩҮ ШҜШұ ШўЩҶ ЩҶЩҮ ШӘЩҶЩҮШ§ ШөШҜШ§ЫҢ ЪҜЩҲЫҢЩҶШҜЩҮ ШЁЩ„Ъ©ЩҮ Ъ©Щ„Щ…ЩҮ(ЩҮШ§ЫҢ) ЩҲЫҢ ЩҶЫҢШІ Щ…ЩҲШұШҜ ШўШІЩ…Ш§ЫҢШҙ ЩӮШұШ§Шұ Щ…ЫҢвҖҢЪҜЫҢШұЩҶШҜ. ЪҜЩҲЫҢЩҶШҜЩҮ ШЁШ§ЫҢШҜ Ъ©Щ„Щ…Ш§ШӘ Щ…ШҙШ®ШөЫҢ ШұШ§ ШЁЪ©Ш§Шұ ШЁШЁШұШҜ ШӘШ§ ШіШ§Щ…Ш§ЩҶЩҮ ШЁЩҮ ЩҲЫҢ Ш§Ш¬Ш§ШІЩҮ Ш№ШЁЩҲШұ ШЁШҜЩҮШҜ. ЩҮЩ…ЪҶЩҶЫҢЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ Ш§ШІ ЫҢЪ© Ш№ШҜШҜ ШӯШҜШ§Ъ©Ш«Шұ ШЁШұШ§ЫҢ Щ…ЩӮШ§ЫҢШіЩҮ Ш§Ш№ШҜШ§ШҜ Ш®ШұЩҲШ¬ЫҢ Щ….Щҫ.Щ… Ш§ШіШӘЩҒШ§ШҜЩҮ Ъ©ШұШҜ ШЁШ·ЩҲШұЫҢ Ъ©ЩҮ Щ….Щҫ.Щ… Щ…ЩҲШұШҜ ЩҶШёШұ ЩҶЩҮ ШӘЩҶЩҮШ§ ШЁШ§ЫҢШҜ Ъ©ЩҲЪҶЪ©ШӘШұЫҢЩҶ Ш№ШҜШҜ ШұШ§ ШЁШҜЩҮШҜ ШЁЩ„Ъ©ЩҮ ШЁШ§ЫҢШҜ Ш§ЫҢЩҶ Ш№ШҜШҜ Ш§ШІ ЫҢЪ© Ш№ШҜШҜ Щ…ШұШ¬Ш№ ЩҶЫҢШІ Ъ©ЩҲЪҶЪ©ШӘШұ ШЁШ§ШҙШҜ. ШҜШұ ЩҶШӘЫҢШ¬ЩҮ Ш§ЫҢЩҶ ШӘШәЫҢЫҢШұ ШҜШұ ШіШ§Щ…Ш§ЩҶЩҮ Ш¶ШұЫҢШЁ Ш§ЫҢЩ…ЩҶЫҢ ШіШ§Щ…Ш§ЩҶЩҮ ШЁШ§Щ„Ш§ Щ…ЫҢвҖҢШұЩҲШҜ. Ш§ЫҢЩҶ Ш¶ШұЫҢШЁ Ш§ЫҢЩ…ЩҶЫҢ ШЁЩҮ ЩӮЫҢЩ…ШӘ ШЁШ§Щ„Ш§ ШұЩҒШӘЩҶ ШҜШұШөШҜ ШұШҜЩ‘ Ш§ЩҒШұШ§ШҜ Ш§ШІ ШұЩҲЫҢ Ш®Ш·Ш§ ШөЩҲШұШӘ Щ…ЫҢвҖҢЪҜЫҢШұШҜ ЩҲ ШЁШ§Ш№Ш« Щ…ЫҢвҖҢШҙЩҲШҜ ШҙШ®ШөЫҢ Ъ©ЩҮ ШЁЩҮ Ш§ЩҲ ШЁШ§ЫҢШҜ Ш§Ш¬Ш§ШІЩҮ Ш№ШЁЩҲШұ ШҜШ§ШҜЩҮ ШҙЩҲШҜ ЪҶЩҶШҜ ШЁШ§Шұ ШұЩ…ШІ Ш®ЩҲШҜ ШұШ§ ШЁШұШ§ЫҢ ШіШ§Щ…Ш§ЩҶЩҮ ШӘЪ©ШұШ§Шұ Ъ©ЩҶШҜ. Щ…Ш§ЩҶЩҶШҜ ШӘЩ…Ш§Щ… ШіШ§Щ…Ш§ЩҶЩҮвҖҢЩҮШ§ЫҢЫҢ ШЁЩҮЫҢЩҶЩҮвҖҢШіШ§ШІЫҢ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЫҢ Щ…Ш®ШӘЩ„ЩҒ ШЁШұШ§ЫҢ ШЁЩҮШӘШұЫҢЩҶ Ш№Щ…Щ„Ъ©ШұШҜ ШіШ§Щ…Ш§ЩҶЩҮ ШҜШұ ШҙШұШ§ЫҢШ· Щ…ЩҲШұШҜ ЩҶЫҢШ§ШІ Щ„Ш§ШІЩ… Ш§ШіШӘ. (ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ Щ…Ш«Ш§Щ„ ШҜШұ ЩҲШұЩҲШҜЫҢ Ш§ШӘШ§ЩӮ Ъ©ЩҶШӘШұЩ„ ЫҢЪ© ЩҶЫҢШұЩҲЪҜШ§ЩҮ ЩҮШіШӘЩҮвҖҢШ§ЫҢ ЩҶЫҢШ§ШІ ШЁЩҮ ШӯЩҒШ§ШёШӘ ШІЫҢШ§ШҜЫҢ ШҜШ§ШұШҜ Ъ©ЩҮ Щ…Щ…Ъ©ЩҶ Ш§ШіШӘ ШҜШұ Щ…ЩҲШұШҜ ШҜШұШЁ ЩҲШұЩҲШҜЫҢ Ъ©ШӘШ§ШЁШ®Ш§ЩҶЩҮ ШҜШ§ЩҶШҙЪҜШ§ЩҮ ЩҶЫҢШ§ШІ ЩҶШЁШ§ШҙШҜ.)