Ш§ЩҶШ¬Щ…ЩҶ ШұШ§ ШҜШұ ЪҜЩҲЪҜЩ„ Щ…ШӯШЁЩҲШЁ Ъ©ЩҶЩҠШҜ :
|
|||||||


| Ш«ШЁШӘ ЩҶШ§Щ… | Ш§ШұШіШ§Щ„ ШҜШ№ЩҲШӘЩҶШ§Щ…ЩҮ ШЁЩҮ ШҜЩҲШіШӘШ§ЩҶ ! | ШұШ§ЩҮЩҶЩ…Ш§ЩҠ ШіШ§ЩҠШӘ | Community | ШӘЩӮЩҲЩҠЩ… | Ш§ШұШіШ§Щ„ЩҮШ§ЩҠ Ш§Щ…ШұЩҲШІ | Ш¬ШіШӘШ¬ЩҲ |
| ШӘШЁЩ„ЩҠШәШ§ШӘ ШіШ§ЩҠШӘ | |||||||||||||||||||||||||||||||||||
  |
|
|
LinkBack | Ш§ШЁШІШ§ШұЩҮШ§ЩҠ ШӘШ§ЩҫЩҠЪ© | ЩҶШӯЩҲЩҮ ЩҶЩ…Ш§ЩҠШҙ |
 Ы°Ыө-ЫұЫё-ЫұЫіЫёЫ№, Ы°Ыі:ЫөЫ¶ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
Ы°Ыө-ЫұЫё-ЫұЫіЫёЫ№, Ы°Ыі:ЫөЫ¶ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#1 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Administrator
 
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш®ШұШҜШ§ШҜ ЫұЫіЫёЫ·
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: ШӘЩҮШұШ§ЩҶ-Ъ©ШұШ¬!
ЩҫШіШӘ ЩҮШ§: 3,465
ШӘШҙЩғШұЩҮШ§: 754
16,339 ШӘШҙЩғШұ ШҜШұ 3,127 ЩҫШіШӘ
My Mood:

 |
Ыұ- ШӘШ№ШұЫҢЩҒ ЩҲ Ъ©Ш§ШұШЁШұШҜЩҮШ§
ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮЫұ Ш№ШЁШ§ШұШӘ Ш§ШіШӘ Ш§ШІ ЩҒШұШ§ЫҢЩҶШҜ ШӘШҙШ®ЫҢШө Ш®ЩҲШҜЪ©Ш§Шұ ЩҮЩҲЫҢШӘ ШҙШ®Шө ШөШӯШЁШӘвҖҢЪ©ЩҶЩҶШҜЩҮ ШЁШұ Ш§ШіШ§Ші Ш§Ш·Щ„Ш§Ш№Ш§ШӘ ЫҢЪ©ШӘШ§ЫҢ Щ…ЩҲШ¬ЩҲШҜ ШҜШұ Щ…ЩҲШ¬ ШөЩҲШӘЫҢ ШөШӯШЁШӘ Ш§ЩҲ. Ш§ЫҢЩҶ ЩҒЩҶвҖҢШўЩҲШұЫҢ Ш§Щ…Ъ©Ш§ЩҶ ШӘШҙШ®ЫҢШө ЩҮЩҲЫҢШӘ ШҙШ®Шө ЪҜЩҲЫҢЩҶШҜЩҮ ЩҲ ШҜШұ ЩҶШӘЫҢШ¬ЩҮ Ш§Щ…Ъ©Ш§ЩҶ Ъ©ЩҶШӘШұЩ„ ШҜШіШӘШұШіЫҢ Ш§ЩҲ ШҜШұ ЩҮЩҶЪҜШ§Щ… Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Ш®ШҜЩ…Ш§ШӘЫҢ ЩҮЩ…Ш§ЩҶЩҶШҜ ШҙЩ…Ш§ШұЩҮвҖҢЪҜЫҢШұЫҢ ШөЩҲШӘЫҢШҢ ШЁШ§ЩҶЪ©ШҜШ§ШұЫҢ ШӘЩ„ЩҒЩҶЫҢШҢ Ш®ШұЫҢШҜ ШӘЩ„ЩҒЩҶЫҢШҢ Ш®ШҜЩ…Ш§ШӘ ШҜШіШӘШұШіЫҢ ШЁЩҮ ЩҫШ§ЫҢЪҜШ§ЩҮ ШҜШ§ШҜЩҮвҖҢЩҮШ§ШҢ Ш®ШҜЩ…Ш§ШӘ Ш§Ш·Щ„Ш§Ш№Ш§ШӘЫҢШҢ ЩҫШіШӘ Ш§Щ„Ъ©ШӘШұЩҲЩҶЫҢЪ©ЫҢ ШөЩҲШӘЫҢШҢ Ъ©ЩҶШӘШұЩ„ Ш§Щ…ЩҶЫҢШӘЫҢ ШЁШұШ§ЫҢ ЩҲШұЩҲШҜ ШЁЩҮ ЩӮЩ„Щ…ШұЩҲЩҮШ§ЫҢ Ш§Ш·Щ„Ш§Ш№Ш§ШӘЫҢ Щ…ШӯШұЩ…Ш§ЩҶЩҮ ЩҲ ШҜШіШӘШұШіЫҢ Ш§ШІ ШұШ§ЩҮ ШҜЩҲШұ ШЁЩҮ Ъ©Ш§Щ…ЩҫЫҢЩҲШӘШұЩҮШ§ ШұШ§ ЩҒШұШ§ЩҮЩ… Щ…ЫҢвҖҢШўЩҲШұШҜ. Ш№Щ„Ш§ЩҲЩҮ ШЁШұ Щ…ЩҲШ§ШұШҜ ЩҒЩҲЩӮ Ъ©ЩҮ Ш№Щ…ЩҲЩ…Ш§ЩӢ ШЁШ§ Ъ©Ш§Щ…ЩҫЫҢЩҲШӘШұ ЩҲ Ъ©Ш§ШұШЁШұШ§ЩҶ ШўЩҶ ШіШұЩҲЪ©Ш§Шұ ШҜШ§ШұЩҶШҜ Ш§ЫҢЩҶ ЩҒЩҶвҖҢШўЩҲШұЫҢ ШҜШұ Щ…ШіШ§ШҰЩ„ ЩӮШ¶Ш§ЫҢЫҢ ЩҶЫҢШІ Ъ©Ш§ШұШЁШұШҜЩҮШ§ЫҢ Ш®Ш§Шө Ш®ЩҲШҜ ШұШ§ ШҜШ§ШұШҜ. ЫІ- Ш§ЩҶЩҲШ§Ш№ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮ Ш§ШІ Щ„ШӯШ§Шё ШұЩҲШҙ Ш§ШіШӘЩҒШ§ШҜЩҮШҢ ЩҮЩ…Ш§ЩҶЩҶШҜ ШўЩҶЪҶЩҮ ШЁШұШ§ЫҢ Ъ©Щ„ЫҢЩҮвҖҢЫҢ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ Ш§Щ…ЩҶЫҢШӘЫҢ Щ…ШЁШӘЩҶЫҢ ШЁШұ ШІЫҢШіШӘвҖҢШіЩҶШ¬ЫҢ ШҜШұ ЩҒШөЩ„ ЩҫЫҢШҙ ШЁЫҢШ§ЩҶ ШҙШҜШҢ Ш№Щ…ЩҲЩ…Ш§ЩӢ ШҜШұ ШҜЩҲ ШҜШіШӘЩҮвҖҢЫҢ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШЈЫҢЫҢШҜ ЩҮЩҲЫҢШӘ ЪҜЩҲЫҢЩҶШҜЩҮЫІ ЩҲ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШЁШ§ШІШҙЩҶШ§ШіЫҢ ЩҮЩҲЫҢШӘ ЪҜЩҲЫҢЩҶШҜЩҮЫі ЩӮШұШ§Шұ Щ…ЫҢвҖҢЪҜЫҢШұЩҶШҜ. ШҜШұ ЫҢЪ© ШіЫҢШіШӘЩ… ШӘШЈЫҢЫҢШҜ ЩҮЩҲЫҢШӘ ЪҜЩҲЫҢЩҶШҜЩҮШҢ ШҙШ®Шө Ш№Щ…ЩҲЩ…Ш§ЩӢ ШЁШ§ Ш§ЩҶШӘШ®Ш§ШЁ ЫҢШ§ ЩҲШ§ШұШҜ Ъ©ШұШҜЩҶ ЩҶШ§Щ… ЫҢЪ©ЫҢ Ш§ШІ Ъ©Ш§ШұШЁШұШ§ЩҶ Ш®Ш§Шө ШіЫҢШіШӘЩ… Ш§ШҜШ№Ш§ Щ…ЫҢвҖҢЪ©ЩҶШҜ Ъ©ЩҮ Ш§ЩҲ ЩҮЩ…Ш§ЩҶ Ъ©Ш§ШұШЁШұ Ш«ШЁШӘвҖҢШҙШҜЩҮвҖҢЫҢ ШіЫҢШіШӘЩ… Ш§ШіШӘ. ШҜШұ Ш§ЫҢЩҶ ШӯШ§Щ„ШӘ ШіЫҢШіШӘЩ… ЩҲШёЫҢЩҒЩҮ ШҜШ§ШұШҜ ЩҲЫҢЪҳЪҜЫҢЩҮШ§ЫҢ ШөЩҲШӘЫҢ ШҙШ®Шө Щ…ШҜШ№ЫҢ ШұШ§ ШЁШ§ ЩҲЫҢЪҳЪҜЫҢЩҮШ§ЫҢ ШөЩҲШӘЫҢ Ш°Ш®ЫҢШұЩҮ ШҙШҜЩҮвҖҢЫҢ Ъ©Ш§ШұШЁШұ Ш«ШЁШӘ ШҙШҜЩҮвҖҢЫҢ Щ…ЩҲШұШҜ Ш§ШҜШ№Ш§ Щ…ЩӮШ§ЫҢШіЩҮ ЩҶЩ…ЩҲШҜЩҮ ЩҲ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ЩҶШӘЫҢШ¬ЩҮвҖҢЫҢ ШЁЩҮ ШҜШіШӘ ШўЩ…ШҜЩҮ Ш§ШҜШ№Ш§ЫҢ ШҙШ®Шө ШұШ§ ШЁЩҫШ°ЫҢШұШҜ ЫҢШ§ ШұШҜ Ъ©ЩҶШҜ. ШҜШұ ЫҢЪ© ШіЫҢШіШӘЩ… ШЁШ§ШІШҙЩҶШ§ШіЫҢ ЩҮЩҲЫҢШӘ ЪҜЩҲЫҢЩҶШҜЩҮШҢ ШҙШ®Шө ШөШӯШЁШӘ Ъ©ЩҶЩҶШҜЩҮ Ш§ШҜШ№Ш§ЫҢ ЩҮЩҲЫҢШӘ ЫҢЪ© Ъ©Ш§ШұШЁШұ Ш®Ш§Шө Ш«ШЁШӘ ШҙШҜЩҮ ШұШ§ ЩҶЩ…ЫҢвҖҢЩҶЩ…Ш§ЫҢШҜ ЩҲ Ш§ЫҢЩҶ ШіЫҢШіШӘЩ… Ш§ШіШӘ Ъ©ЩҮ ЩҲШёЫҢЩҒЩҮ ШҜШ§ШұШҜ Ъ©ЩҮ Ш§ЩҲ ШұШ§ ШҜШұ Щ…ЫҢШ§ЩҶ Ъ©Ш§ШұШЁШұШ§ЩҶ Ш«ШЁШӘ ШҙШҜЩҮвҖҢЫҢ ШіЫҢШіШӘЩ… ШЁШ§ШІШҙЩҶШ§ШіЫҢ ЩҶЩ…Ш§ЫҢШҜ ЩҲ ЫҢШ§ ШӘШҙШ®ЫҢШө ШҜЩҮШҜ Ъ©ЩҮ ЩҲЫҢЪҳЪҜЫҢЩҮШ§ЫҢ ШөЩҲШӘЫҢ Ш§ЩҲ ШЁШ§ ЩҮЫҢЪҶ ЫҢЪ© Ш§ШІ Ъ©Ш§ШұШЁШұШ§ЩҶ Ш«ШЁШӘ ШҙШҜЩҮ ЩҮЩ…Ш®ЩҲШ§ЩҶЫҢ ЩҶШҜШ§ШұШҜ. ШЁЩҮ ЩҶШёШұ Щ…ЫҢвҖҢШұШіШҜ ШҜШұ ШўЫҢЩҶШҜЩҮ Ъ©Ш§ШұШЁШұШҜЩҮШ§ЫҢ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ЩҶЩҲШ№ ШҜЩҲЩ… ШҜШұ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШЁШІШұЪҜ ЪҶЩҶШҜ Ъ©Ш§ШұШЁШұЩҮ ЪҶШҙЩ…ЪҜЫҢШұШӘШұ Ш§ШІ Ъ©Ш§ШұШЁШұШҜЩҮШ§ЫҢ ШіЫҢШіШӘЩ… ЩҶЩҲШ№ Ш§ЩҲЩ„ ШЁШ§ШҙШҜШҢЫҙ ЩҮШұ ЪҶЩҶШҜ Ъ©ЩҮ ШҜШұ Ш§ШіШ§Ші Ш§ЫҢЩҶ ШҜЩҲ ШіЫҢШіШӘЩ… ШӘЩҒШ§ЩҲШӘЩҮШ§ЫҢ ЪҶШҙЩ…ЪҜЫҢШұЫҢ Щ…ШҙШ§ЩҮШҜЩҮ ЩҶЩ…ЫҢвҖҢШҙЩҲШҜ. ШҙЪ©Щ„ ШҙЩ…Ш§ШұЩҮвҖҢЫҢ 1 ШіШ§Ш®ШӘШ§Шұ Ш§ШіШ§ШіЫҢ Ш§ЫҢЩҶ ШҜЩҲ ЩҶЩҲШ№ ШіЫҢШіШӘЩ… ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮ ШұШ§ ШЁЩҮ ШӘШөЩҲЫҢШұ Щ…ЫҢвҖҢЪ©ШҙШҜ. 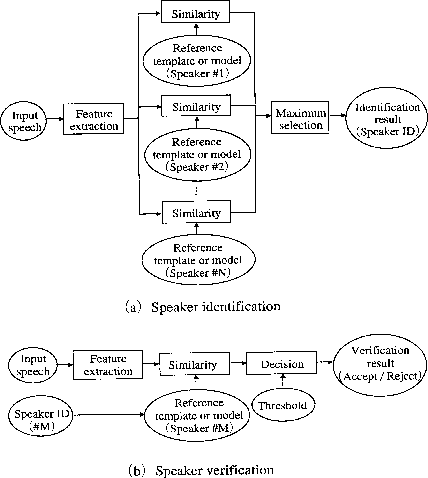 ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮ Ш§ШІ ШҜЫҢШҜЪҜШ§ЩҮ ШҜЫҢЪҜШұЫҢ ШЁЩҮ ШҜЩҲ ШҜШіШӘЩҮвҖҢЫҢ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮвҖҢЫҢ ЩҲШ§ШЁШіШӘЩҮ ШЁЩҮ Щ…ШӘЩҶЫө ЩҲ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮвҖҢЫҢ Щ…ШіШӘЩӮЩ„ Ш§ШІ Щ…ШӘЩҶЫ¶ ШӘЩӮШіЫҢЩ… Щ…ЫҢвҖҢШҙЩҲЩҶШҜ. ШұЩҲШҙ Ш§ЩҲЩ„ ЩҶЫҢШ§ШІЩ…ЩҶШҜ ШўЩҶ Ш§ШіШӘ Ъ©ЩҮ ЪҜЩҲЫҢЩҶШҜЩҮ Ъ©Щ„Щ…Ш§ШӘ Ъ©Щ„ЫҢШҜЫҢ ЫҢШ§ Ш¬Щ…Щ„ЩҮвҖҢЩҮШ§ЫҢ Ш«Ш§ШЁШӘЫҢ ШұШ§ ЪҶЩҮ ШҜШұ Щ…ШұШӯЩ„ЩҮвҖҢЫҢ ЫҢШ§ШҜЪҜЫҢШұЫҢ ЩҲ ЪҶЩҮ ШҜШұ ШўШІЩ…ЩҲЩҶЩҮШ§ЫҢ ШӘШҙШ®ЫҢШөЫҢ ШЁЫҢШ§ЩҶ Ъ©ЩҶШҜШҢ ШҜШұ ШӯШ§Щ„ЫҢ Ъ©ЩҮ ШҜЩҲЩ…ЫҢ ЩҲШ§ШЁШіШӘЩҮ ШЁЩҮ Ш¬Щ…Щ„ЩҮ ЫҢШ§ Ъ©Щ„Щ…ЩҮвҖҢЫҢ Ш®Ш§ШөЫҢ ЩҶЫҢШіШӘ. ЩҮШұ ШҜЩҲ ШұЩҲШҙ ШҜШ§ШұШ§ЫҢ ЫҢЪ© Щ…ШҙЪ©Щ„ ЩҮШіШӘЩҶШҜ ЩҲ ШўЩҶ Ш§ЫҢЩҶ Ш§ШіШӘ Ъ©ЩҮ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ Ш§ШІ ШөШҜШ§ЫҢ Ш¶ШЁШ· ШҙШҜЩҮвҖҢЫҢ Ъ©Ш§ШұШЁШұШ§ЩҶ Ш«ШЁШӘвҖҢШҙШҜЩҮ ШЁШұШ§ЫҢ ЩҲШұЩҲШҜ ШЁЩҮ ШіЫҢШіШӘЩ… Ш§ШіШӘЩҒШ§ШҜЩҮ ЩҶЩ…ЩҲШҜ ЩҲ ШЁЩҮ ШўШіШ§ЩҶЫҢ ШіЫҢШіШӘЩ… ШұШ§ ЩҒШұЫҢШЁ ШҜШ§ШҜ. ШЁШұШ§ЫҢ ШәЩ„ШЁЩҮ ШЁШұ Ш§ЫҢЩҶ Щ…ШҙЪ©Щ„ ШұЩҲШҙЩҮШ§ЫҢЫҢ ЩҲШ¬ЩҲШҜ ШҜШ§ШұЩҶШҜ Щ…Ш«Щ„Ш§ЩӢ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ Ш§ШІ ЫҢЪ© Щ…Ш¬Щ…ЩҲШ№ЩҮвҖҢЫҢ Ъ©ЩҲЪҶЪ© Ш§ШІ Ъ©Щ„Щ…Ш§ШӘ Щ…Ш§ЩҶЩҶШҜ Ш§ШұЩӮШ§Щ… ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ Ъ©Щ„Щ…Ш§ШӘ Ъ©Щ„ЫҢШҜЫҢ Ш§ШіШӘЩҒШ§ШҜЩҮ ЩҶЩ…ЩҲШҜ ЩҲ ШҜШұ ЩҮШұ ШІЩ…Ш§ЩҶ ШЁЩҮ ШөЩҲШұШӘ ШӘШөШ§ШҜЩҒЫҢ Ш§ШІ Ъ©Ш§ШұШЁШұ Ш®ЩҲШ§ШіШӘ Ъ©ЩҮ ЫҢЪ© ШҜЩҶШЁШ§Щ„ЩҮ Ш§ШІ ШўЩҶЩҮШ§ ШұШ§ ШЁЫҢШ§ЩҶ Ъ©ЩҶШҜ. ШӯШӘЫҢ Ш§ЫҢЩҶ ШұЩҲШҙ ЩҮЩ… Ъ©Ш§Щ…Щ„Ш§ЩӢ ЩӮШ§ШЁЩ„ Ш§Ш·Щ…ЫҢЩҶШ§ЩҶ ЩҶЫҢШіШӘ ЪҶШұШ§ Ъ©ЩҮ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶШҜ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШӘШ¬ЩҮЫҢШІШ§ШӘ ЩҫЫҢШҙШұЩҒШӘЩҮвҖҢЫҢ Ш§Щ„Ъ©ШӘШұЩҲЩҶЫҢЪ©ЫҢ Ъ©ЩҮ ШӘЩҲШ§ЩҶШ§ЫҢЫҢ ШӘЩҲЩ„ЫҢШҜ ШҜЩҶШЁШ§Щ„ЩҮвҖҢЩҮШ§ЫҢ Ш№ШЁШ§ШұШ§ШӘ ШұШ§ ШҜШ§ШұЩҶШҜ ЩҒШұЫҢШЁ ШҜШ§ШҜЩҮ ШҙЩҲШҜ. ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШҜШ§ШұШ§ЫҢ ШіШ§Ш®ШӘШ§Шұ Ш§Ш®ЫҢШұ ШЁЩҮ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮвҖҢЫҢ Ш§Ш№Щ„Ш§ЩҶ Щ…ШӘЩҶЫ· (Щ…ШӘЩҶ ШӘЩҲЩ„ЫҢШҜ ШҙШҜЩҮ ШӘЩҲШіШ· Щ…Ш§ШҙЫҢЩҶ) Щ…Ш№ШұЩҲЩҒЩҶШҜ. Ыі- ШұЩҲШҙЩҮШ§ЫҢ ЩҫЫҢШ§ШҜЩҮвҖҢШіШ§ШІЫҢ ШӘЩӮШұЫҢШЁШ§ЩӢ ШҜШұ ШӘЩ…Ш§Щ…ЫҢ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЩҮЩҲЫҢШӘ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ЩҒШұШ§ЫҢЩҶШҜЫҢ Ъ©ЩҮ ШЁЩҮ ШӘШҙШ®ЫҢШө Ш§Щ„ЪҜЩҲЫё ШҙЩҮШұШӘ ШҜШ§ШұШҜ ШҙШЁШ§ЩҮШӘ ЩҮШұ ШІЩҲШ¬ ЩҶЩ…ЩҲЩҶЩҮвҖҢ ЩҶЩ…ШұЩҮвҖҢЪҜШ°Ш§ШұЫҢ Щ…ЫҢвҖҢШҙЩҲШҜ. Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ Ш§ЫҢЩҶ ШұЩҲШҙ ЩҶЫҢШ§ШІЩ…ЩҶШҜ ЩҲШ¬ЩҲШҜ ШҜШіШӘЩҮвҖҢШ§ЫҢ Ш§ШІ Ш®ШөШ§ЫҢШө Щ…ЩҶШӯШөШұ ШЁЩҮ ЩҒШұШҜ ЩҲ ЩӮШ§ШЁЩ„ Щ…ЩӮШ§ЫҢШіЩҮ Ъ©ЩҮ Ш§ШІ ЩҲЫҢЪҳЪҜЫҢ Ш§ЩҶШӘШ®Ш§ШЁ ШҙШҜЩҮ ШЁЩҮ Ш№ЩҶЩҲШ§ЩҶ ЩҲШұЩҲШҜЫҢ ШіЫҢШіШӘЩ… Ш§ШіШӘШ®ШұШ§Ш¬ ШҙШҜЩҮ Щ…ЫҢвҖҢШЁШ§ШҙШҜ. ЩҲЫҢЪҳЪҜЫҢЩҮШ§ЫҢ ЩҒЫҢШІЫҢЪ©ЫҢ Ш§ЩҒШұШ§ШҜ ЩҶШёЫҢШұ ШіШ§Ш®ШӘШ§Шұ Ш§ЩҶШҜШ§Щ…ЩҮШ§ЫҢ ШөЩҲШӘЫҢШҢ Ш§ЩҶШҜШ§ШІЩҮвҖҢЫҢ ЪҶШ§Щ„ЩҮвҖҢЫҢ ШЁЫҢЩҶЫҢ ЩҲ ЩҲЫҢЪҳЪҜЫҢЩҮШ§ЫҢ ШӘШ§ШұЩҮШ§ЫҢ ШөЩҲШӘЫҢ Щ…ЩҶШӯШөШұ ШЁЩҮ ЩҒШұШҜ ШЁЩҲШҜЩҮ ЩҲ Ш§ШІ Ш·ШұЫҢЩӮ Ш§Щ„ЪҜЩҲШұЫҢШӘЩ…ЩҮШ§ЫҢ ЩҫШұШҜШ§ШІШҙ ШіЫҢЪҜЩҶШ§Щ„ ШЁЩҮ ШөЩҲШұШӘ ЩҫШ§ШұШ§Щ…ШӘШұЩҮШ§ЫҢ Ш®ШөЫҢШөЩҮвҖҢШ§ЫҢЫ№ ЫҢШ§ Щ…Ш¬Щ…ЩҲШ№ЩҮвҖҢЫҢ Ш®ШөШ§ЫҢШөЫұЫ° ЩӮШ§ШЁЩ„ Ш§ШіШӘШ®ШұШ§Ш¬ Щ…ЫҢвҖҢШЁШ§ШҙЩҶШҜ. Ш§ЫҢЩҶ ШӯЩӮЫҢЩӮШӘ ЩҫШ§ЫҢЩҮвҖҢЫҢ ШұЩҲШҙЩҮШ§ЫҢ ЩҫЫҢШ§ШҜЩҮвҖҢШіШ§ШІЫҢ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ШөШӯШЁШӘ Щ…ЫҢвҖҢШЁШ§ШҙЩҶШҜ. Щ…ЩҮЩ…ШӘШұЫҢЩҶ ЪҜЩ„ЩҲЪҜШ§ЩҮ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ЪҜЩҲЫҢЩҶШҜЩҮ (ЩҲ ШЁЩҮ ШӘШЁШ№ ЩҮЩ… Ш®Ш§ЩҶЩҲШ§ШҜЩҮ ШЁЩҲШҜЩҶ Щ…ЩҮЩ…ШӘШұЫҢЩҶ ЪҜЩ„ЩҲЪҜШ§ЩҮ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШҙШ®ЫҢШө ШөШӯШЁШӘ) ЩҶШӯЩҲЩҮвҖҢЫҢ Ш№Щ…Щ„Ъ©ШұШҜ ШўЩҶЩҮШ§ ШҜШұ Щ…Ъ©Ш§ЩҶЩҮШ§ЫҢ ШҜШ§ШұШ§ЫҢ ШҙШұШ§ЫҢШ· Щ…ШӘЩҒШ§ЩҲШӘ ШЁШ§ ШҙШұШ§ЫҢШ· ШўШІЩ…Ш§ЫҢШҙЪҜШ§ЩҮЫҢ Ъ©ЩҮ Ш§ШІ ЩҲЫҢЪҳЪҜЫҢЩҮШ§ЫҢ Ш№Щ…ШҜЩҮвҖҢЫҢ ШўЩҶЩҮШ§ Щ…ЫҢвҖҢШӘЩҲШ§ЩҶ ШЁЩҮ ШӯШ¶ЩҲШұ ЩҶЩҲЫҢШІ ШҜШұ ШіЫҢШіШӘЩ… Ш§ШҙШ§ШұЩҮ Ъ©ШұШҜ Щ…ЫҢвҖҢШЁШ§ШҙШҜ. ШЁШұШ§ЫҢ ШәЩ„ШЁЩҮ ШЁШұ Ш§ЫҢЩҶ Щ…ШҙЪ©Щ„ Ш§ШІ ШұЩҲШҙЩҮШ§ЫҢ ЩҮЩҶШ¬Ш§ШұШіШ§ШІЫҢЫұЫұ Ш§ШіШӘЩҒШ§ШҜЩҮ Щ…ЫҢвҖҢЪҜШұШҜШҜ Ъ©ЩҮ Ш§ЫҢЩҶ ШұЩҲШҙЩҮШ§ ЩҶЫҢШІ Ш§ЩҶЩҲШ§Ш№ Щ…Ш®ШӘЩ„ЩҒЫҢ ШҜШ§ШұЩҶШҜ ЩҲ ШҜШұ ШіЫҢШіШӘЩ…ЩҮШ§ЫҢ ШӘШ¬Ш§ШұЫҢ Щ…ЩҲШ¬ЩҲШҜШҢ Ш§ШәЩ„ШЁ ЩҶЩ…ЩҲШҜ ЩҫЫҢШҜШ§ Щ…ЫҢвҖҢЪ©ЩҶЩҶШҜ. Ыҙ- Щ…ЩҶШ§ШЁШ№ ЩҒШөЩ„ 1) Sadaoki Furui, NTT Human Interface Laboratories, Tokyo, Japan, Speaker Recognition, from clsu.cs.ogj.edu 2) Martin Cultenbruner, Audiotry User Interfaces for Desktop, Mobile and Embeded Applications 3) Richard Duncan, Mississipi State University, A Description And Comparison Of The Feature Sets Used In Speech Processing *speaker recognition *speaker verification systems *speaker identification systems *Ш§ЫҢЩҶ Ш№ЩӮЫҢШҜЩҮШҢ ЩҶШёШұ Щ…ЩҶШЁШ№ ШҙЩ…Ш§ШұЩҮвҖҢЫҢ ЫІ Ш§ШіШӘ [Шұ.Ъ©. ШөЩҒШӯЩҮвҖҢЫҢ 19 ШўЩҶ Щ…ЩҶШЁШ№] *text-dependent speaker recognition systems *text-independent speaker recognition systems *text-prompted speaker recognition systems *pattern recognition *feature parameters *feature set *normalization |

|

|


| #ADS | |
|
ЩҶШҙШ§ЩҶ ШҜЩҮЩҶШҜЩҮ ШӘШЁЩ„ЫҢШәШ§ШӘ
ШӘШЁЩ„ЩҠШәЪҜШұ
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: -
Щ…ШӯЩ„ ШіЩғЩҲЩҶШӘ: -
ШіЩҶ: 2010
ЩҫШіШӘ ЩҮШ§: -
|
|

|
|
Ы°ЫІ-ЫІЫІ-ЫұЫіЫ№Ы°, Ы°Ы·:Ы°Ы¶ ШЁШ№ШҜ Ш§ШІ ШёЩҮШұ
|
#2 (Щ„ЫҢЩҶЪ© ШҜШ§ШҰЩ…) |
|
Ш№Ш¶ЩҲ Ш¬ШҜЫҢШҜ
 
ШӘШ§ШұЩҠШ® Ш№Ш¶ЩҲЩҠШӘ: Ш§ШұШҜЩҠШЁЩҮШҙШӘ ЫұЫіЫ№Ы°
ЩҫШіШӘ ЩҮШ§: 4
ШӘШҙЩғШұЩҮШ§: 12
0 ШӘШҙЩғШұ ШҜШұ 0 ЩҫШіШӘ
|
Ш§ШҜЩ…ЫҢЩҶ Ш№ШІЫҢШІ Щ…Ш§ Щ…ШҙЪ©Щ„Щ…ЩҲЩҶ ШҙШЁЫҢЩҮ ШіШ§ШІЫҢ Ш§ЫҢЩҶ ШіЫҢШіШӘЩ…ЩҮ ЩҶЩҮ ШЁШӯШ« ШӘШҰЩҲШұЫҢ
|
|
|
|

|
«
ШӘШҙШ®ЩҠШө Ш¬ЩҶШіЩҠШӘ Ш¬ЩҮШӘ Ш§ЩҒШІШ§ЩҠШҙ ШіШұШ№ШӘ ШіЩҠШіШӘЩ… ЩҮШ§ЩҠ ШӘШҙШ®ЩҠШө ЪҜЩҲЩҠЩҶШҜЩҮ
|
ШӘШҙШ®ЫҢШө Ш¬ЩҶШіЫҢШӘ ЪҜЩҲЫҢЩҶШҜЩҮ ШЁШ§ Ш§ШіШӘЩҒШ§ШҜЩҮ Ш§ШІ ШҙШЁЪ©ЩҮ Ш№ШөШЁЫҢ
»
| ЩғШ§ШұШЁШұШ§ЩҶ ШҜШұ ШӯШ§Щ„ ШҜЩҠШҜЩҶ ШӘШ§ЩҫЩҠЪ©: 1 (0 Ш№Ш¶ЩҲ ЩҲ 1 Щ…ЩҮЩ…Ш§ЩҶ) | |
 Linear Mode
Linear Mode

|
|

ШІЩ…Ш§ЩҶ Щ…ШӯЩ„ЩҠ ШҙЩ…Ш§ ШЁШ§ ШӘЩҶШёЩҠЩ… GMT +3.5 ЩҮЩ… Ш§Ъ©ЩҶЩҲЩҶ ЫұЫІ:ЫІЫұ ЩӮШЁЩ„ Ш§ШІ ШёЩҮШұ Щ…ЩҠШЁШ§ШҙШҜ.





