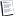
شبکه GRNN
شبكه هاي عصبي GRNN اغلب به عنوان توابع تخمين استفاده ميشوند. كه شامل يك لايه Radial Basis و يك لايه خطي ويژه ميباشد.
شبكه عصبي GRNN كه در زير نشان داده شده است شبيه به شبكه هاي Radial basis ميباشد كه داراي تفاوتهايي در لايه است.
همانطور در شكل بالا مشاهده ميكنيد تابع Nprod يك بردار( n^2 ) شامل s^2مقدار توليد ميكند. كه اين مقادير حاصل ضرب نقطهاي 〖LW〗^2.1 در بردار ورودي a^1 ميباشند. كه همه مقادبر بردار حاصل به دليل جمع مقادير a^1 نرمال است.
لايه اول شبكه GRRN دقيقاً شبيه شبكه RB است كه داراي تعدادي نرون است كه با بردارهاي ورودي/ هدف (p) مقدار دهي ميشود. در لايه اول وزنها با مقدار P’ و بردارb^1 با بردار ستوني كه داراي مقدار spread/0.8326 است مقداردهي اوليه ميشوند كه البته مقدار Spread قابل تغيير است.
در لايه اول وزن هر نرون فاصله برداري بين بردار وزن با بردار ورودي است كه توسط تابع ||dist|| محاسبه ميشود. همچنين نرونهاي ورودي شبكه از طريق بردار ورديهاي وزندار و باياس كه توسط تابع nprod محاسبه ميشود توليد ميشود. نرون هاي خروجي هم همان وروديهاي شبكه هستند كه توسط radbas انتقال داده شدهاند.
در شبكه GRNN اگر بردار ورودي و بردار وزن با هم برابر باشند بردار وزنهاي ورودي صفر خواهد شد و خروجي يك ميگردد. اگر بردار وزن نرونها و بردار ورودي فاصلهشان گسترش پيدا كند وزن نرون هاي وروديها نيز افزايش يافته وخروجي 0.5 خواهد گرديد.
فرض كنيد كه يك بردار ورودي اوليه نزديك به بردار Pi داريم. يكي از بردارهاي ورودي را از ميان جفت بردارهاي هدف و ورودي را براي طراحي وزنهاي لايه اول استفاده ميكنيم. اين ورودي P يك خروجي ai از لايه اول را توليد ميكند كه به يك نزديك باشد. اين خروجي لايه اول ، خروجي در لايه دوم ايجاد ميكند كه به ti نزديك باشد كه اين ti يكي از بردارهاي هدف استفاده شده براي شكل دادن وزن هاي لايه دوم است.
انتخاب مقدار بزرگ براي پارامتر Spread منجر به ايجاد ناحيه وسيعي در اطراف بردار ورودي ميشود جايي كه پاسخهاي نرون هاي لايه اول، خروجيهاي مهمتري را توليد ميكند. اگر پارامتر Spread را كوچك انتخاب نماييم شيب تابع Radial Basis زياد ميشود در نتيجه نرون با بردار وزن نزديك تر به ورودي، نسبت به ساير نرونها، خروجي وسيعتري توليد خواهد كرد .
هرچقدر كه پراكندگي بيشتر باشد شيب توابع Radial Basis صاف تر شده وممكن است چند نرون مختلف به يك بردار ورودي جواب دهند (مقدارشان شبيه هم شود) و شبكه به گونهاي عمل ميكند كه بين بردارهاي هدفي كه طرح بردار وروديشان به بردار ورودي جديد شبيهتر است ميانگين وزندار گيرد. به عبارتي ديگر هر چقدر كه پارامتر spread بزرگتر شود نرونهاي بيشتري در اين ميانگين گرفتن شركت ميكنند و باعث ميشود توابع شبكه شيب شان صافتر و نرمتر گردد.
|