Ш§ЩҶШ¬Щ…ЩҶ ШұШ§ ШҜШұ ЪҜЩҲЪҜЩ„ Щ…ШӯШЁЩҲШЁ Ъ©ЩҶЩҠШҜ :
|
|||||||


| Ш«ШЁШӘ ЩҶШ§Щ… | Ш§ШұШіШ§Щ„ ШҜШ№ЩҲШӘЩҶШ§Щ…ЩҮ ШЁЩҮ ШҜЩҲШіШӘШ§ЩҶ ! | ШұШ§ЩҮЩҶЩ…Ш§ЩҠ ШіШ§ЩҠШӘ | Community | ШӘЩӮЩҲЩҠЩ… | Ш§ШұШіШ§Щ„ЩҮШ§ЩҠ Ш§Щ…ШұЩҲШІ | Ш¬ШіШӘШ¬ЩҲ |
| ШӘШЁЩ„ЩҠШәШ§ШӘ ШіШ§ЩҠШӘ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
  |
|
|
LinkBack | Ш§ШЁШІШ§ШұЩҮШ§ЩҠ ШӘШ§ЩҫЩҠЪ© | ЩҶШӯЩҲЩҮ ЩҶЩ…Ш§ЩҠШҙ |
 Ы°Ы№-ЫұЫ·-ЫұЫіЫёЫё, Ы°Ыұ:ЫіЫ· ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
Ы°Ы№-ЫұЫ·-ЫұЫіЫёЫё, Ы°Ыұ:ЫіЫ· ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#1 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Administrator
 
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш®ШұШҜШ§ШҜ ЫұЫіЫёЫ·
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ-Ъ©ШұШ¬!
ЩҫШіШӘ ЩҮШ§: 3,465
ШӘШҙЩғШұЩҮШ§: 754
16,339 ШӘШҙЩғШұ ШҜШұ 3,127 ЩҫШіШӘ
My Mood:

 |
ЩҫШұШҜШ§ШІШҙ ШөЩҲШӘ
ЩҠЪ©ЩҠ Ш§ШІ ШІЩ…ЩҠЩҶЩҮ ЩҮШ§ЩҠ Щ…ЩҮЩ… ШҜШұ ШіЩҠШіШӘЩ…ЩҮШ§ЩҠ ЩҮЩҲШҙЩ…ЩҶШҜ Ъ©Ш§Щ…ЩҫЩҠЩҲШӘШұЩҠ Щ…ЩҠ ШЁШ§ШҙШҜ. ШЁШ·ЩҲШұ Ъ©Щ„ЩҠ ЩҫШұШҜШ§ШІШҙ ШөЩҲШӘ ШЁЩҮ ШіЩҮ ШҙШ§Ш®ЩҮ ШӘЩӮШіЩҠЩ… Щ…ЩҠ ШҙЩҲШҜ: Ш§Щ„ЩҒ) Ъ©ШҜШЁЩҶШҜЩҠ ШөЩҲШӘ , ШЁ) ШӘЩҲЩ„ЩҠШҜ ШөЩҲШӘ Ш¬) ШӘШҙШ®ЫҢШө ШөЩҲШӘ. Ыұ- ШҜШіШӘЪҜШ§ЩҮ ШҙЩҶЩҲШ§ЫҢЫҢ Ш§ЩҶШіШ§ЩҶ ЩҫШұШҜШ§ШІШҙ ШөЩҲШӘ Щ…ШӯШҜЩҲШҜЩҮвҖҢЩҮШ§ЫҢ ЪҜЩҲЩҶШ§ЪҜЩҲЩҶЫҢ ШұШ§ ШҜШұ ШЁШұ Щ…ЫҢвҖҢЪҜЫҢШұШҜ Ъ©ЩҮ ЩҮЩ…ЩҮ ШЁЩҮ Щ…ЩҶШёЩҲШұ Ш§ШұШ§ШҰЩҮвҖҢЫҢ ШөШҜШ§ ШЁЩҮ ШҙЩҶЩҲЩҶШҜЪҜШ§ЩҶ Ш§ЩҶШіШ§ЩҶЫҢ Ш§ШЁШҜШ§Ш№ ШҙШҜЩҮвҖҢШ§ЩҶШҜ. ШіЩҮ Щ…ШӯШҜЩҲШҜЩҮвҖҢЫҢ ШӘЪ©Ш«ЫҢШұ Щ…ЩҲШіЫҢЩӮЫҢ ШЁШ§ Ъ©ЫҢЩҒЫҢШӘЫҢ ШЁЩҮ Ш®ЩҲШЁЫҢ Ш§ШөЩ„ ЩҮЩ…Ш§ЩҶЩҶШҜ ШўЩҶЪҶЩҮ ШҜШұ ШіЫҢвҖҢШҜЫҢвҖҢЩҮШ§ЫҢ ШөЩҲШӘЫҢ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ ШҢШ§ШұШӘШЁШ§Ш· ШөЩҲШӘЫҢ Ш§ШІ ШұШ§ЩҮ ШҜЩҲШұ Ъ©ЩҮ ЩҶШ§Щ… ШҜЫҢЪҜШұ ШҙШЁЪ©ЩҮвҖҢЫҢ ШӘЩ„ЩҒЩҶЫҢ Ш§ШіШӘ ЩҲ ШҢШӘШұЪ©ЫҢШЁ ШөШӯШЁШӘ Ъ©ЩҮ ШҜШұ ШўЩҶ Ъ©Ш§Щ…ЩҫЫҢЩҲШӘШұЩҮШ§ Ш§Щ„ЪҜЩҲЩҮШ§ЫҢ ШөЩҲШӘЫҢ Ш§ЩҶШіШ§ЩҶ ШұШ§ ШӘЩҲЩ„ЫҢШҜ Ъ©ШұШҜЩҮ ЫҢШ§ ШӘШҙШ®ЫҢШө Щ…ЫҢвҖҢШҜЩҮЩҶШҜ Ш§ШІ ШҜЫҢЪҜШұ ЩӮЩ„Щ…ШұЩҲЩҮШ§ЫҢ ШҜШ§ЩҶШҙ ЩҫШұШҜШ§ШІШҙ ШөЩҲШӘ Щ…ЩҮЩ…вҖҢШӘШұЩҶШҜ. ШЁШ§ ЩҲШ¬ЩҲШҜ Ш§ЫҢЩҶ Ъ©ЩҮ Ш§ЩҮШҜШ§ЩҒ ЩҲ Щ…ШіШ§ШҰЩ„ Ш§ЫҢЩҶ Ъ©Ш§ШұШЁШұШҜЩҮШ§ Щ…ШӘЩҒШ§ЩҲШӘЩҶШҜ ЩҮЩ…ЪҜЫҢ ШҜШұ ЫҢЪ© ЩҶЩӮШ·ЩҮвҖҢЫҢ Щ…ШҙШӘШұЪ© ШЁЩҮ ЩҮЩ… Щ…ЫҢвҖҢШұШіЩҶШҜ ЩҲ ШўЩҶ ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ Ш§ШіШӘ. ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ ЫҢЪ© Ш№Ш¶ЩҲ ШЁЩҮ ЪҜЩҲЩҶЩҮвҖҢШ§ЫҢ ЩҒШІШ§ЫҢЩҶШҜЩҮ ЩҫЫҢЪҶЫҢШҜЩҮ Ш§ШіШӘ. ЩӮШ¶ЫҢЩҮ ЩҲЩӮШӘЫҢ ЩҫЫҢЪҶЫҢШҜЩҮвҖҢШӘШұ Щ…ЫҢвҖҢШҙЩҲШҜ Ъ©ЩҮ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ Ш§ШұШіШ§Щ„ЫҢ Ш§ШІ ШҜЩҲ ЪҜЩҲШҙ ШҜШұ ЫҢЪ© ШҙШЁЪ©ЩҮвҖҢЫҢ ЩҫЫҢЪҶЫҢШҜЩҮвҖҢЫҢ ЪҜЫҢШ¬ Ъ©ЩҶЩҶШҜЩҮ Ъ©ЩҮ ЩҮЩ…Ш§ЩҶШ§ Щ…ШәШІ Ш§ЩҶШіШ§ЩҶ ШЁШ§ШҙШҜ ШЁШ§ ЩҮЩ… ШӘШұЪ©ЫҢШЁ Щ…ЫҢвҖҢШҙЩҲЩҶШҜ. ШЁЩҮ ЫҢШ§ШҜ ШҜШ§ШҙШӘЩҮ ШЁШ§ШҙЫҢЩ… Ъ©ЩҮ ШЁЫҢШ§ЩҶ ЩҒЩҲЩӮ ЫҢЪ© ЪҜШ°Шұ Ъ©Щ„ЫҢ ШЁШұ ЩӮШ¶ЫҢЩҮ Ш§ШіШӘ ЩҲ ШӘШ№ШҜШ§ШҜ ШІЫҢШ§ШҜЫҢ Ш§ШІ ЩҫШҜЫҢШҜЩҮвҖҢЩҮШ§ ЩҲ ШўШ«Ш§Шұ ШҜЩӮЫҢЩӮ Щ…ШұШӘШЁШ· ШЁШ§ ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ ЩҮЩҶЩҲШІ ШЁЩҮ ШҜШұШіШӘЫҢ ШҜШұЪ© ЩҶШҙШҜЩҮвҖҢШ§ЩҶШҜ. ШҙЪ©Щ„ Ыұ ЩӮШіЩ…ШӘ Ш§Ш№ШёЩ… ШіШ§Ш®ШӘШ§ШұЩҮШ§ ЩҲ ЩҫШұШҜШ§ШІШҙЩҮШ§ЫҢЫҢ ШұШ§ Ъ©ЩҮ ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ ШұШ§ ШҜШұ ШЁШұ ШҜШ§ШұЩҶШҜ ШЁЩҮ ШӘШөЩҲЫҢШұ Щ…ЫҢвҖҢЪ©ШҙШҜ. ЪҜЩҲШҙ Ш®Ш§ШұШ¬ЫҢ Ш§ШІ ШҜЩҲ ШЁШ®Шҙ ШӘШҙЪ©ЫҢЩ„ ШҙШҜЩҮ Ш§ШіШӘ: ЩҶШұЩ…ЫҢ ЩҫЩҲШіШӘ ЩӮШ§ШЁЩ„ Щ…ШҙШ§ЩҮШҜЩҮ ЩҲ ШәШ¶ШұЩҲЩҒ Щ…ШӘШөЩ„ ШЁЩҮ Ъ©ЩҶШ§Шұ ШіШұ ЩҲ Ъ©Ш§ЩҶШ§Щ„ ЪҜЩҲШҙ Ъ©ЩҮ Щ„ЩҲЩ„ЩҮвҖҢШ§ЫҢШіШӘ ШЁЩҮ ЩӮШ·Шұ ШӘЩӮШұЫҢШЁЫҢ Ы°.Ыө ШіШ§ЩҶШӘЫҢЩ…ШӘШұ ЩҲ ШӘШ§ ШӯШҜЩҲШҜ Ыі ШіШ§ЩҶШӘЫҢЩ…ШӘШұ ШҜШұ ШҜШ§Ш®Щ„ ШіШұ ЩҒШұЩҲ Щ…ЫҢвҖҢШұЩҲШҜ. Ш§ЫҢЩҶ ШіШ§Ш®ШӘШ§ШұЩҮШ§ ШөШҜШ§ЩҮШ§ЫҢ Щ…ШӯЫҢШ· ШұШ§ ШЁЩҮ ШЁШ®ШҙЩҮШ§ЫҢ ШӯШіШ§Ші ЪҜЩҲШҙ Щ…ЫҢШ§ЩҶЫҢ ЩҲ ЪҜЩҲШҙ ШҜШ§Ш®Щ„ЫҢ Ъ©ЩҮ ШҜШұ ШҜШұЩҲЩҶ Ш§ШіШӘШ®ЩҲШ§ЩҶЩҮШ§ЫҢ Ш¬Щ…Ш¬Щ…ЩҮ Щ…ШӯШ§ЩҒШёШӘ Щ…ЫҢвҖҢШҙЩҲШҜ ШұШ§ЩҮШЁШұЫҢ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ. ШҜШұ Ш§ЩҶШӘЩҮШ§ЫҢ Ъ©Ш§ЩҶШ§Щ„ ЪҜЩҲШҙ ЫҢЪ© ЩҲШұЩӮЩҮвҖҢЫҢ ЩҶШ§ШІЪ© Ш§ШІ ЩҶШіЩҲШ¬ Ъ©ЩҮ ЩҫШұШҜЩҮвҖҢЫҢ ШөЩ…Ш§Ш®Ыұ ЫҢШ§ Ш·ШЁЩ„ ЪҜЩҲШҙ ЩҶШ§Щ…ЫҢШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ Ъ©ШҙЫҢШҜЩҮ ШҙШҜЩҮ Ш§ШіШӘ. Ш§Щ…ЩҲШ§Ш¬ ШөШҜШ§ ШЁШ§ ШЁШұШ®ЩҲШұШҜ ШЁЩҮ ЩҫШұШҜЩҮвҖҢЫҢ ШөЩ…Ш§Ш® ШЁШ§Ш№Ш« Щ„ШұШІШҙ ШўЩҶ Щ…ЫҢвҖҢШҙЩҲЩҶШҜ. ЪҜЩҲШҙ Щ…ЫҢШ§ЩҶЫҢ Щ…Ш¬Щ…ЩҲШ№ЩҮвҖҢШ§ЫҢ Ш§ШІ Ш§ШіШӘШ®ЩҲШ§ЩҶЩҮШ§ЫҢ Ъ©ЩҲЪҶЪ© Ш§ШіШӘ Ъ©ЩҮ Щ„ШұШІШҙ Щ…ШІШЁЩҲШұ ШұШ§ ШЁЩҮ ШӯЩ„ШІЩҲЩҶ ЪҜЩҲШҙЫІ (ЪҜЩҲШҙ ШҜШ§Ш®Щ„ЫҢ) Ш§ЩҶШӘЩӮШ§Щ„ Щ…ЫҢвҖҢШҜЩҮЩҶШҜ ЩҲ ШҜШұ ШўЩҶШ¬Ш§ Ш§ЫҢЩҶ Щ„ШұШІШҙЩҮШ§ ШӘШЁШҜЫҢЩ„ ШЁЩҮ Ш¶ШұШЁЩҮвҖҢЩҮШ§ЫҢ Ш№ШөШЁЫҢ Щ…ЫҢвҖҢЪҜШұШҜЩҶШҜ. ШӯЩ„ШІЩҲЩҶ ЪҜЩҲШҙ ЫҢЪ© Щ„ЩҲЩ„ЩҮвҖҢЫҢ ЩҫШұ Ш§ШІ Щ…Ш§ЫҢШ№ Ш§ШіШӘ Ъ©ЩҮ ШЁЩҮ ШІШӯЩ…ШӘ ЩӮШ·Шұ ШўЩҶ ШЁЩҮ ЫІ Щ…ЫҢЩ„ЫҢЩ…ШӘШұ ЩҲ Ш·ЩҲЩ„ ШўЩҶ ШЁЩҮ Ыі ШіШ§ЩҶШӘЫҢЩ…ШӘШұ Щ…ЫҢвҖҢШұШіШҜ. Ш§ЪҜШұ ЪҶЩҮ ШӯЩ„ШІЩҲЩҶ ЪҜЩҲШҙ ШҜШұ ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыұ ШЁЩҮ ШөЩҲШұШӘ ЫҢЪ© Щ„ЩҲЩ„ЩҮвҖҢЫҢ Щ…ШіШӘЩӮЫҢЩ… ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮ ШҙШҜЩҮ Ш§Щ…Ш§ ШҜШұ ЩҲШ§ЩӮШ№ ШЁЩҮ ШҜЩҲШұ Ш®ЩҲШҜШҙ ЩҮЩ…Ш§ЩҶЩҶШҜ ШөШҜЩҒ ШӯЩ„ШІЩҲЩҶ ЩҫЫҢЪҶ Ш®ЩҲШұШҜЩҮ Ш§ШіШӘ ЩҲ ЩҲШ¬ЩҮ ШӘШіЩ…ЫҢЩҮвҖҢЫҢ ШўЩҶ Ъ©ЩҮ ШұЫҢШҙЩҮ ШҜШұ Ъ©Щ„Щ…ЩҮвҖҢШ§ЫҢ ЫҢЩҲЩҶШ§ЩҶЫҢ ШЁЩҮ Щ…Ш№ЩҶШ§ЫҢ ШӯЩ„ШІЩҲЩҶ ШҜШ§ШұШҜ ЩҶЫҢШІ Ш§ЫҢЩҶ ЩҲШ§ЩӮШ№ЫҢШӘ Ш§ШіШӘ. ЩҲЩӮШӘЫҢ ЫҢЪ© Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ШіШ№ЫҢ ШҜШ§ШұШҜ Ш§ШІ ЩҮЩҲШ§ ЩҲШ§ШұШҜ Щ…Ш§ЫҢШ№ ШҙЩҲШҜ ШӘЩҶЩҮШ§ Ъ©ШіШұ Ъ©ЩҲЪҶЪ©ЫҢ Ш§ШІ ШўЩҶ Ш§ШІ ШЁЫҢЩҶ ШҜЩҲ Щ…ШӯЫҢШ· Ш№ШЁЩҲШұ Щ…ЫҢвҖҢЪ©ЩҶШҜ ЩҲ ШЁШ§ЩӮЫҢЩ…Ш§ЩҶШҜЩҮвҖҢЫҢ Ш§ЩҶШұЪҳЫҢ ШўЩҶ ШЁШ§ШІШӘШ§ШЁЫҢШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ШҜЩ„ЫҢЩ„ Ш§ЫҢЩҶ Ш§Щ…Шұ Щ…ЩӮШ§ЩҲЩ…ШӘ Щ…Ъ©Ш§ЩҶЫҢЪ©ЫҢ ЩҫШ§ЫҢЫҢЩҶ ЩҮЩҲШ§ (ЩҶШ§ШҙЫҢ Ш§ШІ ЩҫШ§ЫҢЫҢЩҶ ШЁЩҲШҜЩҶ Щ…ЫҢШІШ§ЩҶ ЩҒШҙШ§Шұ ШөЩҲШӘЫҢ ЩҲ ШіШұШ№ШӘ ШЁШ§Щ„Ш§ЫҢ Ш°ШұШ§ШӘ ЩҮЩҲШ§ Ъ©ЩҮ ШЁЩҮ ЩҶЩҲШЁЩҮвҖҢЫҢ Ш®ЩҲШҜ Ш§ШІ ЪҶЪҜШ§Щ„ЫҢ ЩҫШ§ЫҢЫҢЩҶ ЩҲ ШӘШұШ§Ъ©Щ…вҖҢЩҫШ°ЫҢШұЫҢ ШЁШ§Щ„Ш§ЫҢ ШўЩҶЩҮШ§ ЩҶШҙШЈШӘ Щ…ЫҢвҖҢЪҜЫҢШұШҜ) ШҜШұ ШЁШұШ§ШЁШұ Щ…ЩӮШ§ЩҲЩ…ШӘ Щ…Ъ©Ш§ЩҶЫҢЪ©ЫҢ ШЁШ§Щ„Ш§ЫҢ Щ…Ш§ЫҢШ№ Ш§ШіШӘ. ШЁЩҮ Ш№ШЁШ§ШұШӘ ШіШ§ШҜЩҮвҖҢШӘШұ ШҜЩ„ЫҢЩ„ Ш§ЫҢЩҶ Ш§Щ…Шұ Щ…ШҙШ§ШЁЩҮ ШҜЩ„ЫҢЩ„ Ш§ЫҢЩҶ Щ…ЩҲШ¶ЩҲШ№ Ш§ШіШӘ Ъ©ЩҮ ШЁШұШ§ЫҢ Ш§ЫҢШ¬Ш§ШҜ Щ…ЩҲШ¬ ШЁШ§ ШҜШіШӘ ШҜШұ ШҜШұЩҲЩҶ ШўШЁ ШЁЩҮ ШӘЩ„Ш§Шҙ ШЁЫҢШҙШӘШұЫҢ ШЁЩҮ ЩҶШіШЁШӘ Ш§ЩҶШ¬Ш§Щ… Ш§ЫҢЩҶ Ъ©Ш§Шұ ШҜШұ ЩҮЩҲШ§ ЩҶЫҢШ§ШІЩ…ЩҶШҜЫҢЩ…. ШӘЩҒШ§ЩҲШӘ Щ…ЩҲШ¬ЩҲШҜ ШЁШ§Ш№Ш« ШЁШ§ШІШӘШ§ШЁШҙ ЩӮШіЩ…ШӘ Ш§Ш№ШёЩ… ШөЩҲШӘ ШҜШұ Щ…ШұШІ ЩҮЩҲШ§/Щ…Ш§ЫҢШ№ Щ…ЫҢвҖҢЪҜШұШҜШҜ. ЪҜЩҲШҙ Щ…ЫҢШ§ЩҶЫҢ ЫҢЪ© ШҙШЁЪ©ЩҮвҖҢЫҢ ШӘШ·ШЁЫҢЩӮ Щ…ЩӮШ§ЩҲЩ…ШӘЫі Ш§ШіШӘ Ъ©ЩҮ Ъ©ШіШұ Ш§ЩҶШұЪҳЫҢ ШөЩҲШӘЫҢ ЩҲШ§ШұШҜ ШҙШҜЩҮ ШЁЩҮ Щ…Ш§ЫҢШ№ ЪҜЩҲШҙ ШҜШ§Ш®Щ„ЫҢ ШұШ§ ШІЫҢШ§ШҜ Щ…ЫҢвҖҢЪ©ЩҶШҜ. ШЁШұШ§ЫҢ ЩҶЩ…ЩҲЩҶЩҮ Щ…Ш§ЩҮЫҢ ЩҫШұШҜЩҮвҖҢЫҢ ШөЩ…Ш§Ш® ЫҢШ§ ЪҜЩҲШҙ Щ…ЫҢШ§ЩҶЫҢ ЩҶШҜШ§ШұШҜ ЪҶШұШ§ Ъ©ЩҮ ЩҶЫҢШ§ШІЫҢ ШЁЩҮ ШҙЩҶЫҢШҜЩҶ ШҜШұ ЩҮЩҲШ§ ЩҶШҜШ§ШұШҜ. ШӘШәЫҢЫҢШұ ШҙШҜШӘШҢ ШЁЫҢШҙШӘШұ ЩҶШ§ШҙЫҢ Ш§ШІ ШӘЩҒШ§ЩҲШӘ Щ…ШіШ§ШӯШӘ ЩҫШұШҜЩҮвҖҢЫҢ ШөЩ…Ш§Ш® (Ъ©ЩҮ ШөШҜШ§ ШұШ§ Ш§ШІ ЩҮЩҲШ§ ШҜШұЫҢШ§ЩҒШӘ Щ…ЫҢвҖҢЪ©ЩҶШҜ) ЩҲ ШҜШұЫҢЪҶЩҮ ШЁЫҢШ¶ЩҲЫҢЫҙ (Ъ©ЩҮ Щ…Ш·Ш§ШЁЩӮ ШҙЪ©Щ„ ЫұШөШҜШ§ ШұШ§ ШЁЩҮ ШҜШ§Ш®Щ„ Щ…Ш§ЫҢШ№ Ш§ЩҶШӘЩӮШ§Щ„ Щ…ЫҢвҖҢШҜЩҮШҜ) Щ…ЫҢвҖҢШЁШ§ШҙШҜ. Щ…ШіШ§ШӯШӘ ЩҫШұШҜЩҮвҖҢЫҢ ШөЩ…Ш§Ш® ШӯШҜЩҲШҜШ§ЩӢ Ы¶Ы° Щ…ЫҢЩ„ЫҢЩ…ШӘШұ Щ…ШұШЁШ№ Ш§ШіШӘ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ ШҜШұЫҢЪҶЩҮвҖҢЫҢ ШЁЫҢШ¶ЩҲЫҢ ШӯШҜЩҲШҜШ§ЩӢ Ыҙ Щ…ЫҢЩ„ЫҢЩ…ШӘШұ Щ…ШұШЁШ№ Щ…ШіШ§ШӯШӘ ШҜШ§ШұШҜ. Ш§ШІ ШўЩҶШ¬Ш§ Ъ©ЩҮ ЩҒШҙШ§Шұ ШЁШұШ§ШЁШұ Ш§ШіШӘ ШЁШ§ ЩҶШіШЁШӘ ЩҶЫҢШұЩҲ ШЁЩҮ Щ…ШіШ§ШӯШӘШҢ Ш§ЫҢЩҶ ШӘЩҒШ§ЩҲШӘ Щ…ШіШ§ШӯШӘ ЩҒШҙШ§Шұ Щ…ЩҲШ¬ ШөШҜШ§ ШұШ§ ШӯШҜЩҲШҜШ§ЩӢ ЫұЫө ШЁШұШ§ШЁШұ Ш§ЩҒШІШ§ЫҢШҙ Щ…ЫҢвҖҢШҜЩҮШҜ. ШҜШұ ШҜШ§Ш®Щ„ ШӯЩ„ШІЩҲЩҶ ЪҜЩҲШҙ ЩҫШұШҜЩҮвҖҢЫҢ Ш§ШөЩ„ЫҢЫө ЩӮШұШ§Шұ ШҜШ§ШұШҜ Ъ©ЩҮ ШіШ§Ш®ШӘШ§ШұЫҢ ШұШ§ ШЁШұШ§ЫҢ ЫұЫІЫ°Ы°Ы° ШіЩ„ЩҲЩ„ ШӯШіЫҢ Ъ©ЩҮ ШҙЪ©Щ„вҖҢШҜЩҮЩҶШҜЩҮвҖҢЫҢ Ш№ШөШЁ ШӯЩ„ШІЩҲЩҶЫҢ Ш§ШіШӘ Ш§ЫҢШ¬Ш§ШҜ Щ…ЫҢвҖҢЪ©ЩҶШҜ. ЩҫШұШҜЩҮвҖҢЫҢ Ш§ШөЩ„ЫҢ ШҜШұ ЩҶШІШҜЫҢЪ©ЫҢ ШҜШұЫҢЪҶЩҮвҖҢЫҢ ШЁЫҢШ¶ЩҲЫҢ ШЁШіЫҢШ§Шұ ШіЩҒШӘ Ш§ШіШӘ ЩҲ ШҜШұ Ш§ЩҶШӘЩҮШ§ЫҢ ШҜЫҢЪҜШұ Ш§ЩҶШ№Ш·Ш§ЩҒвҖҢЩҫШ°ЫҢШұвҖҢШӘШұ Ш§ШіШӘ Ъ©ЩҮ Ш§ЫҢЩҶ Ш§Щ…Шұ ШЁЩҮ Ш§ЫҢЩҶ Ш№Ш¶ЩҲ Ъ©Щ…Ъ© Щ…ЫҢвҖҢЪ©ЩҶШҜ ШӘШ§ ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ШӘШӯЩ„ЫҢЩ„ЪҜШұ Ш·ЫҢЩҒ ЩҒШұЪ©Ш§ЩҶШіЫҢ Ш№Щ…Щ„ Ъ©ЩҶШҜ. ЩҲЩӮШӘЫҢ ЩҫШұШҜЩҮвҖҢЫҢ Ш§ШөЩ„ЫҢ ШҜШұ Щ…Ш№ШұШ¶ ЫҢЪ© ШіЫҢЪҜЩҶШ§Щ„ ШЁШ§ ЩҒШұЪ©Ш§ЩҶШі ШЁШ§Щ„Ш§ ЩӮШұШ§Шұ Щ…ЫҢвҖҢЪҜЫҢШұШҜ ШҜШұ ЩӮШіЩ…ШӘ ШіЩҒШӘвҖҢШӘШұ Ш·ЩҶЫҢЩҶ Щ…ЫҢвҖҢШ§ЩҶШҜШ§ШІШҜ Ъ©ЩҮ ШіШЁШЁ ШӘШӯШұЫҢЪ© ШіЩ„ЩҲЩ„ЩҮШ§ЫҢ Ш№ШөШЁЫҢ ЩҶШІШҜЫҢЪ© ШЁЩҮ ШҜШұЫҢЪҶЩҮвҖҢЫҢ ШЁЫҢШ¶ЩҲЫҢ Щ…ЫҢвҖҢЪҜШұШҜШҜ. ШЁЩҮ ЩҮЩ…ЫҢЩҶ ШӘШұШӘЫҢШЁ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ЫҢ ЩҫШ§ЫҢЫҢЩҶ Щ…ЩҲШ¬ШЁ ШӘШӯШұЫҢЪ© Ш§ЩҶШӘЩҮШ§ЫҢ ШҜЩҲШұШӘШұ ЩҫШұШҜЩҮвҖҢЫҢ Ш§ШөЩ„ЫҢ Щ…ЫҢвҖҢШҙЩҲЩҶШҜ. Ш§ЫҢЩҶ Ш§Щ…Шұ Щ…ЩҲШ¬ШЁ ЩҫШ§ШіШ®ЪҜЩҲЫҢЫҢ ШұШҙШӘЩҮвҖҢЩҮШ§ЫҢ Ш®Ш§Шө Ш№ШөШЁ ШӯЩ„ШІЩҲЩҶЫҢ ШҜШұ ШЁШұШ§ШЁШұ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ЫҢ Ш®Ш§Шө Щ…ЫҢвҖҢЪҜШұШҜШҜ. Ш§ЫҢЩҶ ШіШ§ШІЩҲЪ©Ш§Шұ Ш§ШөЩ„ Щ…Ъ©Ш§ЩҶЫ¶ ЩҶШ§Щ…ЫҢШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ ЩҲ ШҜШұ ШіШұШ§ШіШұ Щ…ШіЫҢШұ ШЁЩҮ ШіЩ…ШӘ Щ…ШәШІ ШӯЩҒШё Щ…ЫҢвҖҢШҙЩҲШҜ. Ш·ШұШӯ Ъ©ШҜЪҜШ°Ш§ШұЫҢ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ШҜЫҢЪҜШұЫҢ ЩҶЫҢШІ ШҜШұ ШҙЩҶЩҲШ§ЫҢЫҢ Ш§ЩҶШіШ§ЩҶ ШЁЩҮ Ъ©Ш§Шұ Щ…ЫҢвҖҢШұЩҲШҜ Ъ©ЩҮ Ш§ШөЩ„ ШұЪҜШЁШ§ШұЫ· ЩҶШ§Щ…ЫҢШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ШіЩ„ЩҲЩ„ЩҮШ§ЫҢ Ш№ШөШЁЫҢ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ШұШ§ ШЁШ§ ШӘЩҲЩ„ЫҢШҜ ЩҫШ§Щ„ШіЩҮШ§ЫҢ Ш§Щ„Ъ©ШӘШұЫҢЪ©ЫҢ Ъ©ЩҲЪҶЪ©ЫҢ Ъ©ЩҮ ЩҫШӘШ§ЩҶШіЫҢЩ„ Ъ©ЩҶШҙЫё ЩҶШ§Щ…ЫҢШҜЩҮ Щ…ЫҢвҖҢШҙЩҲЩҶШҜ Ш§ЩҶШӘЩӮШ§Щ„ Щ…ЫҢвҖҢШҜЩҮШҜ. ЫҢЪ© ШіЩ„ЩҲЩ„ Ш№ШөШЁЫҢ ЩҲШ§ЩӮШ№ ШЁШұ ЩҫШұШҜЩҮвҖҢЫҢ ЩҫШ§ЫҢЫҢЩҶЫҢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ШөЩҲШӘЫҢ ШұШ§ ШЁШ§ ШӘЩҲЩ„ЫҢШҜ ЫҢЪ© ЩҫШӘШ§ЩҶШіЫҢЩ„ Ъ©ЩҶШҙ ШҜШұ ЩҫШ§ШіШ® ЩҮШұ ШіЫҢЪ©Щ„ Щ„ШұШІШҙ Ъ©ШҜЪҜШ°Ш§ШұЫҢ Ъ©ЩҶШҜ. ШЁШұШ§ЫҢ ЩҶЩ…ЩҲЩҶЩҮ ЫҢЪ© Щ…ЩҲШ¬ ШөШҜШ§ЫҢ ЫІЫ°Ы° ЩҮШұШӘШІЫҢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ШӘЩҲШіШ· ЫҢЪ© ЩҶЩҲШұЩҲЩҶ Ш§ЫҢШ¬Ш§ШҜ Ъ©ЩҶЩҶШҜЩҮвҖҢЫҢ ЫІЫ°Ы° ЩҫШӘШ§ЩҶШіЫҢЩ„ Ъ©ЩҶШҙ ШҜШұ Ш«Ш§ЩҶЫҢЩҮ ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮ ШҙЩҲШҜ. ШҜШұ ЩҮШұ ШөЩҲШұШӘ Ш§ЫҢЩҶ ШұЩҲШҙ ШӘЩҶЩҮШ§ ШҜШұ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ЫҢ ШІЫҢШұ ШӯШҜЩҲШҜШ§ЩӢ ЫөЫ°Ы° ЩҮШұШӘШІ вҖ“ ШЁШ§Щ„Ш§ШӘШұЫҢЩҶ ШіШұШ№ШӘ Щ…Щ…Ъ©ЩҶ ШӘЩҲЩ„ЫҢШҜ ЩҫШӘШ§ЩҶШіЫҢЩ„ Ъ©ЩҶШҙ ШҜШұ ЩҶЩҲШұЩҲЩҶЩҮШ§ вҖ“ ШЁЩҮ Ъ©Ш§Шұ Щ…ЫҢвҖҢШўЫҢШҜ. ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ ШЁШұШ§ЫҢ ШәЩ„ШЁЩҮ ШЁШұ Ш§ЫҢЩҶ Щ…ШҙЪ©Щ„ ШЁЩҮ ЩҶЩҲШұЩҲЩҶЩҮШ§ Ш§Ш¬Ш§ШІЩҮ Щ…ЫҢвҖҢШҜЩҮШҜ Ъ©ЩҮ ШЁШұШ§ЫҢ Ш§ЩҶШ¬Ш§Щ… Ш§ЫҢЩҶ Ъ©Ш§Шұ ШҜШіШӘЩҮвҖҢШ¬Щ…Ш№ЫҢ Ш№Щ…Щ„ Ъ©ЩҶЩҶШҜ. ШЁШұШ§ЫҢ ЩҶЩ…ЩҲЩҶЩҮ ЫҢЪ© ШөШҜШ§ЫҢ ЫіЫ°Ы°Ы° ЩҮШұШӘШІЫҢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ШӘЩҲШіШ· ШҜЩҮ ШіЩ„ЩҲЩ„ Ш№ШөШЁЫҢ Ъ©ЩҮ ЩҮШұ Ъ©ШҜШ§Щ… ЫіЫ°Ы° Ш¶ШұШЁЩҮ ШҜШұ Ш«Ш§ЩҶЫҢЩҮ Ш№Щ„Ш§Щ…ШӘ Щ…ЫҢвҖҢШҜЩҮЩҶШҜ ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮ ШҙЩҲШҜ. Ш§ЫҢЩҶ ЩҫШҜЫҢШҜЩҮ ШЁШ§ШІЩҮвҖҢЫҢ Ъ©Ш§ШұШ§ЫҢЫҢ Ш§ШөЩ„ ШұЪҜШЁШ§Шұ ШұШ§ ШӘШ§ Ыҙ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ЪҜШіШӘШұШҙ Щ…ЫҢвҖҢШҜЩҮШҜ Ъ©ЩҮ ШЁШ§Щ„Ш§ШӘШұ Ш§ШІ ШЁШ§ШІЩҮвҖҢЫҢ Ш№Щ…Щ„ЫҢШ§ШӘЫҢ Ш§ШөЩ„ Щ…Ъ©Ш§ЩҶ Щ…ЫҢвҖҢШЁШ§ШҙШҜ.  ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыұ- ШӘЩҲШ¶ЫҢШӯШ§ШӘ Щ…ШұШЁЩҲШ· ШЁЩҮ ШҙЪ©Щ„: ЩҶЩ…ЩҲШҜШ§Шұ Ъ©Ш§ШұЪ©ШұШҜЫҢ ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ. ЪҜЩҲШҙ Ш®Ш§ШұШ¬ЫҢ Ш§Щ…ЩҲШ§Ш¬ ШөЩҲШӘЫҢ ШұШ§ Ш§ШІ Щ…ШӯЫҢШ· Щ…ЫҢвҖҢЪҜЫҢШұШҜ ЩҲ ШўЩҶЩҮШ§ ШұШ§ ШЁЩҮ ШіЩҲЫҢ ЩҫШұШҜЩҮвҖҢЫҢ ШөЩ…Ш§Ш® (Ш·ШЁЩ„ ЪҜЩҲШҙ) Ъ©ЩҮ ЩҲШұЩӮЩҮвҖҢЫҢ ЩҶШ§ШІЪ©ЫҢ Ш§ШІ ШЁШ§ЩҒШӘ Ш§ШіШӘ ЩҲ ЩҮЩ…Ш§ЩҮЩҶЪҜ ШЁШ§ ШҙЪ©Щ„ Щ…ЩҲШ¬ ЩҮЩҲШ§ Щ…ЫҢвҖҢЩ„ШұШІШҜ ШұШ§ЩҮШЁШұЫҢ Щ…ЫҢвҖҢЪ©ЩҶШҜ. Ш§ШіШӘШ®ЩҲШ§ЩҶЩҮШ§ЫҢ ЪҜЩҲШҙ Щ…ЫҢШ§ЩҶЫҢ (Ш§ШіШӘШ®ЩҲШ§ЩҶЩҮШ§ЫҢ ЪҶЪ©ШҙЫҢШҢ ШіЩҶШҜШ§ЩҶЫҢ ЩҲ ШұЪ©Ш§ШЁЫҢ) Ш§ЫҢЩҶ Щ„ШұШІШҙЩҮШ§ ШұШ§ ШЁЩҮ ШҜШұЫҢЪҶЩҮвҖҢЫҢ ШЁЫҢШ¶ЩҲЫҢ Ъ©ЩҮ ЩҫШұШҜЩҮвҖҢШ§ЫҢ Щ…ЩҶШ№Ш·ЩҒ ЩҲШ§ЩӮШ№ ШҜШұ ШӯЩ„ШІЩҲЩҶ ЪҜЩҲШҙ ЩҫШұ Ш§ШІ Щ…Ш§ЫҢШ№ Ш§ШіШӘ Ш§ЩҶШӘЩӮШ§Щ„ Щ…ЫҢвҖҢШҜЩҮЩҶШҜ. ШҜШұ ШҜШ§Ш®Щ„ ШӯЩ„ШІЩҲЩҶ ЪҜЩҲШҙ ЩҫШұШҜЩҮвҖҢЫҢ Ш§ШөЩ„ЫҢ ЩӮШұШ§Шұ ШҜШ§ШұШҜ Ъ©ЩҮ Ш§ЫҢШ¬Ш§ШҜ Ъ©ЩҶЩҶШҜЩҮвҖҢЫҢ ШіШ§Ш®ШӘШ§ШұЫҢ ШЁШұШ§ЫҢ ЫұЫІЫ°Ы°Ы° ШіЩ„ЩҲЩ„ Ш№ШөШЁЫҢ ШҙЪ©Щ„вҖҢШҜЩҮЩҶШҜЩҮвҖҢЫҢ Ш№ШөШЁ ШӯЩ„ШІЩҲЩҶ ЪҜЩҲШҙ Ш§ШіШӘ. ШЁШіШӘЩҮ ШЁЩҮ ШіЩҒШӘЫҢ Щ…ШӘШәЫҢШұ ЩҫШұШҜЩҮвҖҢЫҢ ЩҫШ§ЫҢЫҢЩҶЫҢШҢ ЩҮШұ ШіЩ„ЩҲЩ„ ЩҒЩӮШ· ШЁЩҮ ШЁШ§ШІЩҮвҖҢЫҢ Ъ©ЩҲЪҶЪ©ЫҢ Ш§ШІ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ЫҢ ШөШҜШ§ ЩҫШ§ШіШ® Щ…ЫҢвҖҢШҜЩҮШҜ Ъ©ЩҮ Ш§ЫҢЩҶ ЩҫШҜЫҢШҜЩҮ ЪҜЩҲШҙ ШұШ§ ШӘШЁШҜЫҢЩ„ ШЁЩҮ ЫҢЪ© ШӘШӯЩ„ЫҢЩ„ЪҜШұ Ш·ЫҢЩҒ ЩҒШұЪ©Ш§ЩҶШіЫҢ Щ…ЫҢвҖҢЩҶЩ…Ш§ЫҢШҜ. ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ ЫІ ШұШ§ШЁШ·ЩҮвҖҢЫҢ ШЁЫҢЩҶ ШҙШҜШӘ ШөШҜШ§ ЩҲ ШЁЩ„ЩҶШҜЫҢ Щ…ШҙШ§ЩҮШҜЩҮ ШҙШҜЩҮ ШұШ§ ЩҶШҙШ§ЩҶ Щ…ЫҢвҖҢШҜЩҮШҜ. ШәШ§Щ„ШЁШ§ЩӢ ШҙШҜШӘ ШөШҜШ§ ШұШ§ ШЁШ§ ЫҢЪ© Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ Щ„ЪҜШ§ШұЫҢШӘЩ…ЫҢ Ъ©ЩҮ ШҜШіЫҢвҖҢШЁЩ„ Ш§Ші.ЩҫЫҢ.Ш§Щ„.Ы№ (ШіШ·Шӯ ШӘЩҲШ§ЩҶ ШөШҜШ§) ЩҶШ§Щ…ЫҢШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ ЩҶШҙШ§ЩҶ Щ…ЫҢвҖҢШҜЩҮЩҶШҜ. ШҜШұ Ш§ЫҢЩҶ Щ…Ш№ЫҢШ§Шұ Ы° ШҜШіЫҢвҖҢШЁЩ„ Ш§Ші.ЩҫЫҢ.Ш§Щ„ Щ…ЩҲШ¬ ШөШҜШ§ЫҢЫҢ ШЁШ§ ЩӮШҜШұШӘ ШҜЩҮ ШЁЩҮ ШӘЩҲШ§ЩҶ Щ…ЩҶЩҒЫҢ ШҙШ§ЩҶШІШҜЩҮ ЩҲШ§ШӘ ШЁШұ ШіШ§ЩҶШӘЫҢЩ…ШӘШұ Щ…ШұШЁШ№ Ш§ШіШӘ Ъ©ЩҮ ШӯШҜЩҲШҜШ§ЩӢ Ш¶Ш№ЫҢЩҒвҖҢШӘШұЫҢЩҶ ШөШҜШ§ЫҢ ЩӮШ§ШЁЩ„ ШӘШҙШ®ЫҢШө ШӘЩҲШіШ· ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ Ш§ШіШӘ. ШөШӯШЁШӘ Щ…Ш№Щ…ЩҲЩ„ЫҢ ШӯШҜЩҲШҜШ§ЩӢ Ы¶Ы° ШҜШіЫҢвҖҢШЁЩ„ Ш§Ші.ЩҫЫҢ.Ш§Щ„ Ш§ШіШӘ ЩҲ ШөШҜШ§ЫҢЫҢ ШЁШ§ ШҙШҜШӘ ЫұЫҙЫ° ШҜШіЫҢвҖҢШЁЩ„ Ш§Ші.ЩҫЫҢ.Ш§ЫҢ ШЁШұШ§ЫҢ ЪҜЩҲШҙ ШҜШұШҜЩҶШ§Ъ© ЩҲ ШІЫҢШ§ЩҶвҖҢШўЩҲШұ Ш§ШіШӘ  ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ ЫІ - ЩҲШ§ШӯШҜЩҮШ§ЫҢ ШҙШҜШӘ ШөШҜШ§. ШҙШҜШӘ ШөШҜШ§ ШЁЩҮ ШөЩҲШұШӘ ШӘЩҲШ§ЩҶ ШЁШұ ЩҲШ§ШӯШҜ Щ…ШіШ§ШӯШӘ ШӘШ№ШұЫҢЩҒ Щ…ЫҢвҖҢШҙЩҲШҜ (Щ…Ш«Щ„Ш§ЩҸ ЩҲШ§ШӘ ШЁШұ ШіШ§ЩҶШӘЫҢЩ…ШӘШұ Щ…ШұШЁШ№) ЫҢШ§ ШЁЩҮ ШөЩҲШұШӘ Щ…Ш№Щ…ЩҲЩ„вҖҢШӘШұ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ЫҢЪ© Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ Щ„ЪҜШ§ШұЫҢШӘЩ…ЫҢ Ъ©ЩҮ ШҜШіЫҢвҖҢШЁЩ„ Ш§Ші.ЩҫЫҢ.Ш§Щ„ Ш®ЩҲШ§ЩҶШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ЩҮЩ…ЪҶЩҶШ§ЩҶ Ъ©ЩҮ Ш§ЫҢЩҶ Ш¬ШҜЩҲЩ„ ЩҶШҙШ§ЩҶ Щ…ЫҢвҖҢШҜЩҮШҜ ЩӮЩҲЩҮвҖҢЫҢ ШҙЩҶЩҲШ§ЫҢЫҢ Ш§ЩҶШіШ§ЩҶ ШЁЫҢШҙШӘШұ ШЁЩҮ ШөШҜШ§ЩҮШ§ЫҢ ШЁЫҢЩҶ ЫұЪ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШӘШ§ Ыҙ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШӯШіШ§Ші Ш§ШіШӘ. Ш§Ш®ШӘЩ„Ш§ЩҒ ШЁЩ„ЩҶШҜШӘШұЫҢЩҶ ЩҲ Ш¶Ш№ЫҢЩҒвҖҢШӘШұЫҢЩҶ ШөШҜШ§ЩҮШ§ЫҢЫҢ Ъ©ЩҮ Ш§ЩҶШіШ§ЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ШЁШҙЩҶЩҲШҜ ЫұЫІЫ° ШҜШіЫҢвҖҢШЁЩ„ Ш§ШіШӘ Ъ©ЩҮ Ш§ШІ Щ„ШӯШ§Шё ШҜШ§Щ…ЩҶЩҮ Щ…Ш№Ш§ШҜЩ„ ШЁШ§ШІЩҮвҖҢШ§ЫҢ ШӯШҜЩҲШҜ ЫҢЪ© Щ…ЫҢЩ„ЫҢЩҲЩҶ Ш§ШіШӘ. ШҙЩҶЩҲЩҶШҜЩҮ ШӘШәЫҢЫҢШұ ШЁЩ„ЩҶШҜЫҢ ШөШҜШ§ ШұШ§ ЩҲЩӮШӘЫҢ ШөШҜШ§ ШӯШҜЩҲШҜ Ыұ ШҜШіЫҢвҖҢШЁЩ„ (ЫұЫІ% ШҜШұ ШҜШ§Щ…ЩҶЩҮ) ШӘШәЫҢЫҢШұ Ъ©ЩҶШҜ ШӘШҙШ®ЫҢШө Щ…ЫҢвҖҢШҜЩҮШҜ ШЁЩҮ Ш№ШЁШ§ШұШӘ ШҜЫҢЪҜШұ ШӘЩҶЩҮШ§ ЫұЫІЫ° ШіШ·Шӯ ШЁЩ„ЩҶШҜЫҢ ШөШҜШ§ Ш§ШІ Щ…Щ„Ш§ЫҢЩ…вҖҢШӘШұЫҢЩҶ ЩҶШ¬ЩҲШ§ ШӘШ§ ШЁЩ„ЩҶШҜШӘШұЫҢЩҶ ШӘЩҶШҜШұ ЩӮШ§ШЁЩ„ ШӘШҙШ®ЫҢШө Ш§ШіШӘ. ШӯШіШ§ШіЫҢШӘ ЪҜЩҲШҙ ШўЩҶЩӮШҜШұ Ш¬Ш§Щ„ШЁ ШӘЩҲШ¬ЩҮ Ш§ШіШӘ Ъ©ЩҮ ЩҮЩҶЪҜШ§Щ… ШҙЩҶЫҢШҜЩҶ ШЁЩҮ Ш¶Ш№ЫҢЩҒвҖҢШӘШұЫҢЩҶ ШөШҜШ§ЩҮШ§ ЩҫШұШҜЩҮвҖҢЫҢ ШөЩ…Ш§Ш® ШЁЩҮ Ш§ЩҶШҜШ§ШІЩҮвҖҢШ§ЫҢ Ъ©Щ…ШӘШұ Ш§ШІ ЩӮШ·Шұ ЫҢЪ© Щ…Щ„Ъ©ЩҲЩ„ ШЁЩҮ Щ„ШұШІШҙ ШҜШұвҖҢЩ…ЫҢвҖҢШўЫҢШҜ! Ш§ШӯШіШ§Ші ШЁЩ„ЩҶШҜЫҢ ШөШҜШ§ ШЁШ§ ШӘЩҲШ§ЩҶ ШөШҜШ§ ШұШ§ШЁШ·ЩҮвҖҢЫҢ ШӘЩҲШ§ЩҶЫҢ ШЁШ§ ЩҶЩ…Ш§ЫҢ Ыұ/Ыі ШҜШ§ШұШҜ. ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҶЩ…ЩҲЩҶЩҮ Ш§ЪҜШұ ШҙЩ…Ш§ ШӘЩҲШ§ЩҶ ШөШҜШ§ ШұШ§ ШҜЩҮ ШЁШұШ§ШЁШұ Ъ©ЩҶЫҢШҜ ШҙЩҶЩҲЩҶШҜЪҜШ§ЩҶ ШўЩҶ ШөШҜШ§ ШҜЩҲ ШЁШұШ§ШЁШұ ШҙШҜЩҶ ШЁЩ„ЩҶШҜЫҢ ШөШҜШ§ ШұШ§ Ш§ШӯШіШ§Ші ЩҲ ЪҜШІШ§ШұШҙ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ. Ш§ЫҢЩҶ Щ…ШіШЈЩ„ЩҮ ЫҢЪ© Щ…ШҙЪ©Щ„ ШЁШІШұЪҜ ШЁШұШ§ЫҢ ШӯШ°ЩҒ ШөШҜШ§ЩҮШ§ЫҢ Щ…ШӯЫҢШ·ЫҢ ЩҶШ§Ш®ЩҲШ§ШіШӘЩҮ ШЁЩҮ ЩҲШ¬ЩҲШҜ Щ…ЫҢвҖҢШўЩҲШұШҜ. ШЁШұШ§ЫҢ ЩҶЩ…ЩҲЩҶЩҮ ЩҒШұШ¶ Ъ©ЩҶЫҢШҜ Ъ©ЩҮ ШҙЩ…Ш§ Ы№Ы№% ШҜЫҢЩҲШ§Шұ ШұШ§ ШЁШ§ Ш№Ш§ЫҢЩӮ ШөЩҲШӘЫҢ ЩҫЩҲШҙШ§ЩҶШҜЩҮвҖҢШ§ЫҢШҜ ЩҲ ШӘЩҶЩҮШ§ Ыұ% Ъ©ЩҮ Щ…ШұШЁЩҲШ· ШЁЩҮ ШҜШұЩҮШ§ШҢ ЪҜЩҲШҙЩҮвҖҢЩҮШ§ШҢ Щ…ЩҶШ§ЩҒШ° ЩҲвҖҰ ЩҮШіШӘЩҶШҜ ШЁШ§ЩӮЫҢ Щ…Ш§ЩҶШҜЩҮвҖҢШ§ЩҶШҜ. ШЁШ§ ЩҲШ¬ЩҲШҜ ШўЩҶ Ъ©ЩҮ ШӘЩҲШ§ЩҶ ШөШҜШ§ ШӘШ§ Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ Ыұ% Щ…ЩӮШҜШ§Шұ Ш§ЩҲЩ„ЫҢЩҮвҖҢЫҢ ШўЩҶ Ъ©Ш§ШіШӘЩҮ ШҙШҜЩҮ ШЁЩ„ЩҶШҜЫҢ ШөШҜШ§ ШӘЩҶЩҮШ§ ШЁЩҮ Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ ЫІЫ°% Ъ©Ш§ЩҮШҙ ЩҫЫҢШҜШ§ Ъ©ШұШҜЩҮвҖҢШ§ШіШӘ. ШЁШ§ШІЩҮвҖҢЫҢ ШҙЩҶЫҢШҜШ§ШұЫҢ Ш§ЩҶШіШ§ЩҶ ШЁЫҢЩҶ ЫІЫ° ЩҮШұШӘШІ ШӘШ§ ЫІЫ° Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШҜШұ ЩҶШёШұ ЪҜШұЩҒШӘЩҮ Щ…ЫҢвҖҢШҙЩҲШҜШҢ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ ШЁЫҢШҙШӘШұ ШөШҜШ§ЩҮШ§ЫҢ ЩӮШ§ШЁЩ„ ШӯШі ШҜШұ ШЁШ§ШІЩҮвҖҢЫҢ Ыұ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШӘШ§ Ыҙ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ЩӮШұШ§Шұ ШҜШ§ШұЩҶШҜ. ШЁШұШ§ЫҢ ЩҶЩ…ЩҲЩҶЩҮ ШҙЩҶЩҲЩҶШҜЪҜШ§ЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶЩҶШҜ ШөШҜШ§ЫҢЫҢ ШЁЩҮ Щ…ЫҢШІШ§ЩҶ ШөЩҒШұ ШҜШіЫҢвҖҢШЁЩ„ ШұШ§ ШҜШұ ЩҒШұЪ©Ш§ЩҶШі Ыі Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШЁШҙЩҶЩҲЩҶШҜ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ ШЁШұШ§ЫҢ ШҙЩҶЫҢШҜЩҶ ЫҢЪ© ШөШҜШ§ЫҢ ЫұЫ°Ы° ЩҮШұШӘШІЫҢ ШӯШҜШ§ЩӮЩ„ Щ…ЩӮШҜШ§Шұ ШўЩҶ ШЁШ§ЫҢШҜ ЫҙЫ° ШҜШіЫҢвҖҢШЁЩ„ ШЁШ§ШҙШҜ. ШҙЩҶЩҲЩҶШҜЪҜШ§ЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶЩҶШҜ ШЁЪҜЩҲЫҢЩҶШҜ Ъ©ЩҮ ШҜЩҲ ШөШҜШ§ Щ…ШӘЩҒШ§ЩҲШӘЩҶШҜ Ш§ЪҜШұ ЩҒШұЪ©Ш§ЩҶШі ШўЩҶЩҮШ§ ШЁЫҢШҙ Ш§ШІ ШӯШҜЩҲШҜ Ы°.Ыі% ШҜШұ Ыі Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ Щ…ШӘЩҒШ§ЩҲШӘ ШЁШ§ШҙШҜ. ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҶЩ…ЩҲЩҶЩҮ Ъ©Щ„ЫҢШҜЩҮШ§ЫҢ Ъ©ЩҶШ§Шұ ЩҮЩ… ШҜШұ ЩҫЫҢШ§ЩҶЩҲ ШЁЩҮ Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ ШӯШҜЩҲШҜ Ы¶% ШӘЩҒШ§ЩҲШӘ ЩҒШұЪ©Ш§ЩҶШі ШҜШ§ШұЩҶШҜ. Щ…ЩҮЩ…вҖҢШӘШұЫҢЩҶ Щ…ШІЫҢШӘ ШҜШ§ШҙШӘЩҶ ШҜЩҲ ЪҜЩҲШҙ ШӘШҙШ®ЫҢШө Ш¬ЩҮШӘ ШөШҜШ§ШіШӘ. ШҙЩҶЩҲЩҶШҜЪҜШ§ЩҶ Ш§ЩҶШіШ§ЩҶЫҢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶЩҶШҜ ШӘЩҒШ§ЩҲШӘ ШЁЫҢЩҶ ШҜЩҲ Щ…ЩҶШЁШ№ ШөШҜШ§ ШұШ§ Ъ©ЩҮ ЩҒШ§ШөЩ„ЩҮвҖҢШ§ЫҢ ШЁЩҮ Ъ©Щ…ЫҢ Ыі ШҜШұШ¬ЩҮ ШҜШ§ШұЩҶШҜ (ШӯШҜЩҲШҜШ§ЩӢ ШЁШұШ§ШЁШұ ШЁШ§ Ш№ШұШ¶ ЫҢЪ© Ш§ЩҶШіШ§ЩҶ ШҜШұ ЩҒШ§ШөЩ„ЩҮвҖҢЫҢ ШҜЩҮ Щ…ШӘШұЫҢ) ШӘШҙШ®ЫҢШө ШҜЩҮЩҶШҜ. Ш§ЫҢЩҶ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ Ш¬ЩҮШӘЫҢ ШЁЩҮ ШҜЩҲ ШұЩҲШҙ Ш¬ШҜШ§ЪҜШ§ЩҶЩҮ ШЁЩҮ ШҜШіШӘ Щ…ЫҢвҖҢШўЫҢЩҶШҜ. Ш§ЩҲЩ„Ш§ЩӢ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ЫҢ ШӯШҜЩҲШҜШ§ЩӢ ШЁШ§Щ„Ш§ЫҢ Ыұ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШЁЩҮ ШҙШҜШӘ ШІЫҢШұ ШіШ§ЫҢЩҮвҖҢЫҢ ШіШұ ЩӮШұШ§Шұ Щ…ЫҢвҖҢЪҜЫҢШұЩҶШҜ. ШЁЩҮ ШЁЫҢШ§ЩҶ ШҜЫҢЪҜШұ ЪҜЩҲШҙЫҢ Ъ©ЩҮ ШЁЩҮ Щ…ЩҶШЁШ№ ЩҶШІШҜЫҢЪ©вҖҢШӘШұ Ш§ШіШӘ ШіЫҢЪҜЩҶШ§Щ„ ЩӮЩҲЫҢ ШӘШұЫҢ ШұШ§ ШЁЩҮ ЩҶШіШЁШӘ ЪҜЩҲШҙЫҢ Ъ©ЩҮ ШҜШұ Ш¬ЩҮШӘ Щ…Ш®Ш§Щ„ЩҒ ШҜШ§ШұШҜ ШҜШұЫҢШ§ЩҒШӘ Щ…ЫҢвҖҢЪ©ЩҶШҜ. ШұЩҲШҙ ШҜЫҢЪҜШұ ШӘШҙШ®ЫҢШө Ш¬ЩҮШӘ ШўЩҶ Ш§ШіШӘ Ъ©ЩҮ ЪҜЩҲШҙ ШҜЩҲШұШӘШұ ШЁЩҮ Ш®Ш§Ш·Шұ ЩҒШ§ШөЩ„ЩҮвҖҢЫҢ ШЁЫҢШҙШӘШұШҙ Ш§ШІ Щ…ЩҶШЁШ№ ШөШҜШ§ ШұШ§ Ъ©Щ…ЫҢ ШҜЫҢШұШӘШұ Ш§ШІ ЪҜЩҲШҙ ЩҶШІШҜЫҢЪ©вҖҢШӘШұ ШҜШұЫҢШ§ЩҒШӘ Щ…ЫҢвҖҢЪ©ЩҶШҜ. ШЁЩҮ ЩҲШ§ШіШ·ЩҮвҖҢЫҢ Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ Щ…Ш№Щ…ЩҲЩ„ ШіШұ (ШӯШҜЩҲШҜШ§ЩӢ ЫІЫІ ШіШ§ЩҶШӘЫҢЩ…ШӘШұ) ЩҲ ШіШұШ№ШӘ ШөЩҲШӘ (ШӯШҜЩҲШҜ ЫіЫҙЫ° Щ…ШӘШұ ШҜШұ Ш«Ш§ЩҶЫҢЩҮ) ШӘЩҒШ§ЩҲШӘвҖҢЪҜШ°Ш§ШұЫҢ ШІШ§ЩҲЫҢЩҮвҖҢШ§ЫҢ ШіЩҮ ШҜШұШ¬ЩҮ ШҜЩӮШӘ ШІЩ…Ш§ЩҶЫҢ ШӯШҜЩҲШҜ ЫіЫ° Щ…ЫҢЪ©ШұЩҲШ«Ш§ЩҶЫҢЩҮ ЩҶЫҢШ§ШІ ШҜШ§ШұШҜ. ЪҶЩҲЩҶ Ш§ЫҢЩҶ ЩҒШ§ШөЩ„ЩҮвҖҢЫҢ ШІЩ…Ш§ЩҶЫҢ ЩҶЫҢШ§ШІЩ…ЩҶШҜ Ш§ШөЩ„ ШұЪҜШЁШ§Шұ Ш§ШіШӘ Ш§ЫҢЩҶ ШұЩҲШҙ Ш¬ЩҮШӘвҖҢЫҢШ§ШЁЫҢ ШЁШұШ§ЫҢ ШөШҜШ§ЩҮШ§ЫҢ ШҜШ§ШұШ§ЫҢ ЩҒШұЪ©Ш§ЩҶШі Ъ©Щ…вҖҢШӘШұ Ш§ШІ ШӯШҜЩҲШҜ Ыұ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШЁЩҮ Ъ©Ш§Шұ Щ…ЫҢвҖҢШұЩҲШҜ. ШҜШұ ШӯШ§Щ„ЫҢ Ъ©ЩҮ ЩӮЩҲЩҮвҖҢЫҢ ШҙЩҶЩҲШ§ЫҢЫҢ Ш§ЩҶШіШ§ЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ Ш¬ЩҮШӘ ШөШҜШ§ ШұШ§ ШӘШҙШ®ЫҢШө ШҜЩҮШҜ ШҜШұ ЩҶШҙШ®ЫҢШө ЩҒШ§ШөЩ„ЩҮвҖҢЫҢ Щ…ЩҶШЁШ№ ШөШҜШ§ Щ…ШҙЪ©Щ„ ШҜШ§ШұШҜ. Ш§ЫҢЩҶ Ш§Щ…Шұ ШЁШҜШ§ЩҶ Ш№Щ„ШӘ Ш§ШіШӘ Ъ©ЩҮ ЪҶЫҢШІЩҮШ§ЫҢ Ъ©Щ…ЫҢ ШҜШұ Щ…ЩҲШ¬ ШөШҜШ§ ЩҲШ¬ЩҲШҜ ШҜШ§ШұШҜ Ъ©ЩҮ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ Ш§ЫҢЩҶ ЪҜЩҲЩҶЩҮ ШұШ§ ШҜШұ Ш§Ш®ШӘЫҢШ§Шұ ШЁЪҜШ°Ш§ШұШҜ. ШҙЩҶЩҲШ§ЫҢЫҢ Ш§ЩҶШіШ§ЩҶ ШЁЩҮ ШөЩҲШұШӘ Ш¶Ш№ЫҢЩҒЫҢ ШҜШұ Щ…ЫҢвҖҢЫҢШ§ШЁШҜ Ъ©ЩҮ Щ…ЩҶШ§ШЁШ№ ШөШҜШ§ЩҮШ§ЫҢ ШЁШ§ ЩҒШұЪ©Ш§ЩҶШі ШЁШ§Щ„Ш§ ЩҶШІШҜЫҢЪ©ЩҶШҜ ЩҲ ШөШҜШ§ЩҮШ§ЫҢ ШЁШ§ ЩҒШұЪ©Ш§ЩҶШі ЩҫШ§ЫҢЫҢЩҶ Ш§ШІ ЩҒШ§ШөЩ„ЩҮвҖҢЫҢ ШҜЩҲШұШӘШұЫҢ ЩҫШ®Шҙ Щ…ЫҢвҖҢШҙЩҲЩҶШҜ. Ш§ЫҢЩҶ ШЁЩҮ ШўЩҶ ШҜЩ„ЫҢЩ„ Ш§ШіШӘ Ъ©ЩҮ ШөШҜШ§ЩҮШ§ ШҜШұ ЩҒШ§ШөЩ„ЩҮвҖҢЩҮШ§ЫҢ ШҜЩҲШұ Ш§ШІ Щ…ЫҢШІШ§ЩҶ ЩҒШұЪ©Ш§ЩҶШіШҙШ§ЩҶ Ъ©Ш§ШіШӘЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ЩҫЪҳЩҲШ§Ъ© ШұЩҲШҙ Ш¶Ш№ЫҢЩҒ ШҜЫҢЪҜШұЫҢ ШЁШұШ§ЫҢ ШӘШҙШ®ЫҢШө ЩҒШ§ШөЩ„ЩҮ Ш§ШіШӘ ЩҲ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШўЩҶ Щ…Ш«Щ„Ш§ЩӢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ Ш§ШЁШ№Ш§ШҜ ЫҢЪ© Ш§ШӘШ§ЩӮ ШұШ§ ШӯШҜШі ШІШҜ. ШЁШұШ§ЫҢ ЩҶЩ…ЩҲЩҶЩҮ ШөШҜШ§ЩҮШ§ЫҢ Щ…ЩҲШ¬ЩҲШҜ ШҜШұ ЫҢЪ© ШӘШ§Щ„Ш§Шұ ШЁШІШұЪҜ ЩҫЪҳЩҲШ§Ъ©ЩҮШ§ЫҢЫҢ ШЁШ§ ЩҲЩӮЩҒЩҮвҖҢЫҢ ЫұЫ°Ы° Щ…ЫҢЩ„ЫҢ Ш«Ш§ЩҶЫҢЩҮ ШҜШ§ШұЩҶШҜШҢ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ ШЁШұШ§ЫҢ ЫҢЪ© ШҜЩҒШӘШұ Ъ©Ш§Шұ Ъ©ЩҲЪҶЪ© Ш§ЫҢЩҶ Щ…ЩӮШҜШ§Шұ ЫұЫ° Щ…ЫҢЩ„ЫҢ Ш«Ш§ЩҶЫҢЩҮ Ш§ШіШӘ. ШЁШ№Ш¶ЫҢ Ш§ШІ Щ…ЩҲШ¬ЩҲШҜШ§ШӘ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШҜШіШӘЪҜШ§ЩҮ Ш·ШЁЫҢШ№ЫҢ ШӘШҙШ®ЫҢШө ЩҒШ§ШөЩ„ЩҮвҖҢЫҢ ШөЩҲШӘЫҢЫұЫ° Щ…ШіШЈЩ„ЩҮвҖҢЫҢ ЩҒШ§ШөЩ„ЩҮвҖҢЫҢШ§ШЁЫҢ ШұШ§ ШӯЩ„ Ъ©ШұШҜЩҮвҖҢШ§ЩҶШҜ. Щ…Ш«Щ„Ш§ЩӢ Ш®ЩҒШ§ШҙЩҮШ§ ЩҲ ШҜЩ„ЩҒЫҢЩҶЩҮШ§ ШөШҜШ§ЩҮШ§ЫҢЫҢ Щ…Ш«Щ„ ШӘЫҢЪ© ЩҲ Ш¬ЫҢШә ШӘЩҲЩ„ЫҢШҜ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ Ъ©ЩҮ Ш§ШІ ШіЩҲЫҢ Ш§ШҙЫҢШ§ШЎ ЩҶШІШҜЫҢЪ© ШЁШ§ШІШӘШ§ШЁЫҢШҜЩҮ Щ…ЫҢвҖҢШҙЩҲЩҶШҜ. ШЁШ§ Ш§ЩҶШҜШ§ШІЩҮвҖҢЪҜЫҢШұЫҢ Щ…ЫҢШІШ§ЩҶ ЩҲЩӮЩҒЩҮвҖҢЫҢ ШЁШ§ШІШӘШ§ШЁ Ш§ЫҢЩҶ ШөШҜШ§вҖҢЩҮШ§ Ш§ЫҢЩҶ Ш¬Ш§ЩҶЩҲШұШ§ЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶЩҶШҜ ШЁШ§ ШҜЩӮШӘ ЫұШіШ§ЩҶШӘЫҢЩ…ШӘШұ Ш§ШҙЫҢШ§ШЎ ШұШ§ Щ…Ъ©Ш§ЩҶЫҢШ§ШЁЫҢ Ъ©ЩҶЩҶШҜ. ШӘШ¬ШұШЁЫҢШ§ШӘ ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮвҖҢШ§ЩҶШҜ Ъ©ЩҮ ШЁШ№Ш¶ЫҢ Ш§ЩҶШіШ§ЩҶЩҮШ§ ШЁЩҮ Ш®ШөЩҲШө ЩҶШ§ШЁЫҢЩҶШ§ЫҢШ§ЩҶ ШӘШ§ ШӯШҜ Ъ©Щ…ЫҢ Ш§ШІ ШұЩҲШҙ Щ…Ъ©Ш§ЩҶЫҢШ§ШЁЫҢ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ЩҫЪҳЩҲШ§Ъ© Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ. ЫІ- ЩҲЫҢЪҳЪҜЫҢЩҮШ§ЫҢ Ш§Щ…ЩҲШ§Ш¬ ШөЩҲШӘЫҢ ШәШ§Щ„ШЁШ§ЩӢ ШЁШұШ§ЫҢ ШҜШұЪ© ЫҢЪ© ШөЩҲШӘ ЩҫЫҢЩҲШіШӘЩҮ Щ…Ш«Щ„ ЩҶШӘ ЫҢЪ© Ш§ШЁШІШ§Шұ Щ…ЩҲШіЫҢЩӮЫҢШ§ЫҢЫҢ ШіЩҮ ШЁШ®Шҙ Щ…Ш¬ШІШ§ ШұШ§ ШЁШ§ЫҢШҜ ШӘШҙШ®ЫҢШө ШҜШ§ШҜ: ШЁЩ„ЩҶШҜЫҢ ШөШҜШ§ШҢ ШІЫҢШұЫҢ ЫҢШ§ ШЁЩ…ЫҢ ШөШҜШ§ (ЩҫЫҢЪҶЫұЫұ) ЩҲ Ш·ЩҶЫҢЩҶ ШөШҜШ§ЫұЫІ. ШЁЩ„ЩҶШҜЫҢ ЩҮЩ…Ш§ЩҶЪҜЩҲЩҶЩҮ Ъ©ЩҮ ЩӮШЁЩ„Ш§ЩӢ ШӘЩҲШ¶ЫҢШӯ ШҜШ§ШҜЩҮ ШҙШҜ Щ…Ш№ЫҢШ§ШұЫҢ ШЁШұШ§ЫҢ ШҙШҜШӘ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ Ш§ШіШӘ. ЩҫЫҢЪҶШҢ ЩҒШұЪ©Ш§ЩҶШі Ш¬ШІШЎ Ш§ШөЩ„ЫҢ ШөШҜШ§ вҖ“ ЩҒШұЪ©Ш§ЩҶШіЫҢ ШӘЪ©ШұШ§Шұ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ШӘЩҲШіШ· Ш®ЩҲШҜШҙ вҖ“ Щ…ЫҢвҖҢШЁШ§ШҙШҜ. Ш·ЩҶЫҢЩҶ ШөШҜШ§ Ш§ШІ ШҜЩҲ Ш¬ШІШЎ ЩӮШЁЩ„ЫҢ ЩҫЫҢЪҶЫҢШҜЩҮвҖҢШӘШұ Ш§ШіШӘ ЩҲ ШЁШ§ ШӘШ№ЫҢЫҢЩҶ Щ…ШӯШӘЩҲШ§ЫҢ ЩҮЩ…ШіШ§ШІЫұЫі ШөШҜШ§ ШӘШ№ЫҢЫҢЩҶ Щ…ЫҢвҖҢЪҜШұШҜШҜ. ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыі ШҜЩҲ Щ…ЩҲШ¬ ШұШ§ Ъ©ЩҮ ЩҮШұ ШҜЩҲ Ш§ШІ Ш¬Щ…Ш№ ЫҢЪ© Щ…ЩҲШ¬ ШіЫҢЩҶЩҲШіЫҢ ЫҢЪ© Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІЫҢ ШЁШ§ ШҜШ§Щ…ЩҶЩҮвҖҢЫҢ ЫҢЪ© ЩҲ ЫҢЪ© Щ…ЩҲШ¬ ШіЫҢЩҶЩҲШіЫҢ ШіЩҮ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІЫҢ ШЁШ§ ШҜШ§Щ…ЩҶЩҮвҖҢЫҢ ЫҢЪ© ШҜЩҲЩ… ШЁЩҮ ЩҲШ¬ЩҲШҜ ШўЩ…ШҜЩҮвҖҢШ§ЩҶШҜ ЩҶШҙШ§ЩҶ Щ…ЫҢвҖҢШҜЩҮШҜ. ШӘЩҒШ§ЩҲШӘ ШўЩҶЩҮШ§ ШҜШұ ШўЩҶ Ш§ШіШӘ Ъ©ЩҮ ШҜШұ ШҙЪ©Щ„ b Ш¬ШІШЎ ШЁШ§ ЩҒШұЪ©Ш§ЩҶШі ШЁШ§Щ„Ш§ШӘШұ Ш§ШЁШӘШҜШ§ Щ…Ш№Ъ©ЩҲШі ШҙШҜЩҮ ЩҲ ШіЩҫШі ШЁШ§ Щ…ЩҲШ¬ ШҜЩҲЩ… Ш¬Щ…Ш№ ШҙШҜЩҮ Ш§ШіШӘ. Ш№Щ„ЫҢвҖҢШұШәЩ… Щ…ЩҲШ¬ЩҮШ§ЫҢ ШҜШұ ШҜШ§Щ…ЩҶЩҮвҖҢЫҢ ШІЩ…Ш§ЩҶ ШЁШіЫҢШ§Шұ Щ…ШӘЩҒШ§ЩҲШӘ Ш§ЫҢЩҶ ШҜЩҲ ШөЩҲШӘ ЫҢЪ©ШіШ§ЩҶ ШЁЩҮ ЩҶШёШұ Щ…ЫҢвҖҢШұШіЩҶШҜ. Ш§ЫҢЩҶ ШЁЩҮ Ш®Ш§Ш·Шұ ШўЩҶ Ш§ШіШӘ Ъ©ЩҮ ШҙЩҶЩҲШ§ЫҢЫҢ Ш§ЩҶШіШ§ЩҶ ШЁШұ Ш§ШіШ§Ші ШҜШ§Щ…ЩҶЩҮвҖҢЫҢ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ШіШӘ ЩҲ ЩҶШіШЁШӘ ШЁЩҮ ЩҒШ§ШІ ШўЩҶЩҮШ§ ШЁШіЫҢШ§Шұ ШәЫҢШұ ШӯШіШ§Ші Ш§ШіШӘ. ШҙЪ©Щ„ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ШҜШұ ШҜШ§Щ…ЩҶЩҮвҖҢЫҢ ШІЩ…Ш§ЩҶ ЩҒЩӮШ· ШЁЩҮ ШөЩҲШұШӘ ШәЫҢШұ Щ…ШіШӘЩӮЫҢЩ… ШЁШ§ ШҙЩҶЩҲШ§ЫҢЫҢ ШұШ§ШЁШ·ЩҮ ШҜШ§ШұШҜ ЩҲ Щ…Ш№Щ…ЩҲЩ„Ш§ЩҸ ШҜШұ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШөЩҲШӘЫҢ ШҜШұ ЩҶШёШұ ЪҜШұЩҒШӘЩҮ ЩҶЩ…ЫҢвҖҢШҙЩҲШҜ. Ш№ШҜЩ… ШӯШіШ§ШіЫҢШӘ ЪҜЩҲШҙ ШЁЩҮ ЩҒШ§ШІ ШөШҜШ§ ШЁШ§ ШӘЩҲШ¬ЩҮ ШЁЩҮ ШұЩҲШҙ ЩҫШ®Шҙ ШҙШҜЩҶ ШўЩҶ ШҜШұ Щ…ШӯЫҢШ· ЩӮШ§ШЁЩ„ ШҜШұЪ© Ш§ШіШӘ. ЩҒШұШ¶ Ъ©ЩҶЫҢШҜ Ъ©ЩҮ ШҙЩ…Ш§ ШҜШұ ЫҢЪ© Ш§ШӘШ§ЩӮ ШЁЩҮ ШөШӯШЁШӘЩҮШ§ЫҢ ЩҒШұШҜЫҢ ЪҜЩҲШҙ Щ…ЫҢвҖҢШҜЩҮЫҢШҜ. ШЁЫҢШҙШӘШұ ШөШҜШ§ЩҮШ§ЫҢЫҢ Ъ©ЩҮ ЪҜЩҲШҙ ШҙЩ…Ш§ ШҜШұЫҢШ§ЩҒШӘ Щ…ЫҢвҖҢЪ©ЩҶШҜ ШӯШ§ШөЩ„ ШЁШ§ШІШӘШ§ШЁ ШөШҜШ§ЫҢ Ш§ШөЩ„ЫҢ Ш§ШІ ШҜЫҢЩҲШ§ШұЩҮШ§ШҢ ШіЩӮЩҒ ЩҲ Ъ©ЩҒ Ш§ШӘШ§ЩӮ Ш§ШіШӘ. Ш§ШІ ШўЩҶШ¬Ш§ Ъ©ЩҮ Ш§ЩҶШӘШҙШ§Шұ ШөШҜШ§ ШЁШіШӘЪҜЫҢ ШЁЩҮ ЩҒШұЪ©Ш§ЩҶШі ШўЩҶ ШҜШ§ШұШҜ ЩҲ Щ…ЫҢШұШ§ЫҢЫҢ ШҢШЁШ§ШІШӘШ§ШЁ ЩҲ Щ…ЩӮШ§ЩҲЩ…ШӘ ШҜШұ ШЁШұШ§ШЁШұ ШөШҜШ§ ШЁШұ ШұЩҲЫҢ ШўЩҶ ШӘШЈШ«ЫҢШұЪҜШ°Ш§Шұ Ш§ШіШӘ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ЫҢ Щ…ШӘЩҒШ§ЩҲШӘЫҢ Ш§ШІ Щ…ШіЫҢШұЩҮШ§ЫҢ Щ…ШӘЩҒШ§ЩҲШӘ ШЁЩҮ ЪҜЩҲШҙ Щ…ЫҢвҖҢШұШіШҜ. Ш§ЫҢЩҶ ШЁЩҮ Ш§ЫҢЩҶ Щ…Ш№ЩҶЫҢ Ш§ШіШӘ Ъ©ЩҮ ЩҲЩӮШӘЫҢ ШҙЩ…Ш§ Ш¬Ш§ЫҢ Ш®ЩҲШҜ ШұШ§ ШҜШұ Ш§ШӘШ§ЩӮ Ш№ЩҲШ¶ Щ…ЫҢвҖҢЪ©ЩҶЫҢШҜ ЩҒШ§ШІ ЩҮШұ ЫҢЪ© Ш§ШІ ЩҒШұЪ©Ш§ЩҶШіЩҮШ§ ШӘШәЫҢЫҢШұ Щ…ЫҢвҖҢЪ©ЩҶШҜ. ЪҶЩҲЩҶ ЪҜЩҲШҙ Ш§ЫҢЩҶ ШӘШәЫҢЫҢШұ ЩҒШ§ШІЩҮШ§ ШұШ§ ЩҶШ§ШҜЫҢШҜЩҮ Щ…ЫҢвҖҢШ§ЩҶЪҜШ§ШұШҜ ШЁШ§ ЩҲШ¬ЩҲШҜ ШӘШәЫҢЫҢШұ Щ…Ъ©Ш§ЩҶ ШҙЩ…Ш§ ШӘШәЫҢЫҢШұЫҢ ШҜШұ ШөШҜШ§ЫҢ ШҙШ®Шө ШөШӯШЁШӘ Ъ©ЩҶЩҶШҜЩҮ Ш§ШӯШіШ§Ші ЩҶЩ…ЫҢвҖҢЪ©ЩҶЫҢШҜ. Ш§ШІ ШҜЫҢШҜЪҜШ§ЩҮ ЩҒЫҢШІЫҢЪ©ЫҢ ЩҒШ§ШІ ЫҢЪ© ШіЫҢЪҜЩҶШ§Щ„ ШөШҜШ§ ШҜШұ ЩҮЩҶЪҜШ§Щ… ЩҫШ®Шҙ ШҜШұ ЫҢЪ© Щ…ШӯЫҢШ· ЩҫЫҢЪҶЫҢШҜЩҮ ШЁЩҮ ШөЩҲШұШӘ ШӘШөШ§ШҜЩҒЫҢ ШӘШәЫҢЫҢШұ Щ…ЫҢвҖҢЪ©ЩҶШҜ. Ш§ШІ Ш·ШұЩҒ ШҜЫҢЪҜШұ ЪҜЩҲШҙ ШЁЩҮ ЩҒШ§ШІ ШөШҜШ§ ШәЫҢШұ ШӯШіШ§Ші Ш§ШіШӘ ШІЫҢШұШ§ Ш§ЫҢЩҶ Ш¬ШІШЎ ШҜШ§ШұШ§ЫҢ Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ЩӮШ§ШЁЩ„ Ш§ШіШӘЩҒШ§ШҜЩҮвҖҢЫҢ ШЁШіЫҢШ§Шұ Ъ©Щ…ЫҢ Щ…ЫҢвҖҢШЁШ§ШҙШҜ  ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыі вҖ“ ШӘШҙШ®ЫҢШө ЩҒШ§ШІ ШӘЩҲШіШ· ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ. ЪҜЩҲШҙ Ш§ЩҶШіШ§ЩҶ ЩҶШіШЁШӘ ШЁЩҮ ЩҒШ§ШІ ЩҶШіШЁЫҢ ШіЫҢЩҶЩҲШіЫҢЩҮШ§ЫҢ Щ…ШұЪ©ШЁ ШЁШіЫҢШ§Шұ ШәЫҢШұ ШӯШіШ§Ші Ш§ШіШӘ. ШЁШұШ§ЫҢ ЩҶЩ…ЩҲЩҶЩҮ Ш§ЫҢЩҶ ШҜЩҲ Щ…ЩҲШ¬ ЫҢЪ©ШіШ§ЩҶ ШЁЩҮ ЩҶШёШұ Ш®ЩҲШ§ЩҮЩҶШҜ ШұШіЫҢШҜШҢ ШІЫҢШұ ШҜШ§Щ…ЩҶЩҮвҖҢЫҢ Ш§Ш¬ШІШ§ШЎ ШўЩҶЩҮШ§ ЫҢЪ©ШіШ§ЩҶ Ш§ШіШӘ Ш§ЪҜШұ ЪҶЩҮ ЩҒШ§ШІ ЩҶШіШЁЫҢ ШўЩҶЩҮШ§ Щ…ШӘЩҒШ§ЩҲШӘ Ш§ШіШӘ. ШҜШұ ШӯШ§Щ„ШӘ Ъ©Щ„ЫҢ ЩҶЩ…ЫҢвҖҢШӘЩҲШ§ЩҶ ЪҜЩҒШӘ Ъ©ЩҮ ЪҜЩҲШҙ ЩҶШіШЁШӘ ШЁЩҮ ЩҒШ§ШІ Ъ©Ш§Щ…Щ„Ш§ЩӢ ЩҶШ§ШҙЩҶЩҲШ§ШіШӘ. ЪҶШұШ§ Ъ©ЩҮ ШӘШәЫҢЫҢШұ ЩҒШ§ШІ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ШЁШ§Ш№Ш« ШӘШәЫҢЫҢШұ ШўШұШ§ЫҢШҙ ШІЩ…Ш§ЩҶЫҢ ЫҢЪ© ШіЫҢЪҜЩҶШ§Щ„ ШөЩҲШӘЫҢ ШҙЩҲШҜ. Ш§Щ…Ш§ ЪҶЩҶЫҢЩҶ Ш§Щ…ШұЫҢ ЫҢЪ© ЩҫШҜЫҢШҜЩҮвҖҢЫҢ ЩҶШ§ШҜШұ Ш§ШіШӘ Ъ©ЩҮ ШҜШұ Щ…ШӯЫҢШ·ЩҮШ§ЫҢ ШҙЩҶЫҢШҜШ§ШұЫҢ Ш·ШЁЫҢШ№ЫҢ Ш§ШӘЩҒШ§ЩӮ ЩҶЩ…ЫҢвҖҢШ§ЩҒШӘШҜ. ЩҒШұШ¶ Ъ©ЩҶЫҢШҜ Ш§ШІ ЫҢЪ© ЩҶЩҲШ§ШІЩҶШҜЩҮвҖҢЫҢ ЩҲЫҢЩҲЩ„ЩҲЩҶ Ш®ЩҲШ§ШіШӘЩҮвҖҢШ§ЫҢЩ… ЩҶШӘЫҢ ШұШ§ ШЁЩҶЩҲШ§ШІШҜ. ЩҲЩӮШӘЫҢ Ъ©ЩҮ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ Ш§ЫҢШ¬Ш§ШҜ ШҙШҜЩҮ ШЁШұ ШұЩҲЫҢ Ш§ШіЫҢЩ„ЩҲШіЪ©ЩҲЩҫ ЩҶШҙШ§ЩҶ ШҜШ§ШҜЩҮ ШҙЩҲШҜ ЫҢЪ© Щ…ЩҲШ¬ ШҜЩҶШҜШ§ЩҶЩҮвҖҢШ§ШұЩҮвҖҢШ§ЫҢ Щ…Ш§ЩҶЩҶШҜ ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыҙ (a) Щ…ШҙШ§ЩҮШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыҙ (b) ЩҶШҙШ§ЩҶ Щ…ЫҢвҖҢШҜЩҮШҜ Ъ©ЩҮ Ш§ЫҢЩҶ ШөЩҲШӘ ЪҶЪҜЩҲЩҶЩҮ ШӘЩҲШіШ· ЪҜЩҲШҙ ШҜШұЫҢШ§ЩҒШӘ Щ…ЫҢвҖҢШҙЩҲШҜ. ЪҜЩҲШҙ ЫҢЪ© ЩҒШұЪ©Ш§ЩҶШі Ш§ШіШ§ШіЫҢ (ШҜШұ Щ…Ш«Ш§Щ„ ШҙЪ©Щ„ ЫІЫІЫ° ЩҮШұШӘШІ) ШұШ§ ЩҲ ЩҮЩ…ШіШ§ШІЩҮШ§ЫҢЫҢ ШұШ§ ШҜШұ ЫҙЫҙЫ°ШҢ Ы¶Ы¶Ы°ШҢ ЫёЫёЫ° ЩҲвҖҰ ЩҮШұШӘШІ ШҜШұЫҢШ§ЩҒШӘ Щ…ЫҢвҖҢЪ©ЩҶШҜ. Ш§ЪҜШұ Ш§ЫҢЩҶ ЩҶШӘ ШЁШұ ШұЩҲЫҢ Ш§ШЁШІШ§Шұ ШҜЫҢЪҜШұЫҢ ЩҶЩҲШ§Ш®ШӘЩҮ ШҙЩҲШҜ ЪҜЩҲШҙ ЩҮЩҶЩҲШІ ЩҮЩ… ЩҮЩ…Ш§ЩҶ ЫІЫІЫ° ЩҮШұШӘШІ (ЩҮЩ…Ш§ЩҶ ЩҒШұЪ©Ш§ЩҶШі Ш§ШіШ§ШіЫҢ) ШұШ§ ШҜШұЫҢШ§ЩҒШӘ Щ…ЫҢвҖҢЪ©ЩҶШҜ. ЩҲ Ш§ШІ Ш§ЫҢЩҶ Щ„ШӯШ§Шё ШҜЩҲ ШөЩҲШӘ Щ…ШҙШ§ШЁЩҮЩҶШҜ Ъ©ЩҮ ЪҜЩҒШӘЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ Ш§ЫҢЩҶ ШҜЩҲ ШөЩҲШӘ ЩҫЫҢЪҶ ЫҢЪ©ШіШ§ЩҶЫҢ ШҜШ§ШұЩҶШҜ ЩҲЩ„ЫҢ ЪҶЩҲЩҶ ШҜШ§Щ…ЩҶЩҮвҖҢЫҢ ЩҮЩ…ШіШ§ШІЩҮШ§ Щ…ШӘЩҒШ§ЩҲШӘ Ш§ШіШӘ ШҜЩҲ ШөЩҲШӘ ЫҢЪ©ШіШ§ЩҶ ЩҶЫҢШіШӘЩҶШҜ ЩҲ ЪҜЩҒШӘЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ Ъ©ЩҮ Ш·ЩҶЫҢЩҶ ШҜЩҲ ШөЩҲШӘ Щ…ШӘЩҒШ§ЩҲШӘ Ш§ШіШӘ  ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыҙ вҖ“ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ЩҲЫҢЩҲЩ„ЩҶ. ЩҲЫҢЩҲЩ„ЩҶ Щ…ЩҲШ¬ ШҜЩҶШҜШ§ЩҶЩҮвҖҢШ§ШұЩҮвҖҢШ§ЫҢ Ш§ЫҢШ¬Ш§ШҜ Щ…ЫҢвҖҢЪ©ЩҶШҜ (ШҙЪ©Щ„ a)ШҢ ШөШҜШ§ЫҢ ШҜШұЫҢШ§ЩҒШӘ ШҙШҜЩҮ ШҙШ§Щ…Щ„ ЩҒШұЪ©Ш§ЩҶШі Ш§ШіШ§ШіЫҢ ЩҲ ЩҮЩ…ШіШ§ШІЩҮШ§ЫҢ ШўЩҶ Ш§ШіШӘ (ШҙЪ©Щ„ b) Ш§ШәЩ„ШЁ ЪҜЩҒШӘЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ Ъ©ЩҮ Ш·ЩҶЫҢЩҶ ШөШҜШ§ Ш§ШІ ШұЩҲЫҢ ШҙЪ©Щ„ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ШӘШ№ЫҢЫҢЩҶ Щ…ЫҢвҖҢЪҜШұШҜШҜ. Ш§ЫҢЩҶ Щ…ШіШЈЩ„ЩҮ ШҜШұШіШӘ Ш§ШіШӘ ЩҲЩ„ЫҢ Ъ©Щ…ЫҢ ЪҜЩ…ШұШ§ЩҮ Ъ©ЩҶЩҶШҜЩҮ Ш§ШіШӘ. Ш§ШӯШіШ§Ші Ш·ЩҶЫҢЩҶ ШөШҜШ§ Ш§ШІ ШұЩҲЫҢ Щ…ЫҢШІШ§ЩҶ ЩҮШ§ШұЩ…ЩҲЩҶЫҢЪ©ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ШҜШ§ШҜЩҮ ШҙШҜЩҮ ШӘЩҲШіШ· ЪҜЩҲШҙ ШӘШ№ЫҢЫҢЩҶ Щ…ЫҢвҖҢЪҜШұШҜШҜ. ШҜШұ ШӯШ§Щ„ЫҢ Ъ©ЩҮ ЩҮШ§ШұЩ…ЩҲЩҶЫҢЪ©ЩҮШ§ Ш§ШІ ШұЩҲЫҢ ШҙЪ©Щ„ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ШӘШ№ЫҢЫҢЩҶ Щ…ЫҢвҖҢЪҜШұШҜШҜ Ш№ШҜЩ… ШӯШіШ§ШіЫҢШӘ ЪҜЩҲШҙ ШЁЩҮ ЩҒШ§ШІ ШұШ§ШЁШ·ЩҮ ШұШ§ ШЁШіЫҢШ§Шұ ЫҢЪ© Ш·ШұЩҒЩҮ Щ…ЫҢвҖҢЪ©ЩҶШҜ. ШЁЩҮ ЩҮЩ…ЫҢЩҶ ШҜЩ„ЫҢЩ„ ЩҮШұ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ЩҒЩӮШ· ЫҢЪ© Ш·ЩҶЫҢЩҶ ШҜШ§ШұШҜ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ ЫҢЪ© ШІЩҶЪҜ Ш®Ш§Шө Щ…ШӘШ№Щ„ЩӮ ШЁЩҮ ШӘШ№ШҜШ§ШҜ ШЁЫҢвҖҢЩҶЩҮШ§ЫҢШӘЫҢ Ш§ШІ Щ…ЩҲШ¬ЩҮШ§ЫҢ ШөЩҲШӘЫҢ Ш§ШіШӘ. ЪҜЩҲШҙ ШЁЫҢШҙШӘШұ ШЁШұШ§ЫҢ ШҙЩҶЫҢШҜЩҶ ЩҮШ§ШұЩ…ЩҲЩҶЫҢЪ©ЩҮШ§ЫҢ Ш§ШіШ§ШіЫҢ ШӘЩҶШёЫҢЩ… ШҙШҜЩҮ Ш§ШіШӘ. Ш§ЪҜШұ ЫҢЪ© ШҙЩҶЩҲЩҶШҜЩҮ ШЁЩҮ ШөШҜШ§ЫҢЫҢ Ъ©ЩҮ ШӯШ§ШөЩ„ ШӘШұЪ©ЫҢШЁ ШҜЩҲ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ШіЫҢЩҶЩҲШіЫҢ Ыұ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ЩҲ Ыі Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ Ш§ШіШӘ ЪҜЩҲШҙ ШҜЩҮШҜ ШўЩҶ ШұШ§ Щ…Ш·Щ„ЩҲШЁ ЩҲ Ш·ШЁЫҢШ№ЫҢ ШӘЩҲШөЫҢЩҒ Ш®ЩҲШ§ЩҮШҜ Ъ©ШұШҜ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ Ш§ЪҜШұ Ш§ШІ Щ…ЩҲШ¬ЩҮШ§ЫҢ Ыұ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІЫҢ ЩҲ Ыі.Ыұ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІЫҢ Ш§ШіШӘЩҒШ§ШҜЩҮ ШҙЩҲШҜ ШЁШұШ§ЫҢ ШҙЩҶЩҲЩҶШҜЩҮ ШҙЪ©Ш§ЫҢШӘ ШЁШұШ§ЩҶЪҜЫҢШІ Ш®ЩҲШ§ЩҮШҜ ШЁЩҲШҜ. Ш§ЫҢЩҶ Щ…ШіШЈЩ„ЩҮ Ш§ШіШ§ШіЫҢ ШЁШұШ§ЫҢ Ш§ЩҶШҜШ§ШІЩҮвҖҢЩҮШ§ ЩҲ Ш§Ш®ШӘЩ„Ш§ЩҒЩҮШ§ЫҢ Ш§ШіШӘШ§ЩҶШҜШ§ШұШҜ Ш§ШЁШІШ§ШұЩҮШ§ЫҢ Щ…ЩҲШіЫҢЩӮЫҢШ§ЫҢЫҢ ЩҒШұШ§ЩҮЩ… Щ…ЫҢвҖҢШўЩҲШұШҜ. Ыі- ШұЩҲШҙЩҮШ§ЫҢ ШҜЫҢШ¬ЫҢШӘШ§Щ„ЫҢ Ш°Ш®ЫҢШұЩҮвҖҢЫҢ ШөШҜШ§ ШҜШұ Ш·ШұШ§ШӯЫҢ ЫҢЪ© ШіЫҢШіШӘЩ… ШөЩҲШӘЫҢ ШҜЫҢШ¬ЫҢШӘШ§Щ„ ШҜЩҲ ЩҫШұШіШҙ ЩҲШ¬ЩҲШҜ ШҜШ§ШұЩҶШҜ Ъ©ЩҮ ШЁШ§ЫҢШҜ ЩҫШ§ШіШ® ШҜШ§ШҜЩҮ ШҙЩҲЩҶШҜ: Ыұ- ЪҶЩӮШҜШұ Щ„Ш§ШІЩ… Ш§ШіШӘ ШөЩҲШӘ Ш®ЩҲШЁ ШЁЩҮ ЩҶШёШұ ШЁШұШіШҜШҹ ЫІ- ЪҶЩҮ ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢШ§ЫҢ ЩӮШ§ШЁЩ„ ШӘШӯЩ…Щ„ Ш§ШіШӘШҹ Ш¬ЩҲШ§ШЁ ШЁЩҮ Ш§ЫҢЩҶ ЩҫШұШіШҙЩҮШ§ ШәШ§Щ„ШЁШ§ЩӢ ШЁЩҮ ЫҢЪ©ЫҢ Ш§ШІ Ш§ЫҢЩҶ ШіЩҮ Ш§ЩҶШӘШ®Ш§ШЁ Щ…ЩҶШ¬Шұ Щ…ЫҢвҖҢШҙЩҲШҜ: Ш§ЩҲЩ„ Щ…ЩҲШіЫҢЩӮЫҢ ШЁШ§ ЩҲЩҒШ§ШҜШ§ШұЫҢ ШЁШ§Щ„Ш§ЫұЫҙ Ъ©ЩҮ ШҜШұ ШўЩҶ Ъ©ЫҢЩҒЫҢШӘ ШөШҜШ§ Щ…ЩҮЩ…вҖҢШӘШұЫҢЩҶ ЪҶЫҢШІ Ш§ШіШӘ ЩҲ ШӘЩӮШұЫҢШЁШ§ЩӢ ЩҮШұ ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢШ§ЫҢ ЩӮШ§ШЁЩ„ ЩӮШЁЩҲЩ„ Ш§ШіШӘ. ШҜЩҲЩ… Ш§ШұШӘШЁШ§Ш· ШӘЩ„ЩҒЩҶЫҢЫұЫө Ъ©ЩҮ ЩҶЫҢШ§ШІЩ…ЩҶШҜ Ш·ШЁЫҢШ№ЫҢ ШЁЩҮ ЩҶШёШұ ШұШіЫҢШҜЩҶ ШөШӯШЁШӘ ЩҲ ЫҢЪ© ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢЫҢ ЩҫШ§ЫҢЫҢЩҶ ШЁШұШ§ЫҢ Ъ©Ш§ЩҮШҙ ЩҮШІЫҢЩҶЩҮвҖҢЫҢ ШіЫҢШіШӘЩ… Ш§ШіШӘ. ШіЩҲЩ… ШөШӯШЁШӘ ЩҒШҙШұШҜЩҮ ШҙШҜЩҮЫұЫ¶ Ъ©ЩҮ ШҜШұ ШўЩҶ Ъ©Ш§ЩҮШҙ ЩҶШұШ® ШҜШ§ШҜЩҮ ШЁШіЫҢШ§Шұ Щ…ЩҮЩ… Ш§ШіШӘ ЩҲ Щ…ЩӮШҜШ§ШұЫҢ ШәЫҢШұ Ш·ШЁЫҢШ№ЫҢ ШЁЩҮ ЩҶШёШұ ШұШіЫҢШҜЩҶ Ъ©ЫҢЩҒЫҢШӘ ШөШҜШ§ ЩӮШ§ШЁЩ„ ШӘШӯЩ…Щ„ Ш§ШіШӘ. Ш§ЫҢЩҶ Щ…ЩҲШұШҜ ШҜШұ ШЁШұ ШҜШ§ШұЩҶШҜЩҮвҖҢЫҢ Ш§ШұШӘШЁШ§Ш·Ш§ШӘ ЩҶШёШ§Щ…ЫҢШҢ ШӘЩ„ЩҒЩҶЩҮШ§ЫҢ ШіЩ„ЩҲЩ„ЫҢ ЩҲ ШөШӯШЁШӘ Ш°Ш®ЫҢШұЩҮ ШҙШҜЩҮ ШЁЩҮ ШөЩҲШұШӘ ШҜЫҢШ¬ЫҢШӘШ§Щ„ ШЁШұШ§ЫҢ ЩҫШіШӘ Ш§Щ„Ъ©ШӘШұЩҲЩҶЫҢЪ©ЫҢ ШөЩҲШӘЫҢ ЫҢШ§ Ъ©Ш§ШұШЁШұШҜЩҮШ§ЫҢ ЪҶЩҶШҜ ШұШіШ§ЩҶЩҮвҖҢШ§ЫҢ Ш§ШіШӘ. ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыө ШЁШҜЩҮ ШЁШіШӘШ§ЩҶЩҮШ§ЫҢ Щ…ЩҲШ¬ЩҲШҜ ШҜШұ Ш§ЩҶШӘШ®Ш§ШЁ ЩҮШұ ЫҢЪ© Ш§ШІ Ш§ЫҢЩҶ ШіЩҮ ШұЩҲШҙ ШұШ§ ЩҶШҙШ§ЩҶ Щ…ЫҢвҖҢШҜЩҮШҜ. ШҜШұ ШӯШ§Щ„ЫҢ Ъ©ЩҮ Щ…ЩҲШіЫҢЩӮЫҢ ЩҶЫҢШ§ШІЩ…ЩҶШҜ ЩҫЩҮЩҶШ§ЫҢ ШЁШ§ЩҶШҜ ЫІЫ° Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ Ш§ШіШӘ ШөШӯШЁШӘЫҢ Ъ©ЩҮ Ш·ШЁЫҢШ№ЫҢ ШЁЩҮ ЩҶШёШұ ШЁШұШіШҜ ЩҒЩӮШ· ШЁЩҮ ЩҫЩҮЩҶШ§ЫҢ ШЁШ§ЩҶШҜЫҢ ШҜШұ ШӯШҜЩҲШҜ Ыі.ЫІ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ЩҶЫҢШ§ШІЩ…ЩҶШҜ Ш§ШіШӘ. ШҜШұ Ш§ЫҢЩҶ ШӯШ§Щ„ ЩҮШұ ЪҶЩҶШҜ ЩҫЩҮЩҶШ§ЫҢ ШЁШ§ЩҶШҜ ШЁЩҮ Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ ЫұЫ¶% Щ…ЩӮШҜШ§Шұ Ш§ЩҲЩ„ЫҢЩҮ Щ…ШӯШҜЩҲШҜ Щ…ЫҢвҖҢШҙЩҲШҜ ЩҲЩ„ЫҢ ЩҒЩӮШ· ЫІЫ°% Ш§Ш·Щ„Ш§Ш№Ш§ШӘ Ш§ЩҲЩ„ЫҢЩҮ Ш§ШІ ШҜШіШӘ Щ…ЫҢвҖҢШұЩҲШҜ. ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ Ш§ШұШӘШЁШ§Ш· ШұШ§ЩҮвҖҢШҜЩҲШұ Ш§ШәЩ„ШЁ Ш§ШІ ЩҶШұШ® ЩҶЩ…ЩҲЩҶЩҮвҖҢШЁШұШҜШ§ШұЫҢ ШҜШұ ШӯШҜЩҲШҜ Ыё Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ Ъ©ЩҮ Ш§Ш¬Ш§ШІЩҮвҖҢЫҢ Ш§ЩҶШӘЩӮШ§Щ„ ШөШӯШЁШӘ ШұШ§ ШЁШ§ Ъ©ЫҢЩҒЫҢШӘЫҢ ШҜШұ ШӯШҜ Ш·ШЁЫҢШ№ЫҢ Щ…ЫҢвҖҢШҜЩҮШҜ ЩҲЩ„ЫҢ Ш§ЪҜШұ Ш§ШІ ШўЩҶ ШЁШұШ§ЫҢ Ш§ЩҶШӘЩӮШ§Щ„ Щ…ЩҲШіЫҢЩӮЫҢ Ш§ШіШӘЩҒШ§ШҜЩҮ ШҙЩҲШҜ ШӘШ§ Щ…ЫҢШІШ§ЩҶ ШЁШ§Щ„Ш§ЫҢЫҢ Ш§ШІ Ъ©ЫҢЩҒЫҢШӘ ШўЩҶ Ш§ШІ ШҜШіШӘ Щ…ЫҢвҖҢШұЩҲШҜ. ШҙЩ…Ш§ Ш§ШӯШӘЩ…Ш§Щ„Ш§ЩӢ ШЁШ§ ШӘЩҒШ§ЩҲШӘ Ш§ЫҢЩҶ ШҜЩҲ Щ…ЫҢШІШ§ЩҶ ШўШҙЩҶШ§ЫҢЫҢ ШҜШ§ШұЫҢШҜ: Ш§ЫҢШіШӘЪҜШ§ЩҮЩҮШ§ЫҢ ШұШ§ШҜЫҢЩҲЫҢЫҢ Ш§ЩҒ.Ш§Щ… ШЁШ§ ЩҫЩҮЩҶШ§ЫҢ ШЁШ§ЩҶШҜЫҢ ШҜШұ ШӯШҜЩҲШҜ ЫІЫ° Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ Ш§ЩӮШҜШ§Щ… ШЁЩҮ ЩҫШ®Шҙ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ Ш§ЫҢШіШӘЪҜШ§ЩҮЩҮШ§ЫҢ Ш§ЫҢ.Ш§Щ… Щ…ШӯШҜЩҲШҜ ШЁЩҮ Ыі.ЫІ Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ЩҮШіШӘЩҶШҜ. ШөШӯШЁШӘ ЩҲ ШөШҜШ§ЩҮШ§ЫҢ Щ…Ш№Щ…ЩҲЩ„ ШұЩҲЫҢ Ш§ЫҢШіШӘЪҜШ§ЩҮЩҮШ§ЫҢ ЩҶЩҲШ№ ШҜЩҲЩ… Ш·ШЁЫҢШ№ЫҢ ШЁЩҮ ЩҶШёШұ Щ…ЫҢвҖҢШұШіШҜ ШӯШ§Щ„ ШўЩҶ Ъ©ЩҮ Щ…ЩҲШіЫҢЩӮЫҢ Ш§ЫҢЩҶ ЪҜЩҲЩҶЩҮ ЩҶЫҢШіШӘ.  ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮ Ыө - ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢЫҢ ШөЩҲШӘЫҢ ШҜШұ ШЁШұШ§ШЁШұ Ъ©ЫҢЩҒЫҢШӘ ШөШҜШ§. Ъ©ЫҢЩҒЫҢШӘ ШөШҜШ§ЫҢ ЫҢЪ© ШіЫҢЪҜЩҶШ§Щ„ ШөЩҲШӘЫҢ ШҜЫҢШ¬ЫҢШӘШ§Щ„ ШЁЩҮ ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢЫҢ ШўЩҶ Ъ©ЩҮ ШЁШұШ§ШЁШұ ШЁШ§ ШӯШ§ШөЩ„вҖҢШ¶ШұШЁ ЩҶШұШ® ЩҶЩ…ЩҲЩҶЩҮвҖҢШЁШұШҜШ§ШұЫҢ ШўЩҶ ШҜШұ ШӘШ№ШҜШ§ШҜ ШЁЫҢШӘЩҮШ§ЫҢ ШўЩҶ ШҜШұ ЩҮШұ ЩҶЩ…ЩҲЩҶЩҮ ШЁШіШӘЪҜЫҢ ШҜШ§ШұШҜ Ъ©ЩҮ ШЁЩҮ ШіЩҮ ШЁШ®Шҙ ШӘЩӮШіЫҢЩ… Щ…ЫҢвҖҢШҙЩҲШҜ: Щ…ЩҲШіЫҢЩӮЫҢ ШЁШ§ЩҲЩҒШ§ШҜШ§ШұЫҢ ШЁШ§Щ„Ш§ (Ы·Ы°Ы¶Ъ©ЫҢЩ„ЩҲШЁЫҢШӘ ШЁШұ Ш«Ш§ЩҶЫҢЩҮ)ШҢ ШөШӯШЁШӘ ШЁШ§ Ъ©ЫҢЩҒЫҢШӘ ШӘЩ„ЩҒЩҶ (Ы¶ЫҙЪ©ЫҢЩ„ЩҲШЁЫҢШӘ ШЁШұ Ш«Ш§ЩҶЫҢЩҮ) ЩҲШөШӯШЁШӘ ЩҒШҙШұШҜЩҮ ШҙШҜЩҮ (Ыҙ Ъ©ЫҢЩ„ЩҲШЁЫҢШӘ ШЁШұ Ш«Ш§ЩҶЫҢЩҮ) ШіЫҢШіШӘЩ…ЩҮШ§ЫҢЫҢ Ъ©ЩҮ ЩҒЩӮШ· ШЁШ§ ШөШҜШ§ (ЩҲ ЩҶЩҮ Щ…ЩҲШіЫҢЩӮЫҢ) ШіШұ ЩҲ Ъ©Ш§Шұ ШҜШ§ШұЩҶШҜ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶЩҶШҜ Щ…ЩӮШҜШ§Шұ ШҜЩӮШӘ ШұШ§ Ш§ШІ ЫұЫ¶ ШЁЫҢШӘ ШЁЩҮ ЫұЫІ ШЁЫҢШӘ ШЁШҜЩҲЩҶ Ш§ШІ ШҜШіШӘ ШұЩҒШӘЩҶ ШҜЩӮШӘЫҢ ЩӮШ§ШЁЩ„ ШӘЩҲШ¬ЩҮ Ъ©Ш§ЩҮШҙ ШҜЩҮЩҶШҜ. Ш§ЫҢЩҶ Щ…ЫҢШІШ§ЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ШЁШ§ Ш§ЩҶШӘШ®Ш§ШЁ Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ ЩҶШ§Щ…ШӘШіШ§ЩҲЫҢ ШЁШұШ§ЫҢ ЪҜШ§Щ… Щ…ЩӮШҜШ§ШұЪҜШІЫҢЩҶЫҢЫұЫ· Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ШЁЩҮ Ыё ШЁЫҢШӘ ШҜШұ ЩҮШұ ЩҶЩ…ЩҲЩҶЩҮ ЩҶЫҢШІ Ъ©Ш§ЩҮШҙ ЫҢШ§ШЁШҜ. ЫҢЪ© ЩҶШұШ® ЩҶЩ…ЩҲЩҶЩҮвҖҢШЁШұШҜШ§ШұЫҢ Ыё Ъ©ЫҢЩ„ЩҲЩҮШұШӘШІ ШЁШ§ ШҜЩӮШӘ Ш§ЫҢ.ШҜЫҢ.ШіЫҢ Ыё ШЁЫҢШӘ ШҜШұ ЩҮШұ ЩҶЩ…ЩҲЩҶЩҮ ШЁЩҮ ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢЫҢ Ы¶ЫҙЪ©ЫҢЩ„ЩҲШЁЫҢШӘ ШЁШұ Ш«Ш§ЩҶЫҢЩҮ Щ…ЫҢвҖҢШ§ЩҶШ¬Ш§Щ…ШҜ. Ш§ЫҢЩҶ ЫҢЪ© ШӯШҜ ЩҶЩҮШ§ЫҢЫҢ ШЁШұШ§ЫҢ Ш·ШЁЫҢШ№ЫҢ ШЁЩҮ ЩҶШёШұ ШұШіЫҢШҜЩҶ ШөШӯШЁШӘ Ш§ШіШӘ. ШҜЩӮШӘ Ъ©ЩҶЫҢШҜ Ъ©ЩҮ ШөШӯШЁШӘ ЩҶЫҢШ§ШІЩ…ЩҶШҜ ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢШ§ЫҢ Щ…Ш№Ш§ШҜЩ„ ЫұЫ°% ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢЫҢ Щ…ЩҲШіЫҢЩӮЫҢ ШЁШ§ ЩҲЩҒШ§ШҜШ§ШұЫҢ ШЁШ§Щ„Ш§ШіШӘ. ЩҶШұШ® ШҜШ§ШҜЩҮвҖҢЫҢ Ы¶Ыҙ Ъ©ЫҢЩ„ЩҲ ШЁЫҢШӘ ШЁШұ Ш«Ш§ЩҶЫҢЩҮ ЩҶЩ…Ш§ЫҢШ§ЩҶЪҜШұ Ъ©Ш§ШұШЁШұШҜ ЩҶЩҮШ§ЫҢЫҢ ЩҶШёШұЫҢЩҮвҖҢЫҢ ЩҶЩ…ЩҲЩҶЩҮвҖҢШЁШұШҜШ§ШұЫҢ ЩҲ Щ…ЩӮШҜШ§ШұЪҜШІЫҢЩҶЫҢ ШЁШұШ§ЫҢ ШіЫҢЪҜЩҶШ§Щ„ЩҮШ§ЫҢ ШөЩҲШӘЫҢ Ш§ШіШӘ. ШұЩҲШҙЩҮШ§ЫҢ Ъ©Ш§ЩҮШҙ ЩҶШұШ® ШҜШ§ШҜЩҮ ШЁЩҮ Ш§ЩҶШҜШ§ШІЩҮвҖҢШ§ЫҢ ШЁЫҢШҙШӘШұ Ш§ШІ Ш§ЫҢЩҶ Щ…ШЁШӘЩҶЫҢ ШЁШұ ЩҒШҙШұШҜЩҮвҖҢШіШ§ШІЫҢ Ш¬ШұЫҢШ§ЩҶ ШҜШ§ШҜЩҮ ШЁШ§ ШӯШ°ЩҒ ШӘЪ©ШұШ§ШұЩҮШ§ЫҢ Ш°Ш§ШӘЫҢ ШіЫҢЪҜЩҶШ§Щ„ ШөШӯШЁШӘ Ш§ШіШӘ. ЫҢЪ©ЫҢ Ш§ШІ Ъ©Ш§ШұШ§ШӘШұЫҢЩҶ ШұЩҲШҙЩҮШ§ЫҢ Щ…ЩҲШ¬ЩҲШҜ Ш§Щ„.ЩҫЫҢ.ШіЫҢЫұЫё Ш§ШіШӘ Ъ©ЩҮ Ш§ЩҶЩҲШ§Ш№ ЩҲ ШІЫҢШұЪҜШұЩҲЩҮЩҮШ§ЫҢ Щ…ШӘШ№ШҜШҜ ШҜШ§ШұШҜ. ШЁШұ Ш§ШіШ§Ші Ъ©ЫҢЩҒЫҢШӘ ШіЫҢЪҜЩҶШ§Щ„ ШөШӯШЁШӘ Щ…ЩҲШұШҜ ЩҶЫҢШ§ШІ Ш§ЫҢЩҶ ШұЩҲШҙ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ЩҶШұШ® ШҜШ§ШҜЩҮ ШұШ§ ШӘШ§ Ш§ЩҶШҜШ§ШІЩҮвҖҢШ§ЫҢ ШЁЫҢЩҶ ЫІ ШӘШ§ Ы¶ Ъ©ЫҢЩ„ЩҲ ШЁЫҢШӘ ШЁШұ Ш«Ш§ЩҶЫҢЩҮ Ъ©Ш§ЩҮШҙ ШҜЩҮШҜ
__________________
 ЩҲЩҠШұШ§ЩҠШҙ ШҙШҜЩҮ ШӘЩҲШіШ· Astaraki; Ы°ЫІ-ЫұЫұ-ЫұЫіЫ№Ы° ШҜШұ ШіШ§Ш№ШӘ Ы°Ы·:ЫіЫҙ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ |

|

|

| Ш§ШІ Astaraki ШӘШҙЩғШұ ЩғШұШҜЩҮ Ш§ЩҶШҜ: | aliowaysee (Ы°Ыё-ЫұЫ·-ЫұЫіЫ№Ыө), pedram021 (ЫұЫұ-ЫІЫё-ЫұЫіЫ№Ы°) |
| #ADS | |
|
ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ ШӘШЁЩ„ЫҢШәШ§ШӘ
ШӘШЁЩ„ЩҠШәЪҜШұ
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: -
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: -
ШіЩҶ: 2010
ЩҫШіШӘ ЩҮШ§: -
|
|

|
|
Ы°Ы№-ЫұЫ·-ЫұЫіЫёЫё, Ы°Ыұ:ЫҙЫұ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#2 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Administrator
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш®ШұШҜШ§ШҜ ЫұЫіЫёЫ·
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ-Ъ©ШұШ¬!
ЩҫШіШӘ ЩҮШ§: 3,465
ШӘШҙЩғШұЩҮШ§: 754
16,339 ШӘШҙЩғШұ ШҜШұ 3,127 ЩҫШіШӘ
My Mood:
|
ЩҫШұШҜШ§ШІШҙ ШөШҜШ§
ШӘШҙШ®ЫҢШө ШөШҜШ§ ЫҢШ§ ШҙЩҶШ§ШіШ§ЫҢЫҢ ЪҜЩҲЫҢЩҶШҜЩҮ(Speaker Identification) ЫҢЪ©ЫҢ Ш§ШІ Щ…ШіШ§ЫҢЩ„ Ш№Щ„ЩҲЩ… ШұШ§ЫҢШ§ЩҶЩҮвҖҢ ЩҲ ЩҮЩҲШҙ Щ…ШөЩҶЩҲШ№ЫҢ Ш§ШіШӘ Ъ©ЩҮ ЩҮШҜЩҒ ШўЩҶ ШҙЩҶШ§ШіШ§ЫҢЫҢ ЫҢЪ© ЩҒШұШҜ ШӘЩҶЩҮШ§ Ш§ШІ ШұЩҲЫҢ ШөШҜШ§ЫҢ ШҙШ®Шө Ш§ШіШӘ. ЫҢЪ©ЫҢ Ш§ШІ Ш§ШөЩ„ЫҢвҖҢШӘШұЫҢЩҶ Ш§ШЁШІШ§ШұЩҮШ§ЫҢ ШұЫҢШ§Ш¶ЫҢ ШЁШұШ§ЫҢ ШӯЩ„ Ш§ЫҢЩҶ Щ…ШіЫҢЩ„ЩҮ Щ…ШҜЩ„ЩҮШ§ЫҢ ЩҫЩҶЩҮШ§ЩҶ Щ…Ш§ШұЪ©ЩҲЩҒ ЩҮШіШӘЩҶШҜ. ШЁШұШ§ЫҢ ШӯЩ„ Ш§ЫҢЩҶ Щ…ШіШҰЩ„ЩҮ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Щ…ШҜЩ„ ЩҫЩҶЩҮШ§ЩҶ Щ…Ш§ШұЪ©ЩҲЩҒ (Щ….Щҫ.Щ…) Ш§ЫҢЩҶ Щ…ШҜЩ„ЩҮШ§ЫҢ ШўЩ…Ш§ШұЫҢ Ш§ШЁШӘШҜШ§ ШЁШ§ЫҢШҜ Щ…ЩҲШұШҜ ШўЩ…ЩҲШІШҙ ЩӮШұШ§Шұ ШЁЪҜЫҢШұЩҶШҜ. ШЁШұШ§ЫҢ Ш§ЫҢЩҶ Щ…ШұШӯЩ„ЩҮ Ш§ШЁШӘШҜШ§ Щ…ЩӮШҜШ§Шұ ЩӮШ§ШЁЩ„ ШӘЩҲШ¬ЩҮЫҢ Ш§ШІ ШөШҜШ§ЫҢ Ш¶ШЁШ· ШҙШҜЩҮ Ш§ЩҒШұШ§ШҜ ЩҫШұШҜШ§ШІШҙ Щ…ЫҢвҖҢШҙЩҲШҜ. ШҜШ§ШҜЩҮвҖҢЩҮШ§ЫҢ ЩҫШұШҜШ§ШІШҙ ШҙШҜЩҮ Ъ©ЩҮ ШҜШұ ШӯЩӮЫҢЩӮЫҢШӘ Щ…Ш¬Щ…ЩҲШ№ЩҮ Ш№ШёЫҢЩ…ЫҢ Ш§ШІ Ш§Ш№ШҜШ§ШҜ Щ…ЫҢвҖҢвҖҢШЁШ§ШҙЩҶШҜ Щ…ШӘЩҶШ§ЩҲШЁШ§ЩӢ Щ…ЩҲШұШҜ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩӮШұШ§Шұ Щ…ЫҢЪҜЫҢШұЩҶШҜ ШӘШ§ Щ….Щҫ.Щ…. ШЁШұШ§ЫҢ ЩҮШұ ЪҜЩҲЫҢЩҶШҜЩҮ ШЁЩҮ ШҜШіШӘ ШўЫҢШҜ. ШҜШұ ШӯЩӮЫҢЩӮШӘ Щ….Щҫ.Щ….вҖҢЩҮШ§ Щ…Ш§ЩҶЩҶШҜ ЫҢЪ© Щ…Ш§ШҙЫҢЩҶ Ш№Щ…Щ„ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ Ъ©ЩҮ ЩҲШұЩҲШҜЫҢ ШўЩҶЩҮШ§ ЫҢЪ© ШіШұЫҢ ШҜШ§ШҜЩҮ Ш§ШіШӘ ЩҲ Ш®ШұЩҲШ¬ЫҢШҙШ§ЩҶ ЫҢЪ© Ш№ШҜШҜ ШЁШұШ§ЫҢ ЩҮШұ Щ…Ш¬Щ…ЩҲШ№ЩҮвҖҢШ§ЫҢ Ш§ШІ ШҜШ§ШҜЩҮвҖҢЩҮШ§ШҢ ШЁЩҮ Ш§ЫҢЩҶ ШөЩҲШұШӘ Ъ©ЩҮ ШўЩҶ Ш№ШҜШҜ ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ Ш§Ш®ШӘЩ„Ш§ЩҒ ШҜШ§ШҜЩҮвҖҢЩҮШ§ЫҢ ЩҲШұЩҲШҜЫҢ ШЁШ§ Щ….Щҫ.Щ… ЩҮШұ Щ…Ш§ШҙЫҢЩҶ Ш§ШіШӘ. ШЁШұШ§ЫҢ ШўЩ…ЩҲШІШҙ Щ….Щҫ.Щ… ШҜШұ ЩҮШұ ШӘЩҶШ§ЩҲШЁ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ШЁЩҮ Щ….Щҫ.Щ… ШҜШ§ШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ ЩҲ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЫҢ Щ….Щҫ.Щ… Ш°ШұЩҮвҖҢШ§ЫҢ ШӘШәЫҢЫҢШұ ШҜШ§ШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ ШӘШ§ Ш№ШҜШҜ Ш®ШұЩҲШ¬ЫҢ (Ъ©ЩҮ ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ Ш§Ш®ШӘЩ„Ш§ЩҒ ШҜШ§ШҜЩҮвҖҢЩҮШ§ ШЁШ§ Щ….Щҫ.Щ… Ш§ШіШӘ) Ъ©ЩҲЪҶЪ©ШӘШұ ШҙЩҲШҜ. ШЁШұШ§ЫҢ Ш§Ш·Щ…ЫҢЩҶШ§ЩҶ Ш§ШІ Ш§ЫҢЩҶЪ©ЩҮ ШӘШәЫҢЫҢШұ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЫҢ Щ….Щҫ.Щ… ШҜШұ Ш¬ЩҮШӘ ШҜШұШіШӘ Ш§ЩҶШ¬Ш§Щ… Щ…ЫҢвҖҢЪҜЫҢШұШҜ ЩҲ ЩҶЩҮШ§ЫҢШӘШ§ ШЁЩҮ ШӯШҜШ§ЩӮЩ„ ШҙШҜЩҶ Ш№ШҜШҜ Ш®ШұЩҲШ¬ЫҢ Щ…ЫҢвҖҢШ§ЩҶШ¬Ш§Щ…ШҜ Ш§ШІ ЫҢЪ© ШұЩҲШҙ ШұЫҢШ§Ш¶ЫҢ ШЁЩҮ ЩҶШ§Щ… Expectation Maximization Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ШҜШұ ЩҶЩҮШ§ЫҢШӘ ШЁШ№ШҜ Ш§ШІ ШўЩ…ЩҲШІШҙ Ш§ЫҢЩҶ Щ…ШҜЩ„ЩҮШ§ Ъ©ЩҮ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШөШҜШ§ЫҢ Щ…ШұШ¬Ш№ Ш§ЩҶШ¬Ш§Щ… ШҙШҜЩҮШҢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ ШЁШұШ§ЫҢ ШўШІЩ…Ш§ЫҢШҙ ШіШ§Щ…Ш§ЩҶЩҮ ШөШҜШ§ЫҢ ЫҢЪ©ЫҢ Ш§ШІ Ш§ЩҒШұШ§ШҜЫҢ Ъ©ЩҮ ЩӮШЁЩ„Ш§ Ш§ШІ ШөШҜШ§ЫҢ ЩҲЫҢ ШЁШұШ§ЫҢ ШўЩ…ЩҲШІШҙ Щ….Щҫ.Щ… Ш§ШіШӘЩҒШ§ШҜЩҮ ШҙШҜЩҮ ШұШ§ ШЁЩҮ ЩҮШұ ЫҢЪ© Ш§ШІ Щ….Щҫ.Щ…вҖҢЩҮШ§ ШҜШ§ШҜ. Щ….Щҫ.Щ…вҖҢШ§ЫҢ Ъ©ЩҮ Ъ©ЩҲЪҶЪ©ШӘШұЫҢЩҶ Ш№ШҜШҜ ШұШ§ ШӘЩҲЩ„ЫҢШҜ Щ…ЫҢвҖҢЪ©ЩҶШҜ ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҒШұШҜ ШҙЩҶШ§ШіШ§ЫҢЫҢ ШҙШҜЩҮ ШҜШұ ЩҶШёШұ ЪҜШұЩҒШӘЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. ШіШ§Щ…Ш§ЩҶЩҮ ШЁШ§Щ„Ш§ ШЁЩҮ ШҜЩ„Ш§ЫҢЩ„ Щ…Ш®ШӘЩ„ЩҒЫҢ Ш§ШӯШӘЩ…Ш§Щ„ Ш®Ш·Ш§ ШҜШ§ШұШҜ. ШҙШЁШ§ЩҮШӘ ШөШҜШ§ЫҢ Ш§ЩҒШұШ§ШҜ ШЁЩҮ ЫҢЪ©ШҜЫҢЪҜШұ (Ъ©ЩҮ ЪҜШ§ЩҮЫҢ Ш§ЩҶШіШ§ЩҶЩҮШ§ ШұШ§ ЩҶЫҢШІ ШЁЩҮ Ш§ШҙШӘШЁШ§ЩҮ Щ…ЫҢвҖҢвҖҢШ§ЩҶШҜШ§ШІШҜ)ШҢ ШөШҜШ§ЩҮШ§ЫҢ ШӯШ§ШҙЫҢЩҮ (ЩҶЩҲЫҢШІ)ШҢ Щ…ШӯШҜЩҲШҜЫҢШӘ ШӯШ¬Щ… ШҜШ§ШҜЩҮвҖҢЩҮШ§ЫҢ Щ…ШұШ¬Ш№ ШЁШұШ§ЫҢ ШўЩ…ЩҲШІШҙ ЩҲ ШәЫҢШұЩҮ Ш§ШІ Ш¬Щ…Щ„ЩҮ Ш§ЫҢЩҶ Ш§ШҙШӘШЁШ§ЩҮвҖҢЩҮШ§ ЩҮШіШӘЩҶШҜ. ШЁШұШ§ЫҢ ШЁШ§Щ„Ш§ ШЁШұШҜЩҶ Ш¶ШұЫҢШЁ Ш§Ш·Щ…ЫҢЩҶШ§ЩҶ ШіШ§Щ…Ш§ЩҶЩҮ ШҙЩҶШ§ШіШ§ЫҢЫҢ ЪҜЩҲЫҢЩҶШҜЩҮ ШұЩҲШҙЩҮШ§ЫҢ Щ…Ш®ШӘЩ„ЩҒЫҢ ШЁЪ©Ш§Шұ Щ…ЫҢвҖҢШұЩҲШҜ Ъ©ЩҮ ЩҮШұ ШіШ§Щ„ЩҮ ЩҶЫҢШІ ШЁШ§ ЩҫЫҢШҙШұЩҒШӘ ШӘШӯЩӮЫҢЩӮШ§ШӘ ШҜШұ ШҜЩҶЫҢШ§ ШЁЩҮ ШўЩҶЩҮШ§ Ш§Ш¶Ш§ЩҒЩҮ Щ…ЫҢвҖҢШҙЩҲШҜ. 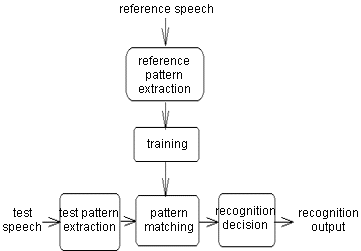 Ш§ШІ Ш¬Щ…Щ„ЩҮ Ш§ШіШӘЩҒШ§ШҜЩҮ ШӘШұЪ©ЫҢШЁЫҢ Ш§ШІ ШӘШҙШ®ЫҢШө ЪҜЩҒШӘШ§Шұ ЩҲ ШӘШҙШ®ЫҢШө ШөШҜШ§ Ъ©ЩҮ ШҜШұ ШўЩҶ ЩҶЩҮ ШӘЩҶЩҮШ§ ШөШҜШ§ЫҢ ЪҜЩҲЫҢЩҶШҜЩҮ ШЁЩ„Ъ©ЩҮ Ъ©Щ„Щ…ЩҮ(ЩҮШ§ЫҢ) ЩҲЫҢ ЩҶЫҢШІ Щ…ЩҲШұШҜ ШўШІЩ…Ш§ЫҢШҙ ЩӮШұШ§Шұ Щ…ЫҢвҖҢЪҜЫҢШұЩҶШҜ. ЪҜЩҲЫҢЩҶШҜЩҮ ШЁШ§ЫҢШҜ Ъ©Щ„Щ…Ш§ШӘ Щ…ШҙШ®ШөЫҢ ШұШ§ ШЁЪ©Ш§Шұ ШЁШЁШұШҜ ШӘШ§ ШіШ§Щ…Ш§ЩҶЩҮ ШЁЩҮ ЩҲЫҢ Ш§Ш¬Ш§ШІЩҮ Ш№ШЁЩҲШұ ШЁШҜЩҮШҜ. ЩҮЩ…ЪҶЩҶЫҢЩҶ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ Ш§ШІ ЫҢЪ© Ш№ШҜШҜ ШӯШҜШ§Ъ©Ш«Шұ ШЁШұШ§ЫҢ Щ…ЩӮШ§ЫҢШіЩҮ Ш§Ш№ШҜШ§ШҜ Ш®ШұЩҲШ¬ЫҢ Щ….Щҫ.Щ… Ш§ШіШӘЩҒШ§ШҜЩҮ Ъ©ШұШҜ ШЁШ·ЩҲШұЫҢ Ъ©ЩҮ Щ….Щҫ.Щ… Щ…ЩҲШұШҜ ЩҶШёШұ ЩҶЩҮ ШӘЩҶЩҮШ§ ШЁШ§ЫҢШҜ Ъ©ЩҲЪҶЪ©ШӘШұЫҢЩҶ Ш№ШҜШҜ ШұШ§ ШЁШҜЩҮШҜ ШЁЩ„Ъ©ЩҮ ШЁШ§ЫҢШҜ Ш§ЫҢЩҶ Ш№ШҜШҜ Ш§ШІ ЫҢЪ© Ш№ШҜШҜ Щ…ШұШ¬Ш№ ЩҶЫҢШІ Ъ©ЩҲЪҶЪ©ШӘШұ ШЁШ§ШҙШҜ. ШҜШұ ЩҶШӘЫҢШ¬ЩҮ Ш§ЫҢЩҶ ШӘШәЫҢЫҢШұ ШҜШұ ШіШ§Щ…Ш§ЩҶЩҮ Ш¶ШұЫҢШЁ Ш§ЫҢЩ…ЩҶЫҢ ШіШ§Щ…Ш§ЩҶЩҮ ШЁШ§Щ„Ш§ Щ…ЫҢвҖҢШұЩҲШҜ. Ш§ЫҢЩҶ Ш¶ШұЫҢШЁ Ш§ЫҢЩ…ЩҶЫҢ ШЁЩҮ ЩӮЫҢЩ…ШӘ ШЁШ§Щ„Ш§ ШұЩҒШӘЩҶ ШҜШұШөШҜ ШұШҜЩ‘ Ш§ЩҒШұШ§ШҜ Ш§ШІ ШұЩҲЫҢ Ш®Ш·Ш§ ШөЩҲШұШӘ Щ…ЫҢвҖҢЪҜЫҢШұШҜ ЩҲ ШЁШ§Ш№Ш« Щ…ЫҢвҖҢШҙЩҲШҜ ШҙШ®ШөЫҢ Ъ©ЩҮ ШЁЩҮ Ш§ЩҲ ШЁШ§ЫҢШҜ Ш§Ш¬Ш§ШІЩҮ Ш№ШЁЩҲШұ ШҜШ§ШҜЩҮ ШҙЩҲШҜ ЪҶЩҶШҜ ШЁШ§Шұ ШұЩ…ШІ Ш®ЩҲШҜ ШұШ§ ШЁШұШ§ЫҢ ШіШ§Щ…Ш§ЩҶЩҮ ШӘЪ©ШұШ§Шұ Ъ©ЩҶШҜ. Щ…Ш§ЩҶЩҶШҜ ШӘЩ…Ш§Щ… ШіШ§Щ…Ш§ЩҶЩҮвҖҢЩҮШ§ЫҢЫҢ ШЁЩҮЫҢЩҶЩҮвҖҢШіШ§ШІЫҢ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЫҢ Щ…Ш®ШӘЩ„ЩҒ ШЁШұШ§ЫҢ ШЁЩҮШӘШұЫҢЩҶ Ш№Щ…Щ„Ъ©ШұШҜ ШіШ§Щ…Ш§ЩҶЩҮ ШҜШұ ШҙШұШ§ЫҢШ· Щ…ЩҲШұШҜ ЩҶЫҢШ§ШІ Щ„Ш§ШІЩ… Ш§ШіШӘ. (ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ Щ…Ш«Ш§Щ„ ШҜШұ ЩҲШұЩҲШҜЫҢ Ш§ШӘШ§ЩӮ Ъ©ЩҶШӘШұЩ„ ЫҢЪ© ЩҶЫҢШұЩҲЪҜШ§ЩҮ ЩҮШіШӘЩҮвҖҢШ§ЫҢ ЩҶЫҢШ§ШІ ШЁЩҮ ШӯЩҒШ§ШёШӘ ШІЫҢШ§ШҜЫҢ ШҜШ§ШұШҜ Ъ©ЩҮ Щ…Щ…Ъ©ЩҶ Ш§ШіШӘ ШҜШұ Щ…ЩҲШұШҜ ШҜШұШЁ ЩҲШұЩҲШҜЫҢ Ъ©ШӘШ§ШЁШ®Ш§ЩҶЩҮ ШҜШ§ЩҶШҙЪҜШ§ЩҮ ЩҶЫҢШ§ШІ ЩҶШЁШ§ШҙШҜ.) |
|
|
|
| Ш§ШІ Astaraki ШӘШҙЩғШұ ЩғШұШҜЩҮ Ш§ШіШӘ: | pedram021 (ЫұЫұ-ЫІЫё-ЫұЫіЫ№Ы°) |
|
Ы°ЫІ-ЫұЫұ-ЫұЫіЫ№Ы°, Ы°Ыө:ЫіЫё ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#3 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Ш№Ш¶ЩҲ ЩҒШ№Ш§Щ„
 
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ЩҒШұЩҲШұШҜЩҠЩҶ ЫұЫіЫ№Ы°
ЩҫШіШӘ ЩҮШ§: 11
ШӘШҙЩғШұЩҮШ§: 7
7 ШӘШҙЩғШұ ШҜШұ 4 ЩҫШіШӘ
|
ШЁШ§ ШіЩ„Ш§Щ…
Ш®ЫҢЩ„ЫҢ Щ…Щ…ЩҶЩҲЩҶ Щ„Ш·ЩҒШ§ ШҙЪ©Щ„ ЩҮШ§ЫҢЫҢ Ъ©ЩҮ ШҜШұЩ…ЩӮШ§Щ„ЩҮ ЩҮШіШӘЩҶШҜ ЩҮЩ… ШЁЪҜШ°Ш§ШұЫҢШҜ |
|
|
|

|
Ы°ЫІ-ЫұЫұ-ЫұЫіЫ№Ы°, Ы°Ы·:ЫіЫө ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#4 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) | |
|
Administrator
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш®ШұШҜШ§ШҜ ЫұЫіЫёЫ·
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ-Ъ©ШұШ¬!
ЩҫШіШӘ ЩҮШ§: 3,465
ШӘШҙЩғШұЩҮШ§: 754
16,339 ШӘШҙЩғШұ ШҜШұ 3,127 ЩҫШіШӘ
My Mood:
|
ЩҶЩӮЩ„ ЩӮЩҲЩ„:

|
|
|
|
|

| Ш§ШІ Astaraki ШӘШҙЩғШұ ЩғШұШҜЩҮ Ш§ЩҶШҜ: |
|
Ы°Ыі-ЫұЫұ-ЫұЫіЫ№Ыұ, Ы°Ыө:ЫұЫҙ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#5 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Ш№Ш¶ЩҲ Ш¬ШҜЫҢШҜ
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: ЩҒШұЩҲШұШҜЩҠЩҶ ЫұЫіЫ№Ыұ
ЩҫШіШӘ ЩҮШ§: 1
ШӘШҙЩғШұЩҮШ§: 0
0 ШӘШҙЩғШұ ШҜШұ 0 ЩҫШіШӘ
|
ШЁШ§ ШіЩ„Ш§Щ…
Щ…Щ…ЩҶЩҲЩҶ Ш§ШІ Щ…Ш·Ш§Щ„ШЁ Ш®ЩҲШЁШӘЩҲЩҶ Ш§ЪҜЩҮ ШұЩҲШҙ Ъ©Ш§Шұ ЩҫШұШҜШ§ШІШҙ ШөЩҲШӘ ШҜШұ Щ…ШӘЩ„ШЁ ШұЩҲ ЩҮЩ… ШЁШІШ§ШұЫҢЩҶ Щ…Щ…ЩҶЩҲЩҶ Щ…ЫҢШҙЩ… ЪҶЩҲЩҶ ШҙШҜЫҢШҜШ§ ШЁЩҮШҙ ЩҶЫҢШ§ШІ ШҜШ§ШұЩ… ШЁШ§ ШӘШҙЪ©Шұ |
|
|
|
|
«
ШҜШұШ®ЩҲШ§ШіШӘ Щ…ЩӮШ§Щ„ЩҮ ЩҠШ§ ЩҫШұЩҲЪҳЩҮ
|
ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҒШӘШ§ШұШҢвҖҢЪ©ЫҢ Ъ©Ш§Щ…Щ„Ш§ Ш№Щ…Щ„ЫҢ Щ…ЫҢШҙЩҲЩҶШҜШҹ
»
| ЩғШ§ШұШЁШұШ§ЩҶ ШҜШұ ШӯШ§Щ„ ШҜЩҠШҜЩҶ ШӘШ§ЩҫЩҠЪ©: 1 (0 Ш№Ш¶ЩҲ ЩҲ 1 Щ…ЩҮЩ…Ш§ЩҶ) | |
 Linear Mode
Linear Mode

|
|

ШІЩ…Ш§ЩҶ Щ…ШӯЩ„ЩҠ ШҙЩ…Ш§ ШЁШ§ ШӘЩҶШёЩҠЩ… GMT +3.5 ЩҮЩ… Ш§Ъ©ЩҶЩҲЩҶ Ы°Ыұ:ЫұЫұ ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ Щ…ЩҠШЁШ§ШҙШҜ.





